MySQL 事务的实现
概述
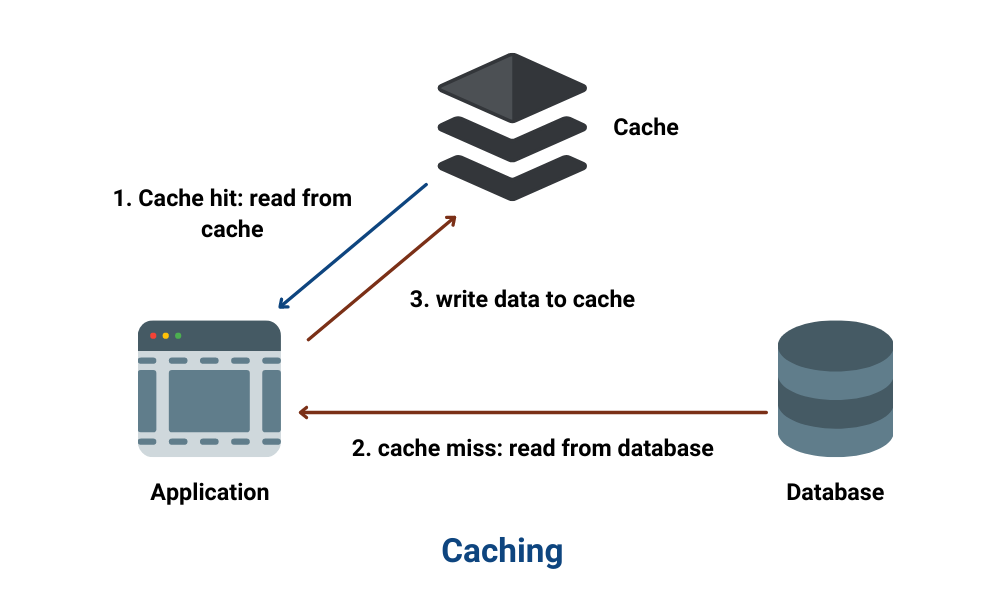
图来自极客时间的mysql实践,该图是描述的是MySQL的逻辑架构。
我们知道事务的四大特性ACID(原子性、一致性、隔离性、持久性)
其中事务的隔离性由MySQL的锁来进行实现,而原子性、一致性、持久性通过数据库的redo log和undo log来完成。redo log称为重做日志,用来保证事务的原子性和持久性。undo log用来保证事务的一致性。
redo和undo的作用都可以视为是一种恢复操作,而不是一般的逆过程。redo恢复提交事务修改的页操作,而undo回滚行记录到某个特定版本。因此两者记录到内容不同,redo通常是物理日志,记录的是页的物理修改操作。undo是逻辑日志,根据每行记录进行记录。
binlog是属于MySQL Server层面的,又称为归档日志,属于逻辑日志,是以二进制的形式记录的是这个语句的原始逻辑,依靠binlog是没有crash-safe能力的。
假设数据库在操作时,按如下约定记录日志:
1 | 1. 事务开始时,记录START T |
redo log日志模块
redo log是InnoDB存储引擎层的日志,又称重做日志文件,用于记录事务操作的变化,记录的是数据修改之后的值,不管事务是否提交都会记录下来。在实例和介质失败(media failure)时,redo log文件就能派上用场,如数据库掉电,InnoDB存储引擎会使用redo log恢复到掉电前的时刻,以此来保证数据的完整性。
在一条更新语句进行执行的时候,InnoDB引擎会把更新记录写到redo log日志中,然后更新内存,此时算是语句执行完了,然后在空闲的时候或者是按照设定的更新策略将redo log中的内容更新到磁盘中,这里涉及到WAL即Write Ahead logging技术,他的关键点是先写日志,再写磁盘。
有了redo log日志,那么在数据库进行异常重启的时候,可以根据redo log日志进行恢复,也就达到了crash-safe。
redo log日志的大小是固定的,即记录满了以后就从头循环写。

该图展示了一组4个文件的redo log日志,checkpoint之前表示擦除完了的,即可以进行写的,擦除之前会更新到磁盘中,write pos是指写的位置,当write pos和checkpoint相遇的时候表明redo log已经满了,这个时候数据库停止进行数据库更新语句的执行,转而进行redo log日志同步到磁盘中。
redo log是指在回放日志的时候把已经COMMIT的事务重做一遍,对于没有commit的事务按照abort处理,不进行任何操作。
使用redo log时,要求:
1 | 1. 记录redo log时,(T,x,v)中的v必须是x修改后的值,否则不能通过redo log来恢复已经COMMIT的事务。 |
使用redo log时事务执行顺序
1 | 1. 记录START T |
使用redo log重做事务
1 | 1. 扫描日志,找到所有已经COMMIT的事务; |
在日志中使用checkpoint
1 | 1. 在日志中记录checkpoint_start (T1,T2...Tn) (Tx代表做checkpoint时,正在进行还未COMMIT的日志) |
根据checkpoint来加速恢复
1 | 从后往前,扫描redo log |
与undo log类似,在使用时对持久化以及事务操作顺序的要求都比较高,可以将两者结合起来使用,在恢复时,对于已经COMMIT的事务使用redo log进行重做,对于没有COMMIT的事务,使用undo log进行回滚。redo/undo log结合起来使用时,要求同时记录操作修改前和修改后的值,如(T,x,v,w),v为x修改前的值,w为x修改后的值,具体操作顺序为:
1 | 1. 记录START T |
