funcDebug(topic logTopic, format string, a ...interface{}) { if debugVerbosity >= 1 { time := time.Since(debugStart).Microseconds() time /= 100 prefix := fmt.Sprintf("%06d %v ", time, string(topic)) format = prefix + format log.Printf(format, a...) } }
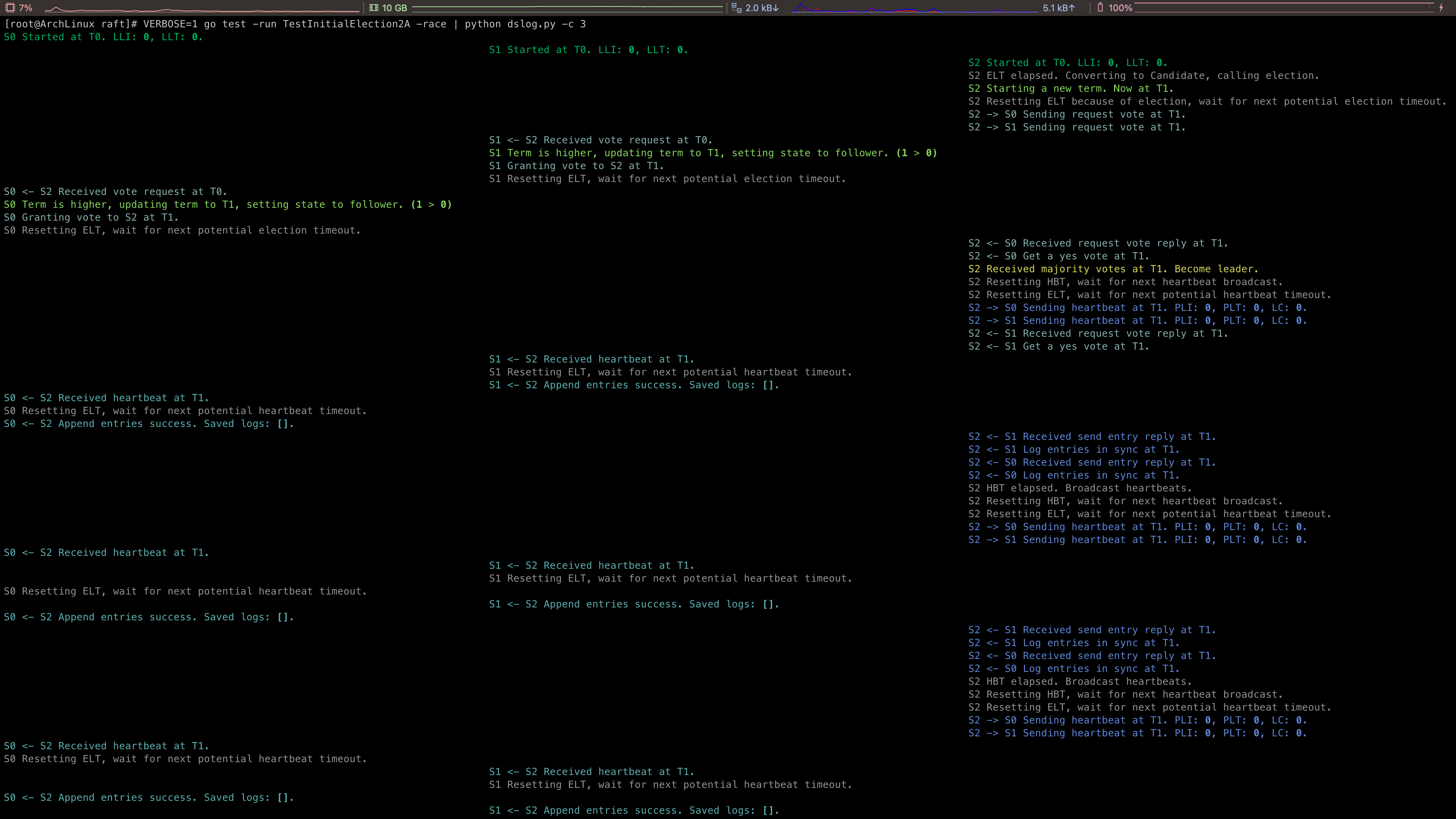
# You can just pipe the go test output into the script $ VERBOSE=1 go test -run InitialElection | python dslogs # ... colored output will be printed
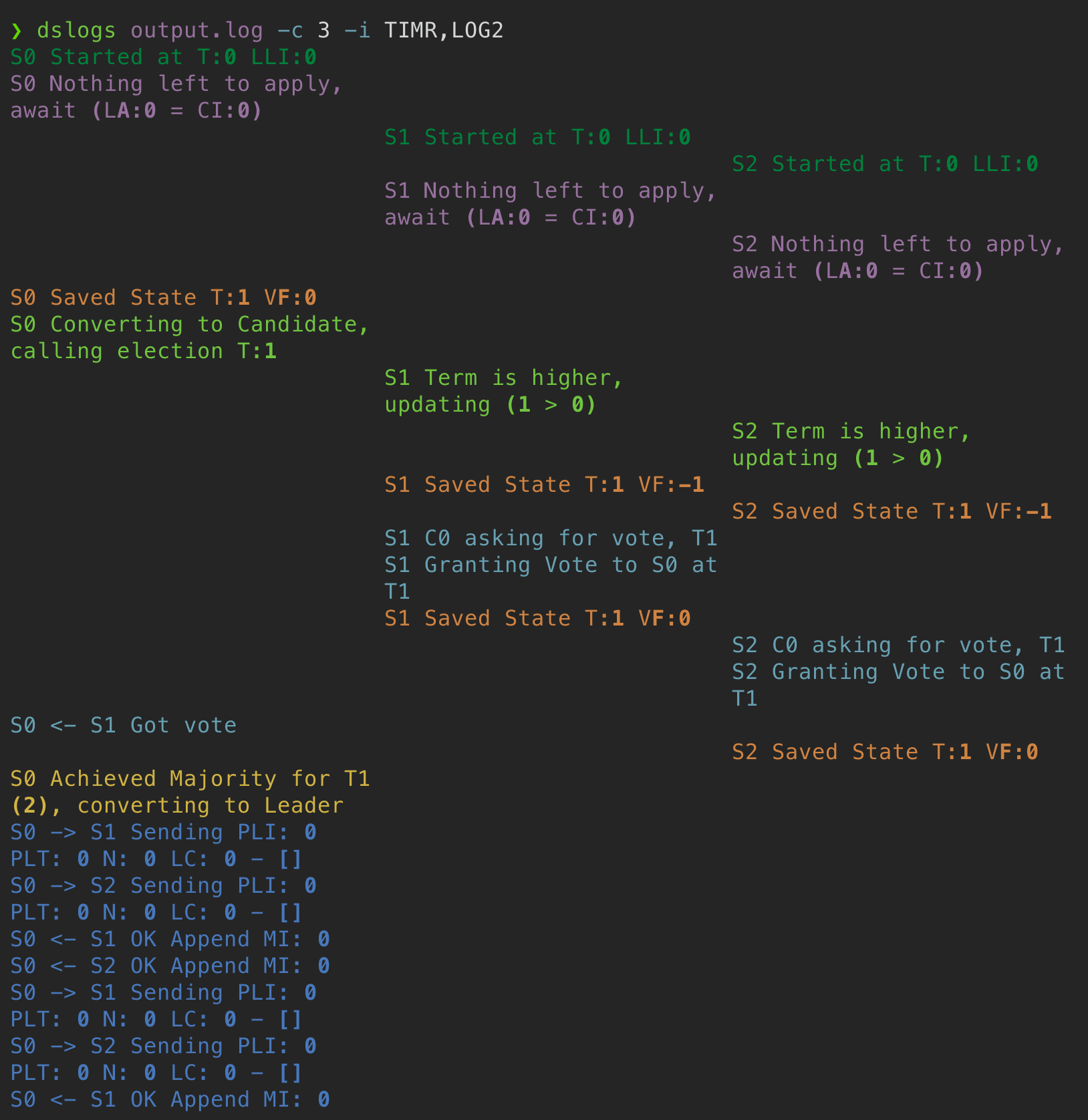
# We can ignore verbose topics like timers or log changes $ VERBOSE=1 go test -run Backup | python dslogs -c 5 -i TIMR,DROP,LOG2 # ... colored output in 5 columns
# Dumping output to a file can be handy to iteratively # filter topics and when failures are hard to reproduce $ VERBOSE=1 go test -run Figure8Unreliable > output.log # Print from a file, selecting just two topics $ python dslogs output.log -j CMIT,PERS # ... colored output
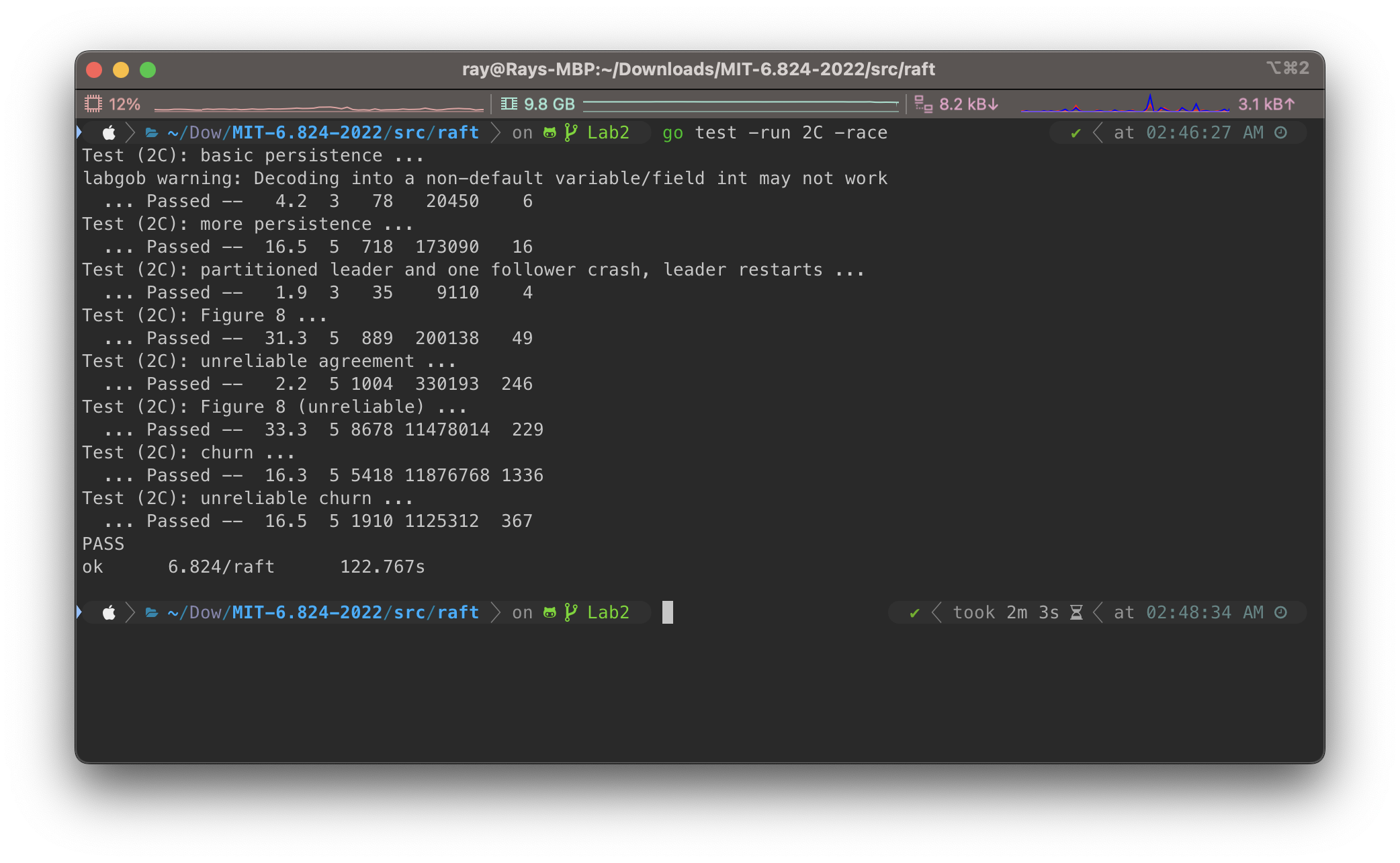
本部分中,我们需要实现Raft的leader选举和心跳检测(通过发送AppendEntriesRPC请求但是不携带日志条目)。在2A部分中,我们的目标是选举一个leader,并且在没有发生故障的情况下使其继续保持leader,如果发生故障或者老leader发送/接受的数据包丢失则让新的leader接替。最终运行go test -run 2A来测试代码。
相关提示:
这次的Lab中并没有简单的方法直接让我们的Raft实现运行起来;我们需要通过测试代码来运行,即go test -run 2A。
Term confusion refers to servers getting confused by RPCs that come from old terms. In general, this is not a problem when receiving an RPC, since the rules in Figure 2 say exactly what you should do when you see an old term. However, Figure 2 generally doesn’t discuss what you should do when you get old RPC replies. From experience, we have found that by far the simplest thing to do is to first record the term in the reply (it may be higher than your current term), and then to compare the current term with the term you sent in your original RPC. If the two are different, drop the reply and return. Only if the two terms are the same should you continue processing the reply. There may be further optimizations you can do here with some clever protocol reasoning, but this approach seems to work well. And not doing it leads down a long, winding path of blood, sweat, tears and despair.
