MIT 6.S081 Lab Lock实验
本文是MIT课程6.S081操作系统学习笔记的一部分:
- Lab util: Unix utilities
- Lab syscall: System calls
- Lab pgtbl: Page tables
- Lab traps: Traps
- Lab cow: Copy-on-write fork
- Lab thread: Multithreading
- Lab net: Network driver
- Lab lock: Parallelism/locking
- Lab fs: File system
- Lab mmap: Mmap
相关的代码都放在了GitHub下了:RayZhang13/MIT-6.S081-2021
课程相关的资源、视频和教材见Lab util: Unix utilities开头。
全乱了全乱了,这Lab顺序… 不管了,先做了再说
准备
对应课程
本次的作业是Lab Lock,我们将重新设计代码,使得程序获得更高的并行性能,这里我们主要将关注内存分配器和块缓存。
网课和Lab顺序相互错开,按照课程进度,我们需要看掉课程的Lecture10,也就是B站课程的P9,同时阅读PDF中的第六章Locking。
另外在本次的Lab的第二部分磁盘缓冲加速中,可能需要我们简单了解部分文件系统的知识,请看Lecture 14,也就是B站课程的P13,并阅读PDF中的第八章File system中的8.1~8.3章节,了解磁盘缓存块的组织形式。
系统环境
使用Arch Linux虚拟机作为实验环境…
环境依赖配置,编译使用make qemu等,如遇到问题,见第一次的Lab util: Unix utilities
使用准备
参考本次的实验说明书:Lab lock: Parallelism/locking
从仓库clone下来课程文件:
1 | git clone git://g.csail.mit.edu/xv6-labs-2021 |
切换到本次作业的lock分支即可:
1 | cd xv6-labs-2021 |
在作业完成后可以使用make grade对所有结果进行评分。
题目
内存分配器加速
要求和提示