4和3的操作顺序没有严格要求,并且都不要求持久化;因为如果宕机时4已经持久化,则恢复时可通过redo log来重做;如果宕机时4未持久化,则恢复时可通过undo log来回滚;在处理checkpoint时,可采用与redo log相同的处理方式。
checkpoint
checkpoint是为了定期将db buffer的内容刷新到data file。当遇到内存不足、db buffer已满等情况时,需要将db buffer中的内容/部分内容(特别是脏数据)转储到data file中。在转储时,会记录checkpoint发生的”时刻“。在故障回复时候,只需要redo/undo最近的一次checkpoint之后的操作。
undo log日志模块
undo log是把所有没有COMMIT的事务回滚到事务开始前的状态,系统崩溃时,可能有些事务还没有COMMIT,在系统恢复时,这些没有COMMIT的事务就需要借助undo log来进行回滚。
使用undo log时,要求:
1 | 1. 记录修改日志时,(T,x,v)中v为x修改前的值,这样才能借助这条日志来回滚; |
使用undo log时事务执行顺序
1 | 1. 记录START T |
使用undo log进行宕机回滚
1 | 1. 扫描日志,找出所有已经START,还没有COMMIT的事务。 |
如果数据库访问很多,日志量也会很大,宕机恢复时,回滚的工作量也就很大,为了加快回滚,可以通过checkpoint机制来加速回滚,
- 在日志中记录checkpoint_start (T1,T2…Tn) (Tx代表做checkpoint时,正在进行还未COMMIT的事务)
- 等待所有正在进行的事务(T1~Tn)COMMIT
- 在日志中记录checkpoint_end
借助checkpoint来进行回滚
1 | 从后往前,扫描undo log |
使用undo log,在写COMMIT日志时,要求redo log以及事务的所有修改都必须已经持久化,这种做法通常很影响性能。
事务提交(顺序一致性)
一条更新语句如何执行的呢?sql 语句如下:
1 | update tb_student A set A.age='19' where A.name=' 张三 '; |
我们来给张三修改下年龄,在实际数据库肯定不会设置年龄这个字段的,不然要被技术负责人打的。其实条语句也基本上会沿着上一个查询的流程走,只不过执行更新的时候肯定要记录日志啦,这就会引入日志模块了,MySQL 自带的日志模块式 binlog(归档日志) ,所有的存储引擎都可以使用,我们常用的 InnoDB 引擎还自带了一个日志模块 redo log(重做日志),我们就以 InnoDB 模式下来探讨这个语句的执行流程。流程如下:
- 先查询到张三这一条数据,如果有缓存,也是会用到缓存。
- 然后拿到查询的语句,把 age 改为 19,然后调用引擎 API 接口,写入这一行数据,InnoDB 引擎把数据保存在内存中,同时记录 redo log,此时 redo log 进入 prepare 状态,然后告诉执行器,执行完成了,随时可以提交。
- 执行器收到通知后记录 binlog,然后调用引擎接口,提交 redo log 为提交状态。
- 更新完成。
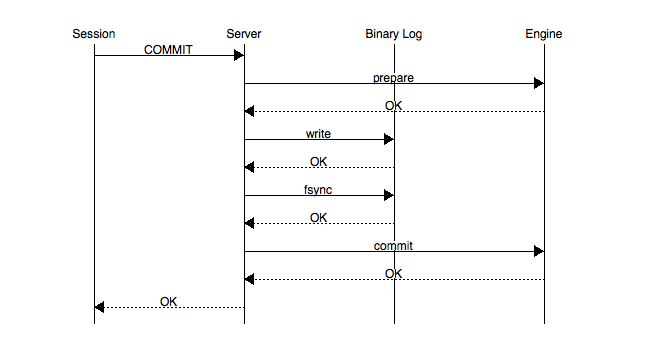
事务的提交主要分为两个主要步骤:
- 准备阶段(Storage Engine(InnoDB) Transaction Prepare Phase)
此时SQL已经成功执行,并生成xid信息及redo和undo的内存日志。然后调用prepare方法完成第一阶段,papare方法实际上什么也没做,将事务状态设为TRX_PREPARED,并将redo log刷磁盘。
-
提交阶段(Storage Engine(InnoDB)Commit Phase)
-