// A Go object implementing raft log entry type LogEntry struct { Command interface{} // Command to be excuted Term int// Term number when created }
// A Go object implementing a single Raft peer. type Raft struct { mu sync.Mutex // Lock to protect shared access to this peer's state peers []*labrpc.ClientEnd // RPC end points of all peers persister *Persister // Object to hold this peer's persisted state me int// this peer's index into peers[] dead int32// set by Kill()
// Your data here (2A, 2B, 2C). // Look at the paper's Figure 2 for a description of what // state a Raft server must maintain.
state RaftState heartbeatTime time.Time electionTime time.Time
// Persistent state on all servers
currentTerm int// latest term server has seen votedFor int// candidateId that received vote in current term log LogEntries // log entries; each entry contains command for state machine, and term when entry was received by leader
// Volatile state on all servers
commitIndex int// index of highest log entry known to be committed lastApplied int// index of highest log entry applied to state machine
// Volatile state on leaders (Reinitialized after election)
nextIndex []int// for each server, index of the next log entry to send to that server matchIndex []int// for each server, index of highest log entry known to be replicated on server }
// index and term start from 1 func(logEntries LogEntries) getEntry(index int) *LogEntry { if index < 0 { log.Panic("LogEntries.getEntry: index < 0.\n") } if index == 0 { return &LogEntry{ Command: nil, Term: 0, } } if index > len(logEntries) { return &LogEntry{ Command: nil, Term: -1, } } return &logEntries[index-1] }
func(logEntries LogEntries) lastLogInfo() (index, term int) { index = len(logEntries) logEntry := logEntries.getEntry(index) return index, logEntry.Term }
func(logEntries LogEntries) getSlice(startIndex, endIndex int) LogEntries { if startIndex <= 0 { Debug(dError, "LogEntries.getSlice: startIndex out of range. startIndex: %d, len: %d.", startIndex, len(logEntries)) log.Panic("LogEntries.getSlice: startIndex out of range. \n") } if endIndex > len(logEntries)+1 { Debug(dError, "LogEntries.getSlice: endIndex out of range. endIndex: %d, len: %d.", endIndex, len(logEntries)) log.Panic("LogEntries.getSlice: endIndex out of range.\n") } if startIndex > endIndex { Debug(dError, "LogEntries.getSlice: startIndex > endIndex. (%d > %d)", startIndex, endIndex) log.Panic("LogEntries.getSlice: startIndex > endIndex.\n") } return logEntries[startIndex-1 : endIndex-1] }
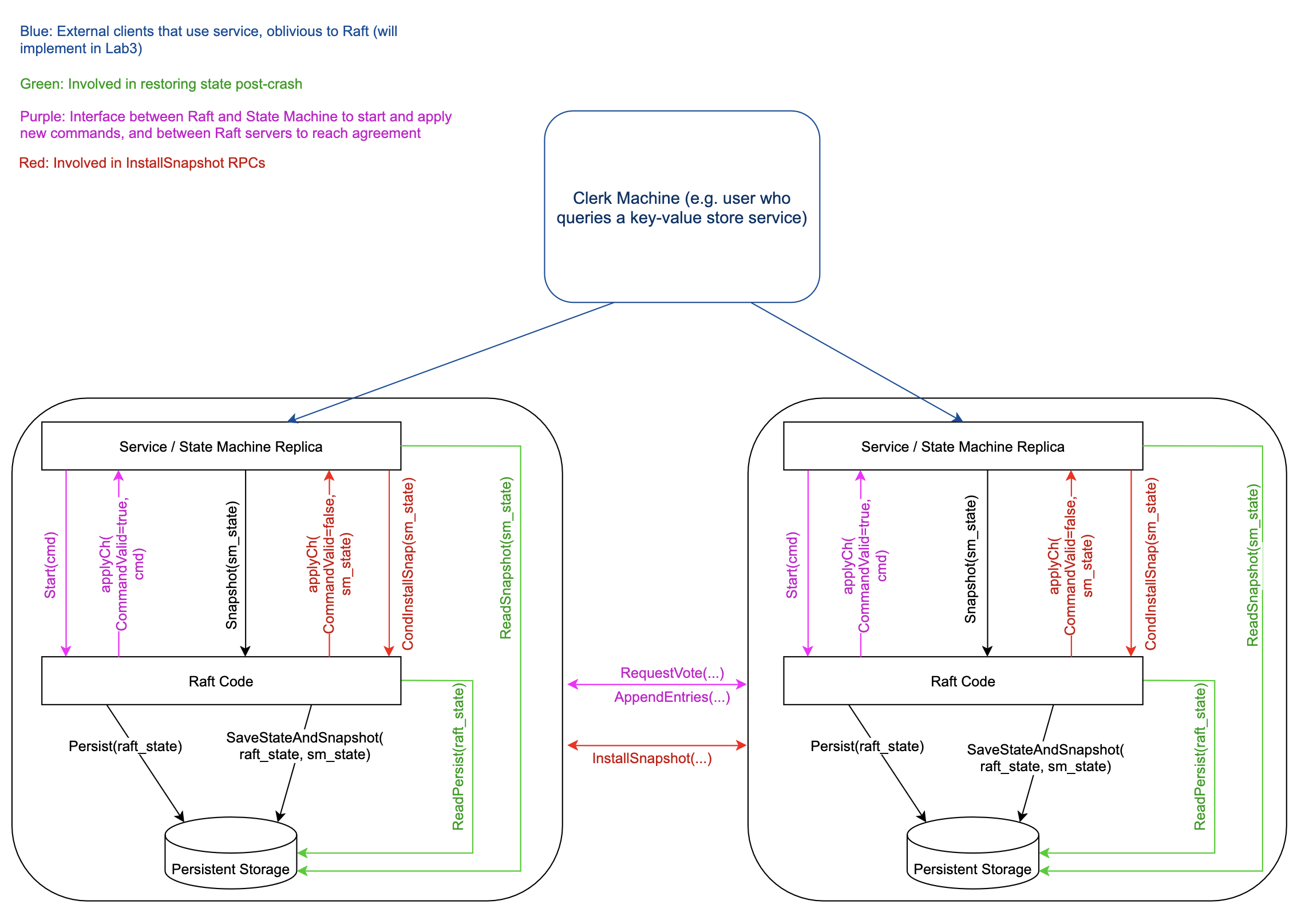
// the service or tester wants to create a Raft server. the ports // of all the Raft servers (including this one) are in peers[]. this // server's port is peers[me]. all the servers' peers[] arrays // have the same order. persister is a place for this server to // save its persistent state, and also initially holds the most // recent saved state, if any. applyCh is a channel on which the // tester or service expects Raft to send ApplyMsg messages. // Make() must return quickly, so it should start goroutines // for any long-running work. funcMake(peers []*labrpc.ClientEnd, me int, persister *Persister, applyCh chan ApplyMsg) *Raft {
type AppendEntriesArgs struct { Term int// leader’s term LeaderId int// with leaderId follower can redirect clients PrevLogIndex int// index of log entry immediately preceding new ones PrevLogTerm int// term of prevLogIndex entry Entries []LogEntry // log entries to store (empty for heartbeat; may send more than one for efficiency) LeaderCommit int// leader's commitIndex }
type AppendEntriesReply struct { Term int// currentTerm, for leader to update itself Success bool// true if follower contained entry matching prevLogIndex and prevLogTerm }
// example RequestVote RPC arguments structure. // field names must start with capital letters! type RequestVoteArgs struct { // Your data here (2A, 2B). Term int// candidate's term CandidateId int// candidate requesting vote LastLogIndex int// index of candidate’s last log entry (§5.4) LastLogTerm int// term of candidate’s last log entry (§5.4) }
// example RequestVote RPC reply structure. // field names must start with capital letters! type RequestVoteReply struct { // Your data here (2A). Term int// currentTerm, for candidate to update itself VoteGranted bool// true means candidate received vote }
// These constants are all in milliseconds. const TickInterval int64 = 30// Loop interval for ticker and applyLogsLoop. Mostly for checking timeouts.