在user/kalloctest.c下我们实现了一个测试,在这个测试中针对xv6的内存分配器进行了重点测试,使用了三个进程大量的对地址空间进行增加和缩小,导致大量对kalloc和kfree 的调用,其中kalloc和kfree在执行时均需要获取锁kmem.lock。在这里我们使用kalloctest打印了由于另一进程已经持有了锁而在尝试自旋获取的次数,在这里使用#fetch-and-add打印进行表示。需要指出的是,自旋的次数只能作为锁冲突的一种粗略的衡量。如果我们还没有对当前的Lab做出修改,我们执行kalloctest会得到如下类似的结果:
1 | $ kalloctest |
可以看到acquire针对每一个锁,打印出了当前锁的调用次数(#acquire()后),以及为了获取锁失败而产生的自旋次数(#fetch-and-add()后)。kalloctest通过调用系统调用,要求内核为kmem和bcache打印相关的计数信息,以及5个竞争最激烈的锁。如果发生了锁竞争,那么自旋的次数就会很大。由于在这部分实验中,我们比较关心kmem和bcache两个锁的性能,系统调用最后会返回这两个锁上发生的自旋次数的总和。
需要注意到的是,为了完成当前的Lab,我们需要使用一台多核心独立无负载的机器。如果使用的机器上面有其他的工作负载,kalloctest打印出的计数次数就会失去意义。
现在让我们来关注代码,在kalloctest中产生大量锁冲突的根本原因是kalloc()只有一个空闲列表。为了尽可能的规避锁冲突,我们需要重新设计内存分配器来避免一个唯一的锁和空闲列表。有一个很简单的想法,我们在每个CPU核心中都维护一个空闲列表,每个空闲列表有自己的锁。这样下来,在不同CPU下的内存分配和释放就可以并行运行,因为每个CPU都操作的是不同的空闲列表。这个想法实现下来最大的困难是,如何处理如下情形,一个CPU的空闲列表已经空了,但是另一个CPU仍然有空闲的内存。为了处理这样的情形,我们的CPU需要从别的CPU的空闲列表中“偷出”一部分空闲内存。这种“偷窃内存”也有可能引入锁冲突,但是希望这样会少频繁一些。
我们需要做的事情总结下来就是为每个CPU维护空闲列表,并当空闲列表空时从其他CPU处“偷取”空余内存。也就是说,我们需要为我们的每一个列表的锁都调用initlock,并将名字设置为kmem开头。我们需要运行kalloctest来查看我们的实现是否减少了锁的竞争,此外为了确保实现没有问题我们还能正确分配所有的内存,我们需要运行usertests sbrkmuch测试。我们需要通过test1和test2测试,测试的相关输出示例如下:
1 | $ kalloctest |
相关提示:
- 我们可以使用
kernel/param.h下的NCPU常量表示CPU数量。 - 使用
freerange为当前运行freerange的CPU提供所有空余内存。 - 函数
cpuid可以返回当前的CPU核心编号,但是只有在中断处于关闭状态时调用才是安全的,我们需要使用push_off()和pop_off()来控制中断的关和开。 - 可以看看在
kernel/sprintf.c下是怎么实现格式化字符串的。当然,我们将空闲列表锁的名称设置为kmem也是完全可以的。
思路分析
别的问题这里我都不想多提了,上面的提示给的很清楚。
但是在cpuid()这一块,我是这样理解的,我们需要使用push_off()和pop_off()来屏蔽中断,防止由于定时器中断当前进程发生CPU切换,不然cpuid()返回的核心编号我们也不知道是何时的,那么我们也不知道当时调用kalloc或者kfree的究竟是哪个CPU核心。
但是一旦我们获取了对应的CPU核心编号,我们就不必将对该CPU所属的空闲列表的操作局限在当前CPU下。由于已经确定了编号和对应空闲列表,如果发生定时器中断交由其他CPU操作空闲列表也是完全可以接受的。因此我们只需要将cpuid()前后使用push_off()和pop_off()包裹应该就可,并不需要包裹空闲列表的相关操作。
空闲列表kmem修改
由于现在我们引入了面向NCPU个CPU核心的空闲列表,因此我们有必要将空闲列表有单一的一个升级为数组:
1 | struct run { |
现在我们就可以通过下标来访问对应CPU的空闲列表了。
内存初始化kinit配置
根据要求,我们需要为每一个CPU设置一个空闲列表,同时根据提示自行将锁的名称设置为kmem开头的名称。那其实我们也只需要稍作微调即可:
1 |
|
这里使用到了kernel/sprintf.c下的snprintf()函数,其实就是一个字符串格式化函数,可以去了解一下。简单的来说就是为NCPU个CPU核心分别初始化了空闲列表的锁。
最后我们调用freerange,按照提示,我们直接将当前可用的所有物理内存划给调用freerange的CPU,相关代码我们在下部分展示。
内存初始化freerange配置
在freerange中,根据提示,我们需要将所有的可用内存分配给当前调用freerange的CPU。
那么我们直接通过cpuid()获得调用的CPU核心编号即可,从pa_start到pa_end位置逐页使用kfree函数将每个内存页加入到当前CPU的空闲列表中去:
1 | void |
注意到的是,在这里我没有使用kfree而是另外创建了一个名为kfree_cpu的函数,强行指定了CPU编号及需要操作的空闲列表(主要是考虑到在切换到其他CPU核心后仍然可以正确操作对应空闲列表),内部的函数功能则和kfree基本相似:
1 | // Free the page of physical memory pointed at by v, |
由于我们加入了新的kfree_cpu,因此我们也需要在kernel/defs.h中声明一下:
1 | // kalloc.c |
内存释放kfree实现
按照要求,我们的kfree需要实现的就是将内存页加入到当前CPU所属的空闲列表中,考虑到我们刚才“魔改”的kfree_cpu函数,我们实现kfree并不需要太多代码:
1 | // Free the page of physical memory pointed at by pa, |
内存分配kalloc实现
按照要求,我们先查看当前CPU所属的空闲列表,看看有没有有效节点可以直接从头上拿出来。如果没有,那就遍历着去看其他CPU所属的空闲列表,如果空闲列表中有节点那就直接“偷”出来。
需要注意的是,在查看各个CPU的空闲列表操作时需要及时上锁以防止可能的竞争问题,但是加锁也要避免交叉上锁不然有可能死锁。因此我们不能在没有释放当前CPU空闲列表锁的情况下就尝试获取其他CPU空闲列表锁,这是一种加锁顺序交错导致的经典死锁情形。
1 | // Allocate one 4096-byte page of physical memory. |
测试
现在我们在主目录下运行make clean; make qemu,然后在xv6下尝试运行kalloctest和usertests sbrkmuch,看一下结果:
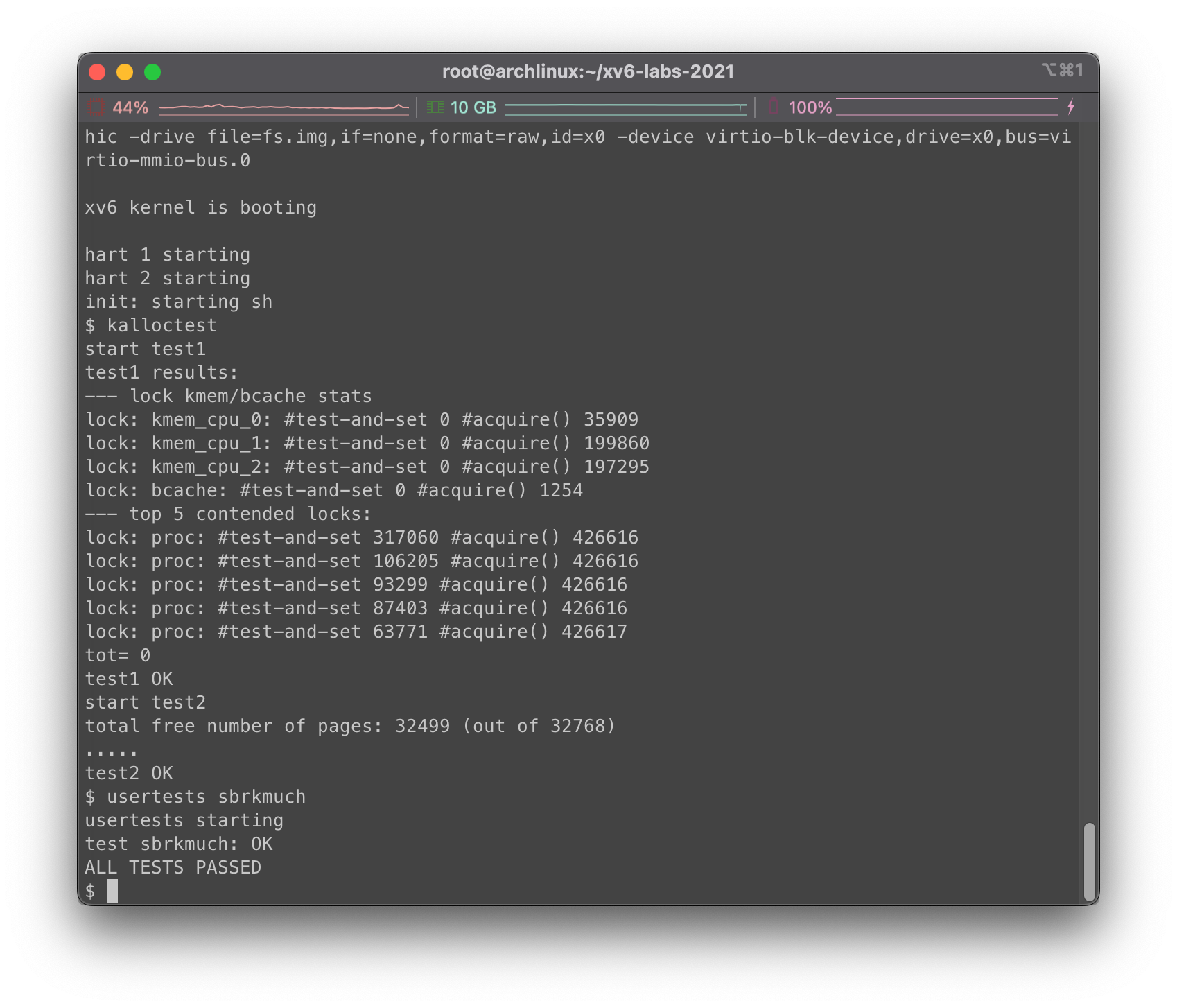
各部分测试都成功通过了,看起来没啥问题
磁盘缓存加速
要求和提示
在本部分中实验与上半部分互相独立,如果愿意也可以先做这部分,前部分结果并不会影响当前部分的完成。
当多个进程尝试大量的使用文件系统时,锁bcache.lock就会产生大量的冲突,这个锁的功能就是在kernel/bio.c中保护磁盘块缓存。我们的测试程序bcachetest会创建多个进程,并不断的读取不同的文件来触发锁bcache.lock上的冲突,在我们还没有完成Lab前,bcachetest输出类似如下:
1 | $ bcachetest |
具体输出的数字可能有所差异,但是肯定可以看到bcache锁由于不断acquire产生的自旋尝试次数会变得很高。在kernel/bio.c中,我们可以看到bcache.lock保护了缓存块列表,包括每个块中的引用数b->refcnt以及缓存块的信息(b->dev和b->blockno):
1 | struct { |
我们的目标是修改缓存块使得在bcachetest测试中,由于对尝试锁acquire产生的自旋次数尽可能的少且接近零。理想状态下,块缓存中涉及所有锁的尝试自旋次数之和应该为0,但是总和小于500也是可以接受的。我们需要修改bget和brelse,使得bcache中的涉及不同缓存块的查找和释放时更不容易在锁上发生冲突(例如,不需要所有操作都等待bcache.lock)。同时,我们需要确保每个磁盘块只会有一份缓存。
当完成时,我们的输出示例如下:
1 | $ bcachetest |
在initlock中,我们需要给我们创建的每个锁一个名字,以bcache开头,。
相比刚才的kalloc内存分配,这里处理减少对于缓存块的竞争问题更加棘手,因为bcache缓冲区是在进程、CPU之间共享的。对于kalloc来说,我们可以为每个CPU安排一个空闲列表来解决,在这里却是行不通的。我们需要使用一个哈希表来查询块编号,并给每一个bucket桶设置一把锁。
这些情况下,如果发生锁冲突我们认定是可以接受的:
- 当两个进程同时操作相同的块编号时,在
bcachetest中的test0我们不会这样测试。 - 当两个进程同时没有命中缓存,并需要寻找一块没有被使用的缓存块进行替换时。我们在
bcachetest中的test0下也不会这样测试。 - 当两个进程操作的块编号在你用来划分区块和锁的方案中发生冲突时;例如,两个进程给定的块编号映射到了同一个哈希表的bucket桶中。这是完全有可能的,
bcachetest中的test0有可能会这样做,这完全取决于我们的设计,但我们应该尝试调整方案的细节以避免冲突(例如,改变哈希表的大小)。
和test0相比之下,test1中将测试操作更多不同的块编号,并大量使用文件系统的代码路径。
相关提示:
- 请阅读xv6教材PDF中关于块缓存的描述(见8.1~8.3节)
- 为哈希表设置固定数量的桶是可以的,可以不去动态调整哈希表的大小。另外可以使用质数数量的桶(例如13)来减少散列冲突。