记录协调者日志,即Binlog日志。如果事务涉及的所有存储引擎的prepare都执行成功,则调用TC_LOG_BINLOG::log_xid方法将SQL语句写到binlog(write()将binary log内存日志数据写入文件系统缓存,fsync()将binary log文件系统缓存日志数据永久写入磁盘)。此时,事务已经铁定要提交了。否则,调用ha_rollback_trans方法回滚事务,而SQL语句实际上也不会写到binlog。
-
告诉引擎做commit。
最后,调用引擎的commit完成事务的提交。会清除undo信息,刷redo日志,将事务设为TRX_NOT_STARTED状态。
-
PS:记录Binlog是在InnoDB引擎Prepare(即Redo Log写入磁盘)之后,这点至关重要。
事务的两阶段提交协议保证了无论在任何情况下,事务要么同时存在于存储引擎和binlog中,要么两个里面都不存在,这就保证了主库与从库之间数据的一致性。如果数据库系统发生崩溃,当数据库系统重新启动时会进行崩溃恢复操作,存储引擎中处于prepare状态的事务会去查询该事务是否也同时存在于binlog中,如果存在就在存储引擎内部提交该事务(因为此时从库可能已经获取了对应的binlog内容),如果binlog中没有该事务,就回滚该事务。例如:当崩溃发生在第一步和第二步之间时,明显处于prepare状态的事务还没来得及写入到binlog中,所以该事务会在存储引擎内部进行回滚,这样该事务在存储引擎和binlog中都不会存在;当崩溃发生在第二步和第三步之间时,处于prepare状态的事务存在于binlog中,那么该事务会在存储引擎内部进行提交,这样该事务就同时存在于存储引擎和binlog中。
主从复制 读写分离
介绍
主从复制、读写分离一般是一起使用的。目的很简单,就是为了提高数据库的并发性能。你想,假设是单机,读写都在一台MySQL上面完成,性能肯定不高。如果有三台MySQL,一台mater只负责写操作,两台salve只负责读操作,性能不就能大大提高了吗?
所以主从复制、读写分离就是为了数据库能支持更大的并发。
随着业务量的扩展、如果是单机部署的MySQL,会导致I/O频率过高。采用主从复制、读写分离可以提高数据库的可用性。
原理
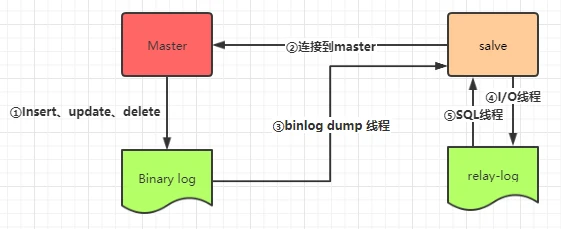
- 当Master节点进行insert、update、delete操作时,会按顺序写入到binlog中。
- salve从库连接master主库,Master有多少个slave就会创建多少个binlog dump线程。
- 当Master节点的binlog发生变化时,binlog dump 线程会通知所有的salve节点,并将相应的binlog内容推送给slave节点。
- I/O线程接收到 binlog 内容后,将内容写入到本地的 relay-log。
- SQL线程读取I/O线程写入的relay-log,并且根据 relay-log 的内容对从数据库做对应的操作。
主从复制完成后,我们还需要实现读写分离,master负责写入数据,两台slave负责读取数据。怎么实现呢?
Apache ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 JDBC、Proxy两部分组成。
ShardingSphere-JDBC定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
读写分离就可以使用ShardingSphere-JDBC实现。
缺点
尽管主从复制、读写分离能很大程度保证MySQL服务的高可用和提高整体性能,但是问题也不少:
- 从机是通过binlog日志从master同步数据的,如果在网络延迟的情况,从机就会出现数据延迟。那么就有可能出现master写入数据后,slave读取数据不一定能马上读出来。
ShardingSphere-JDBC选择在同一线程且统一数据库内,如有写入操作,以后的读操作均从主库读取,用于保证数据一致性。