// The ticker go routine starts a new election if this peer hasn't received // heartsbeats recently. // The routine also broadcasts heartbeats and appies logs periodically. func(rf *Raft) ticker() { for !rf.killed() {
// Your code here to check if a leader election should // be started and to randomize sleeping time using // time.Sleep(). rf.mu.Lock() // leader repeat heartbeat during idle periods to prevent election timeouts (§5.2) if rf.state == LeaderState && time.Now().After(rf.heartbeatTime) { Debug(dTimer, "S%d HBT elapsed. Broadcast heartbeats.", rf.me) rf.sendEntries(true) } // If election timeout elapses: start new election if time.Now().After(rf.electionTime) { Debug(dTimer, "S%d ELT elapsed. Converting to Candidate, calling election.", rf.me) rf.raiseElection() } rf.mu.Unlock() time.Sleep(time.Duration(TickInterval) * time.Millisecond) } }
// These constants are all in milliseconds. const BaseHeartbeatTimeout int64 = 300// Lower bound of heartbeat timeout. Election is raised when timeout as a follower. const BaseElectionTimeout int64 = 1000// Lower bound of election timeout. Another election is raised when timeout as a candidate.
const RandomFactor float64 = 0.8// Factor to control upper bound of heartbeat timeouts and election timeouts.
// These constants are all in milliseconds. const HeartbeatInterval int64 = 100// Interval between heartbeats. Broadcast heartbeats when timeout as a leader.
func(rf *Raft) setHeartbeatTimeout(timeout time.Duration) { t := time.Now() t = t.Add(timeout) rf.heartbeatTime = t }
RequestVote RPC核心函数实现
我们先来看简单点的请求投票里面的RPC实现。
首先在图2中的提示里的Rules for Servers (All Servers) 里面有一段话:
If RPC request or response contains term T > currentTerm: set currentTerm = T, convert to follower (§5.1)
// If RPC request or response contains term T > currentTerm: set currentTerm = T, convert to follower (§5.1) // Check if current term is out of date when hearing from other peers, // update term, revert to follower state and return true if necesarry func(rf *Raft) checkTerm(term int) bool { if rf.currentTerm < term { Debug(dTerm, "S%d Term is higher, updating term to T%d, setting state to follower. (%d > %d)", rf.me, term, term, rf.currentTerm) rf.state = FollowerState rf.currentTerm = term rf.votedFor = -1 returntrue } returnfalse }
接下来我们就完全按照图2 RequestVote RPC部分给出的提示来:
Reply false if term < currentTerm (§5.1)
If votedFor is null or candidateId, and candidate’s log is at least as up-to-date as receiver’s log, grant vote (§5.2, §5.4)
Raft uses the voting process to prevent a candidate from winning an election unless its log contains all committed entries. A candidate must contact a majority of the cluster in order to be elected, which means that every committed entry must be present in at least one of those servers. If the candidate’s log is at least as up-to-date as any other log in that majority (where “up-to-date” is defined precisely below), then it will hold all the committed entries. The RequestVote RPC implements this restriction: the RPC includes information about the candidate’s log, and the voter denies its vote if its own log is more up-to-date than that of the candidate.
Raft determines which of two logs is more up-to-date by comparing the index and term of the last entries in the logs. If the logs have last entries with different terms, then the log with the later term is more up-to-date. If the logs end with the same term, then whichever log is longer is more up-to-date.