- 在哈希表中搜索块编号,如果没有命中我们再重新分配条目,这两个操作需要是原子的。
- 我们需要删除所有缓存块列表(
bcache.head等),改为使用缓冲区的最后时间(即使用kernel/trap.c下的ticks来记录时间戳)。这样修改后,brelse就不需要获取bcache锁,bget也可以根据时间戳选择最久没有使用的块。 - 在
bget中序列化地进行驱逐是可行的(即bget中选择缓存块的部分,当查找缓存未命中时可以选择一个缓存块重新使用)。至于为什么要将驱逐操作序列化,可以看我在bget中的分析。 - 我们的答案在一些情形下需要使用两把锁;例如,在驱逐缓存块期间,我们可能需要持有
bcache和哈希表bucket下的锁。请确保不会发生死锁。 - 当我们尝试替换一个缓存块,我们可能需要将一个缓冲块从一个桶bucket转移到另一个桶bucket。我们可能会遇到棘手的问题,也就是新的块可能哈希到与旧的块相同的桶,务必注意不要发生死锁。
- 一些调试小技巧:实现bucket锁的时候,可以先在
bget的开始和结束位置留下全局的bcache.lock的加锁解锁。当我们尝试解决了竞争问题,尝试运行测试的时候再去掉全局锁,处理并发问题。我们也可以使用make CPUS=1 qemu来使用单独一个核心来进行测试。
思路分析
我们简单的浏览kernel/bio.c相关代码,不难看出bcache的组织形式:
1 | struct { |
其实就是一个在空间中划出了一片缓存块列表,但是我们平时操作时不是通过buf数组,而是通过LRU链表来完成的。在binit中,我们可以看到链表被初始化为了一个双向的循环链表,链表的尾部接在了其头部,同时其头部只是一个哨兵节点用于定位用的,遍历的时候不会去访问head:
1 | void |
在brelse中,如果当前缓存块引用数归零,我们就将其回收,将节点重新放置到head的后面:
1 | // Release a locked buffer. |
而在bget中,我们首先遍历链表,查找有没有信息一致直接命中的缓存块。如果没有,再从尾部向头部遍历,这样也符合LRU的原则,越在后部的未使用缓存块越久没被使用:
1 | // Look through buffer cache for block on device dev. |
根据上面的要求和提示信息,遍历链表花费的时间太长,而且每次扫描整个的链表以及修改的过程都会大量涉及加锁,性能开销很大。因此我们引入哈希表,通过数组链表的方式来减缓冲突,通过这样的办法我们就可以把加锁的粒度缩小到单个bucket桶,从而提升性能。