func(rf *Raft) candidateRequestVote(voteCount *int, args *RequestVoteArgs, once *sync.Once, server int) { reply := &RequestVoteReply{} ok := rf.sendRequestVote(server, args, reply) if ok { rf.mu.Lock() defer rf.mu.Unlock() Debug(dVote, "S%d <- S%d Received request vote reply at T%d.", rf.me, server, rf.currentTerm) if reply.Term < rf.currentTerm { Debug(dVote, "S%d Term is lower, invalid vote reply. (%d < %d)", rf.me, reply.Term, rf.currentTerm) return } if rf.currentTerm != args.Term { Debug(dWarn, "S%d Term has changed after the vote request, vote reply discarded. "+ "requestTerm: %d, currentTerm: %d.", rf.me, args.Term, rf.currentTerm) return } // If AppendEntries RPC received from new leader: convert to follower rf.checkTerm(reply.Term) if reply.VoteGranted { *voteCount++ Debug(dVote, "S%d <- S%d Get a yes vote at T%d.", rf.me, server, rf.currentTerm) // If votes received from majority of servers: become leader if *voteCount > len(rf.peers)/2 { once.Do(func() { Debug(dLeader, "S%d Received majority votes at T%d. Become leader.", rf.me, rf.currentTerm) rf.state = LeaderState lastLogIndex, _ := rf.log.lastLogInfo() for peer := range rf.peers { rf.nextIndex[peer] = lastLogIndex + 1 rf.matchIndex[peer] = 0 } // Upon election: send initial empty AppendEntries RPCs (heartbeat) to each server rf.sendEntries(true) }) } } else { Debug(dVote, "S%d <- S%d Get a no vote at T%d.", rf.me, server, rf.currentTerm) } } }
AppendEntries RPC核心函数实现
接下来我们来看AppendEntriesRPC的核心实现部分,图2中给出了提示:
Reply false if term < currentTerm (§5.1)
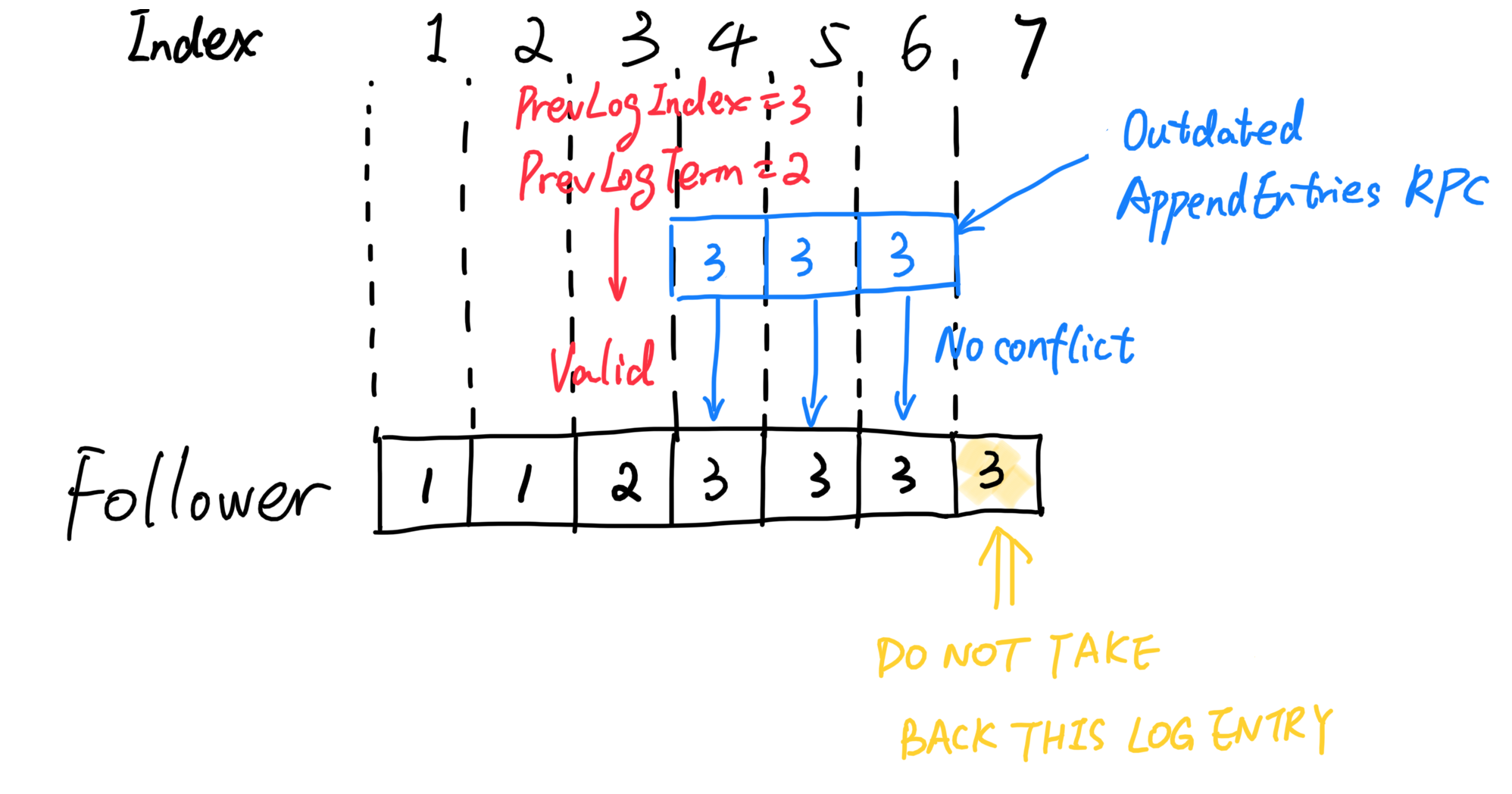
Reply false if log doesn’t contain an entry at prevLogIndex whose term matches prevLogTerm (§5.3)
If an existing entry conflicts with a new one (same index but different terms), delete the existing entry and all that follow it (§5.3)
// Reply false if term < currentTerm (§5.1) if args.Term < rf.currentTerm { Debug(dLog2, "S%d Term is lower, rejecting append request. (%d < %d)", rf.me, args.Term, rf.currentTerm) reply.Term = rf.currentTerm return }
// For Candidates. If AppendEntries RPC received from new leader: convert to follower if rf.state == CandidateState && rf.currentTerm == args.Term { rf.state = FollowerState Debug(dLog2, "S%d Convert from candidate to follower at T%d.", rf.me, rf.currentTerm) }
Debug(dTimer, "S%d Resetting ELT, wait for next potential heartbeat timeout.", rf.me) rf.setElectionTimeout(randHeartbeatTimeout())
// Reply false if log doesn’t contain an entry at prevLogIndex whose term matches prevLogTerm (§5.3) if args.PrevLogTerm == -1 || args.PrevLogTerm != rf.log.getEntry(args.PrevLogIndex).Term { Debug(dLog2, "S%d Prev log entries do not match. Ask leader to retry.", rf.me) return } // If an existing entry conflicts with a new one (same index but different terms), // delete the existing entry and all that follow it (§5.3) for i, entry := range args.Entries { if rf.log.getEntry(i+1+args.PrevLogIndex).Term != entry.Term { rf.log = append(rf.log.getSlice(1, i+1+args.PrevLogIndex), args.Entries[i:]...) break } } Debug(dLog2, "S%d <- S%d Append entries success. Saved logs: %v.", rf.me, args.LeaderId, args.Entries) reply.Success = true }
// A Go object implementing a single Raft peer. type Raft struct { mu sync.Mutex // Lock to protect shared access to this peer's state peers []*labrpc.ClientEnd // RPC end points of all peers persister *Persister // Object to hold this peer's persisted state me int// this peer's index into peers[] dead int32// set by Kill()
// Your data here (2A, 2B, 2C). // Look at the paper's Figure 2 for a description of what // state a Raft server must maintain.
leaderId int// the leader server that current server recognizes state RaftState heartbeatTime time.Time electionTime time.Time
// Persistent state on all servers
currentTerm int// latest term server has seen votedFor int// candidateId that received vote in current term log LogEntries // log entries; each entry contains command for state machine, and term when entry was received by leader
// Volatile state on all servers
commitIndex int// index of highest log entry known to be committed lastApplied int// index of highest log entry applied to state machine
// Volatile state on leaders (Reinitialized after election)
nextIndex []int// for each server, index of the next log entry to send to that server matchIndex []int// for each server, index of highest log entry known to be replicated on server }
// the service using Raft (e.g. a k/v server) wants to start // agreement on the next command to be appended to Raft's log. if this // server isn't the leader, returns false. otherwise start the // agreement and return immediately. there is no guarantee that this // command will ever be committed to the Raft log, since the leader // may fail or lose an election. even if the Raft instance has been killed, // this function should return gracefully. // // the first return value is the index that the command will appear at // if it's ever committed. the second return value is the current // term. the third return value is true if this server believes it is // the leader. func(rf *Raft) Start(command interface{}) (int, int, bool) { index := -1 term := -1 isLeader := true
// Your code here (2B). rf.mu.Lock() defer rf.mu.Unlock() if rf.state != LeaderState { return-1, -1, false } logEntry := LogEntry{ Command: command, Term: rf.currentTerm, } rf.log = append(rf.log, logEntry) index = len(rf.log) term = rf.currentTerm Debug(dLog, "S%d Add command at T%d. LI: %d, Command: %v\n", rf.me, term, index, command) rf.sendEntries(false)
// the service or tester wants to create a Raft server. the ports // of all the Raft servers (including this one) are in peers[]. this // server's port is peers[me]. all the servers' peers[] arrays // have the same order. persister is a place for this server to // save its persistent state, and also initially holds the most // recent saved state, if any. applyCh is a channel on which the // tester or service expects Raft to send ApplyMsg messages. // Make() must return quickly, so it should start goroutines // for any long-running work. funcMake(peers []*labrpc.ClientEnd, me int, persister *Persister, applyCh chan ApplyMsg) *Raft {
// If RPC request or response contains term T > currentTerm: set currentTerm = T, convert to follower (§5.1) // Check if current term is out of date when hearing from other peers, // update term, revert to follower state and return true if necesarry func(rf *Raft) checkTerm(term int) bool { if rf.currentTerm < term { Debug(dTerm, "S%d Term is higher, updating term to T%d, setting state to follower. (%d > %d)", rf.me, term, term, rf.currentTerm) rf.state = FollowerState rf.currentTerm = term rf.votedFor = -1 rf.leaderId = -1 returntrue } returnfalse }
// Reply false if term < currentTerm (§5.1) if args.Term < rf.currentTerm { Debug(dLog2, "S%d Term is lower, rejecting append request. (%d < %d)", rf.me, args.Term, rf.currentTerm) reply.Term = rf.currentTerm return }
// For Candidates. If AppendEntries RPC received from new leader: convert to follower if rf.state == CandidateState && rf.currentTerm == args.Term { rf.state = FollowerState Debug(dLog2, "S%d Convert from candidate to follower at T%d.", rf.me, rf.currentTerm) }