由于弃用了LRU双向链表,根据提示建议,在哈希表中我们需要为bucket下单向链表中的每一个节点设置时间戳信息,以方便在LRU过程中根据时间戳判断最久未使用的节点。
在哈希算法上直接使用取模函数即可,bucket数量我们也使用质数,例如13个。
bcache缓存结构修改
我们现在要放弃bcache中原先的双向链表结构,转而使用哈希表。因此,我们需要对bcache以及buf等数据结构进行微调。
哈希表中我们使用的是数组单向链表,所以buf中删去prev前节点,并添加新的时间戳标志timestamp:
1 | struct buf { |
在bcache中,我们需要重新构建哈希表,因此我们定义bucket对象为:
1 | struct bucket { |
其中包含bucket对应的锁,以及链表的头节点。
接下来我们尝试修改bcache,将建立的哈希表放进去:
1 |
|
binit初始化实现
首先我们要设置哈希的函数,将每一个块编号映射到对应的桶里面:
1 | int hash(uint dev, uint blockno) { |
接下来我们开始实现初始化,我们可以考虑根据在bcache中buf[]数组的下标将空闲块均匀的打乱在各个bucket中,每次使用头插法将节点插在头部:
1 |
|
brelse释放缓存块实现
我们先处理简单的释放缓存块逻辑,我们只需要在刚才的基础上稍加修改即可,每次不必去锁bcache的大锁,而是看bucket上的小锁:
1 | // Release a locked buffer and update the timestamp |
bpin/bunpin计数加减实现
这块原理同上brelse,我们每次直接锁对应bucket即可:
1 | void |
bget获取缓存块实现
接下来就是重点实现bget函数,首先我们查看在对应的bucket中当前的块是否被缓存,如果被缓存则直接返回;否则我们尝试查找一个块并将其驱逐,查找可用的块我们需要遍历各个bucket根据时间戳找到最久未使用也就是时间戳最小的空闲块。
这就给我一个年纪轻轻的强迫症带来了莫大的痛苦,脑子里疯狂脑补并发不安全和死锁情况,主要有一对矛盾很难解除。假设我们目前正在操作第i号bucket,由于没有命中缓存,我们需要根据LRU原则扫描第j号bucket:
- 我们应当在给