func(rf *Raft) applyLogsLoop(applyCh chan ApplyMsg) { for !rf.killed() { // Apply logs periodically until the last committed index. rf.mu.Lock() // To avoid the apply operation getting blocked with the lock held, // use a slice to store all committed msgs to apply, and apply them only after unlocked appliedMsgs := []ApplyMsg{} for rf.commitIndex > rf.lastApplied { rf.lastApplied++ appliedMsgs = append(appliedMsgs, ApplyMsg{ CommandValid: true, Command: rf.log.getEntry(rf.lastApplied).Command, CommandIndex: rf.lastApplied, }) Debug(dLog2, "S%d Applying log at T%d. LA: %d, CI: %d.", rf.me, rf.currentTerm, rf.lastApplied, rf.commitIndex) } rf.mu.Unlock() for _, msg := range appliedMsgs { applyCh <- msg } time.Sleep(time.Duration(TickInterval) * time.Millisecond) } }
// the service or tester wants to create a Raft server. the ports // of all the Raft servers (including this one) are in peers[]. this // server's port is peers[me]. all the servers' peers[] arrays // have the same order. persister is a place for this server to // save its persistent state, and also initially holds the most // recent saved state, if any. applyCh is a channel on which the // tester or service expects Raft to send ApplyMsg messages. // Make() must return quickly, so it should start goroutines // for any long-running work. funcMake(peers []*labrpc.ClientEnd, me int, persister *Persister, applyCh chan ApplyMsg) *Raft {
// Reply false if term < currentTerm (§5.1) if args.Term < rf.currentTerm { Debug(dLog2, "S%d Term is lower, rejecting append request. (%d < %d)", rf.me, args.Term, rf.currentTerm) reply.Term = rf.currentTerm return }
// For Candidates. If AppendEntries RPC received from new leader: convert to follower if rf.state == CandidateState && rf.currentTerm == args.Term { rf.state = FollowerState Debug(dLog2, "S%d Convert from candidate to follower at T%d.", rf.me, rf.currentTerm) }
Debug(dTimer, "S%d Resetting ELT, wait for next potential heartbeat timeout.", rf.me) rf.setElectionTimeout(randHeartbeatTimeout())
rf.leaderId = args.LeaderId
// Reply false if log doesn’t contain an entry at prevLogIndex whose term matches prevLogTerm (§5.3) if args.PrevLogTerm == -1 || args.PrevLogTerm != rf.log.getEntry(args.PrevLogIndex).Term { Debug(dLog2, "S%d Prev log entries do not match. Ask leader to retry.", rf.me) return } // If an existing entry conflicts with a new one (same index but different terms), // delete the existing entry and all that follow it (§5.3) for i, entry := range args.Entries { if rf.log.getEntry(i+1+args.PrevLogIndex).Term != entry.Term { rf.log = append(rf.log.getSlice(1, i+1+args.PrevLogIndex), args.Entries[i:]...) break } } Debug(dLog2, "S%d <- S%d Append entries success. Saved logs: %v.", rf.me, args.LeaderId, args.Entries) if args.LeaderCommit > rf.commitIndex { Debug(dCommit, "S%d Get higher LC at T%d, updating commitIndex. (%d < %d)", rf.me, rf.currentTerm, rf.commitIndex, args.LeaderCommit) rf.commitIndex = min(args.LeaderCommit, args.PrevLogIndex+len(args.Entries)) Debug(dCommit, "S%d Updated commitIndex at T%d. CI: %d.", rf.me, rf.currentTerm, rf.commitIndex) } reply.Success = true }
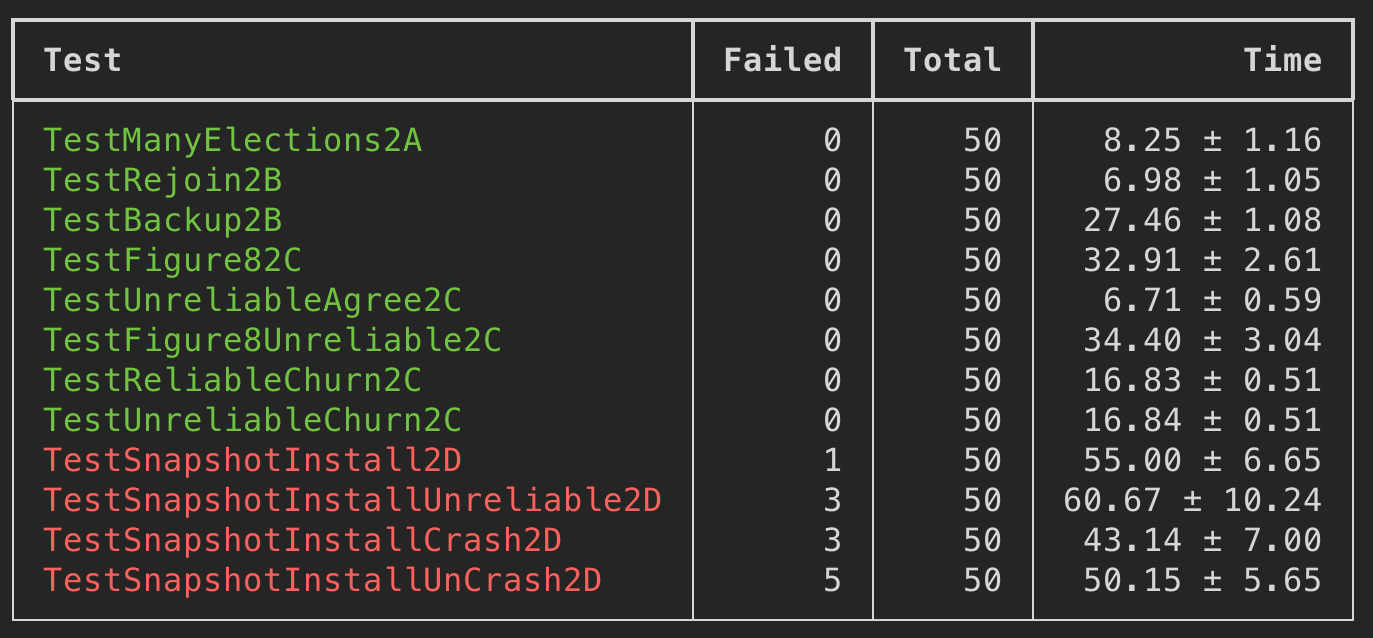
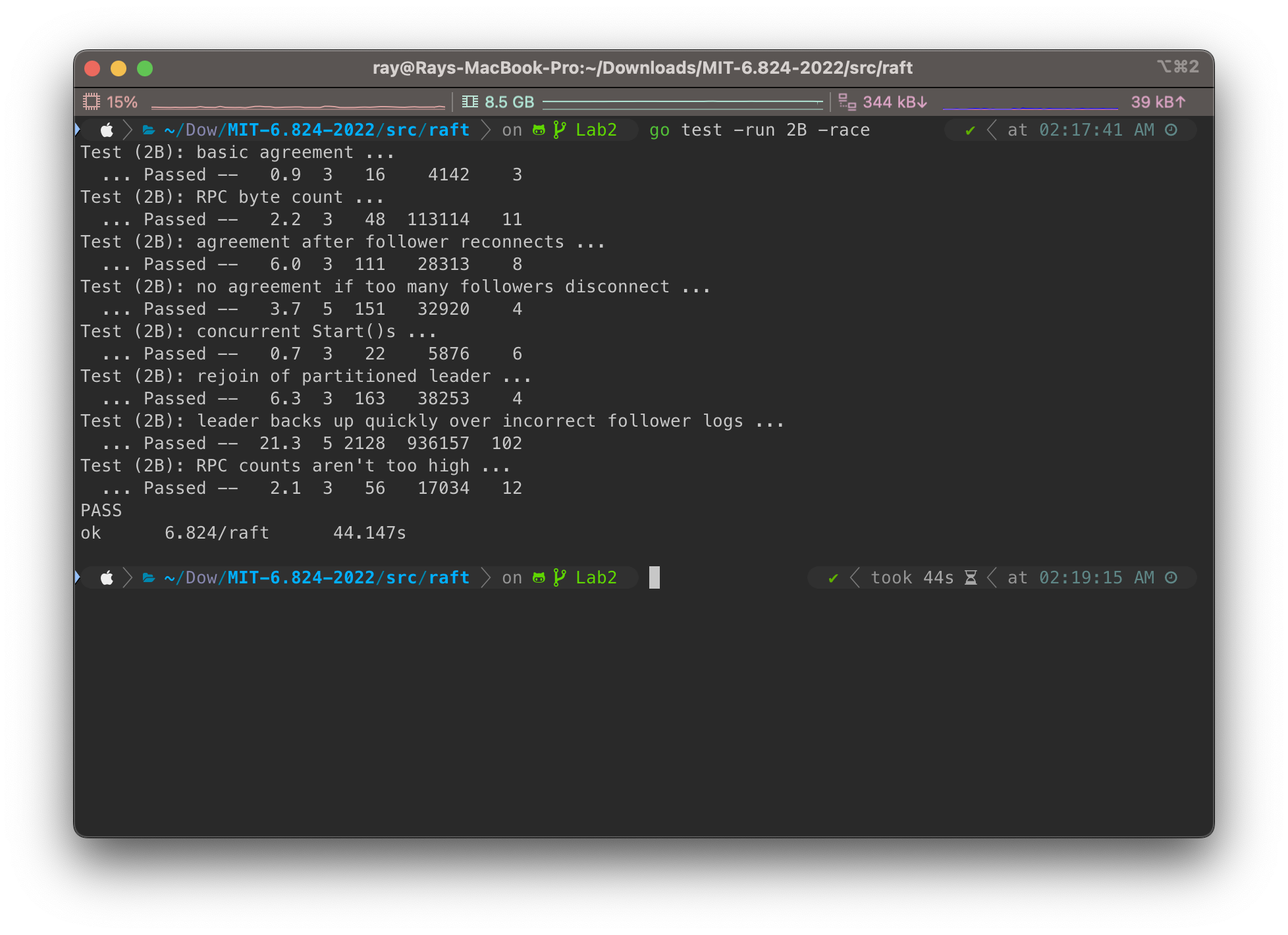
If desired, the protocol can be optimized to reduce the number of rejected AppendEntries RPCs. For example, when rejecting an AppendEntries request, the follower can include the term of the conflicting entry and the first index it stores for that term. With this information, the leader can decrement nextIndex to bypass all of the con-flicting entries in that term; one AppendEntries RPC will be required for each term with conflicting entries, rather than one RPC per entry. In practice, we doubt this opti- mization is necessary, since failures happen infrequently and it is unlikely that there will be many inconsistent en- tries.