j号bucket加锁前,给i号bucket解锁,不然套娃上锁情况下,不正确的加锁顺序可能会导致死锁。例如另外一个进程目前持有j的锁,正在申请i的锁;当前进程持有i的锁,正在申请j的锁。 - 另一方面,给
i解锁又是万万不得的,因为当我们之后解锁出去在为i号bucket寻找空闲块时,如果i号bucket上恰好由于空闲块驱逐被相同blockno块编号的填入,我们找到了空闲块再填到链表头部,那就是两个相同的blockno了。
这就是一种矛盾… 困扰的人想自杀… 我们干脆直接将驱逐操作序列化… 刚好我们使用bcache.lock作为我们的驱逐锁,只有当前持有驱逐锁的进程才有权力对bucket进行驱逐插入操作。
1 | // Look through buffer cache for block on device dev. |
这里看到我们在获得了bcache.lock驱逐锁后重新对当前bucket做了一遍扫描,其目的是为了防止在bucket锁释放和驱逐锁获取中间的窗口期发生了一些不好的事情。例如另外一个进程操作了这个bucket,不管他怎么做到的,他有可能成功在列表中添加了blockno编号的缓存块,如果我们不重新检查,可能会发生重复插入,这是不能接受的。(至于为啥不把bucket锁释放和驱逐锁获取顺序颠倒一下,看了下会有死锁…)
之后大致思路简单来说就是,遍历各个桶链表中的各个节点,对比时间戳,找到最久未使用的需要驱逐的缓存块,然后我们把他“偷到”我们当前的bucket里来就好了。
测试
主目录下运行make clean; make qemu,我们在xv6中运行bcachetest:
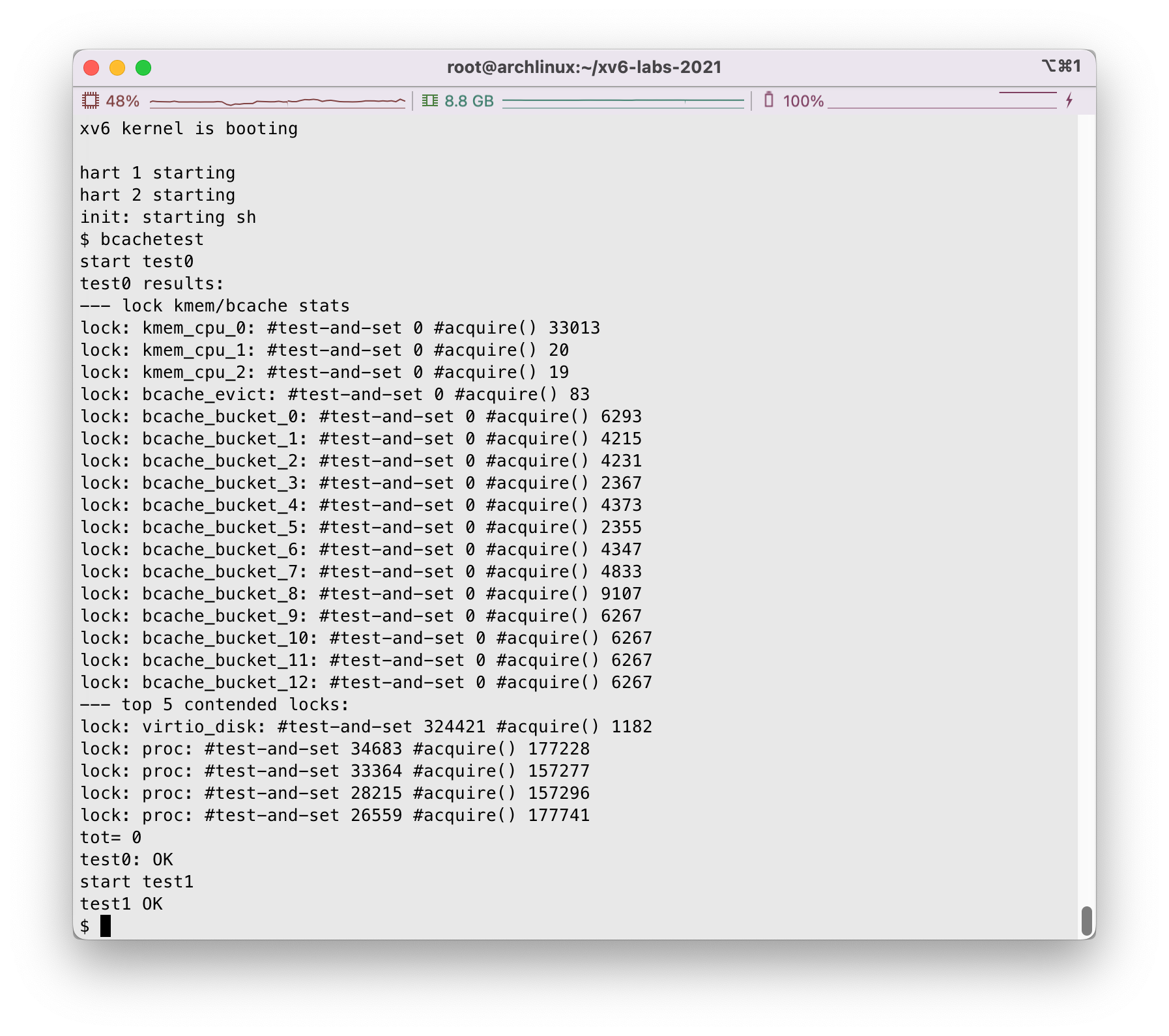
看起来问题不大
总结
接下来我们来到主目录上使用make grade进行评分,有几点注意一下:
-
你需要在主目录下创建
time.txt表示完成任务的时间。 -
测试过程中
usertests耗时略长,电脑机能不行的小伙伴可以适当将测试的超时延长一点点,请把主目录下grade-lab-lock文件里面的timeout参数改大点,不然可能你的测试项目还没跑完他就跳出给你标个大大的 FAIL…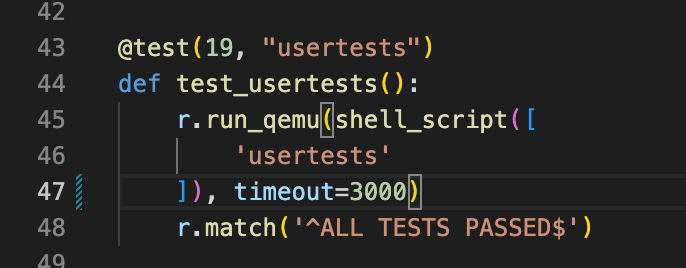
接下来,我们主目录下make grade一下,看下结果:
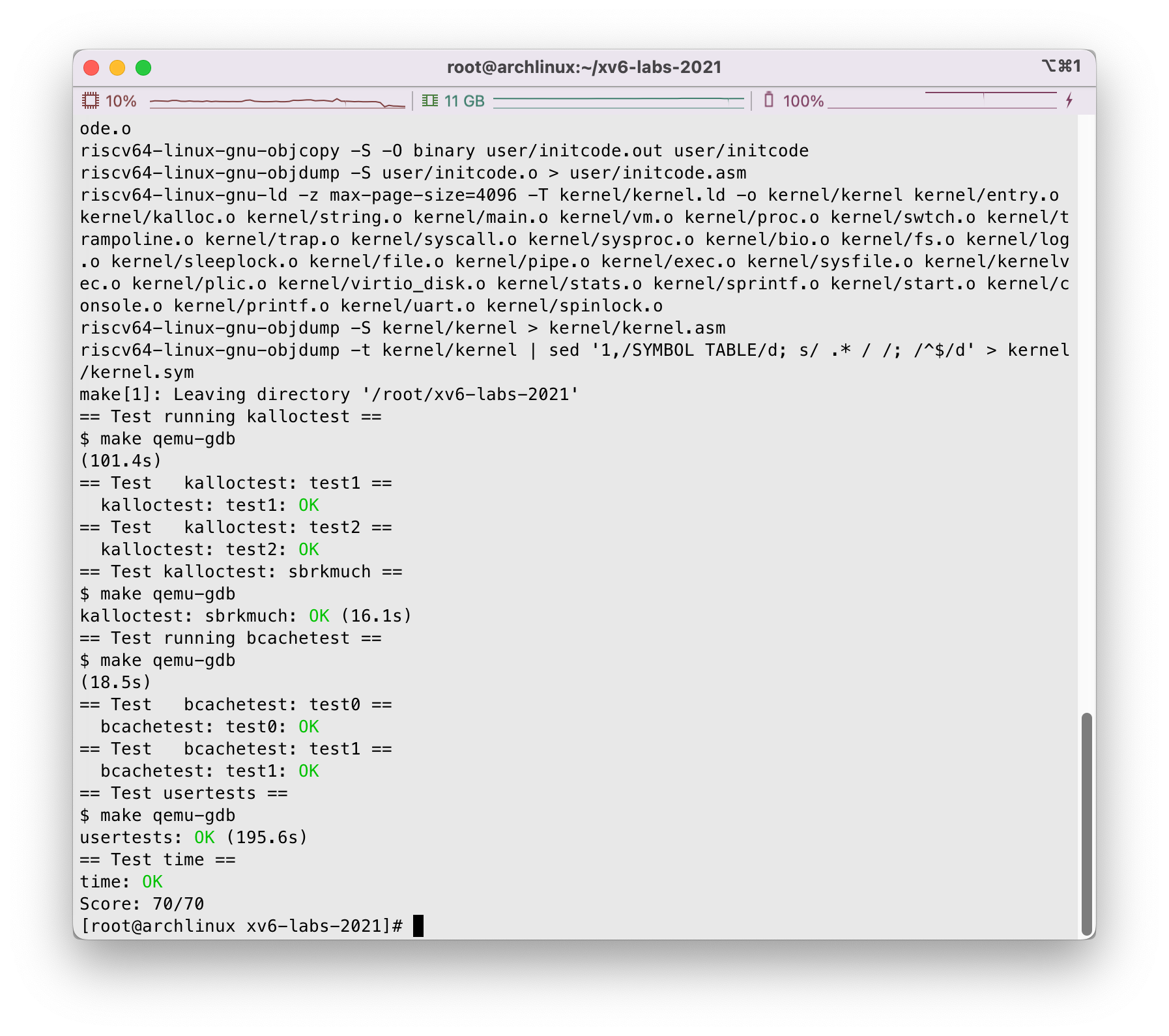
看着不错,完事~