XTerm: term in the conflicting entry (if any) XIndex: index of first entry with that term (if any) XLen: log length
Leader节点的逻辑可以处理成:
1 2 3 4 5 6
Case 1: leader doesn't have XTerm: nextIndex = XIndex Case 2: leader has XTerm: nextIndex = leader's last entry for XTerm Case 3: follower's log is too short: nextIndex = XLen
// Get the index of first entry and last entry with the given term. // Return (-1,-1) if no such term is found func(logEntries LogEntries) getBoundsWithTerm(term int) (minIndex int, maxIndex int) { if term == 0 { return0, 0 } minIndex, maxIndex = math.MaxInt, -1 for i := 1; i <= len(logEntries); i++ { if logEntries.getEntry(i).Term == term { minIndex = min(minIndex, i) maxIndex = max(maxIndex, i) } } if maxIndex == -1 { return-1, -1 } return }
type AppendEntriesReply struct { Term int// currentTerm, for leader to update itself XTerm int// term in the conflicting entry (if any) XIndex int// index of first entry with that term (if any) XLen int// log length Success bool// true if follower contained entry matching prevLogIndex and prevLogTerm }
// Reply false if term < currentTerm (§5.1) if args.Term < rf.currentTerm { Debug(dLog2, "S%d Term is lower, rejecting append request. (%d < %d)", rf.me, args.Term, rf.currentTerm) reply.Term = rf.currentTerm return }
// For Candidates. If AppendEntries RPC received from new leader: convert to follower if rf.state == CandidateState && rf.currentTerm == args.Term { rf.state = FollowerState Debug(dLog2, "S%d Convert from candidate to follower at T%d.", rf.me, rf.currentTerm) }
// save Raft's persistent state to stable storage, // where it can later be retrieved after a crash and restart. // see paper's Figure 2 for a description of what should be persistent. func(rf *Raft) persist() { Debug(dPersist, "S%d Saving persistent state to stable storage at T%d.", rf.me, rf.currentTerm) // Your code here (2C). w := new(bytes.Buffer) e := labgob.NewEncoder(w) if err := e.Encode(rf.currentTerm); err != nil { Debug(dError, "Raft.readPersist: failed to decode \"rf.currentTerm\". err: %v, data: %v", err, rf.currentTerm) } if err := e.Encode(rf.votedFor); err != nil { Debug(dError, "Raft.readPersist: failed to decode \"rf.votedFor\". err: %v, data: %v", err, rf.votedFor) } if err := e.Encode(rf.log); err != nil { Debug(dError, "Raft.readPersist: failed to decode \"rf.log\". err: %v, data: %v", err, rf.log) } data := w.Bytes() rf.persister.SaveRaftState(data) }
// restore previously persisted state. func(rf *Raft) readPersist(data []byte) { if data == nil || len(data) < 1 { // bootstrap without any state? return } Debug(dPersist, "S%d Restoring previously persisted state at T%d.", rf.me, rf.currentTerm) // Your code here (2C). r := bytes.NewBuffer(data) d := labgob.NewDecoder(r) rf.mu.Lock() defer rf.mu.Unlock() if err := d.Decode(&rf.currentTerm); err != nil { Debug(dError, "Raft.readPersist: failed to decode \"rf.currentTerm\". err: %v, data: %s", err, data) } if err := d.Decode(&rf.votedFor); err != nil { Debug(dError, "Raft.readPersist: failed to decode \"rf.votedFor\". err: %v, data: %s", err, data) } if err := d.Decode(&rf.log); err != nil { Debug(dError, "Raft.readPersist: failed to decode \"rf.log\". err: %v, data: %s", err, data) } }
// If RPC request or response contains term T > currentTerm: set currentTerm = T, convert to follower (§5.1) // Check if current term is out of date when hearing from other peers, // update term, revert to follower state and return true if necesarry func(rf *Raft) checkTerm(term int) bool { if rf.currentTerm < term { Debug(dTerm, "S%d Term is higher, updating term to T%d, setting state to follower. (%d > %d)", rf.me, term, term, rf.currentTerm) rf.state = FollowerState rf.currentTerm = term rf.votedFor = -1 rf.leaderId = -1 rf.persist() returntrue } returnfalse }
// agreement on the next command to be appended to Raft's log. if this // server isn't the leader, returns false. otherwise start the // agreement and return immediately. there is no guarantee that this // command will ever be committed to the Raft log, since the leader // may fail or lose an election. even if the Raft instance has been killed, // this function should return gracefully. // // the first return value is the index that the command will appear at // if it's ever committed. the second return value is the current // term. the third return value is true if this server believes it is // the leader. func(rf *Raft) Start(command interface{}) (int, int, bool) { index := -1 term := -1 isLeader := true
// Your code here (2B). rf.mu.Lock() defer rf.mu.Unlock() if rf.state != LeaderState { return-1, -1, false } logEntry := LogEntry{ Command: command, Term: rf.currentTerm, } rf.log = append(rf.log, logEntry) index = len(rf.log) term = rf.currentTerm Debug(dLog, "S%d Add command at T%d. LI: %d, Command: %v\n", rf.me, term, index, command) rf.persist() rf.sendEntries(false)
// Reply false if term < currentTerm (§5.1) if args.Term < rf.currentTerm { Debug(dLog2, "S%d Term is lower, rejecting append request. (%d < %d)", rf.me, args.Term, rf.currentTerm) reply.Term = rf.currentTerm return }
// For Candidates. If AppendEntries RPC received from new leader: convert to follower if rf.state == CandidateState && rf.currentTerm == args.Term { rf.state = FollowerState Debug(dLog2, "S%d Convert from candidate to follower at T%d.", rf.me, rf.currentTerm) }
// the service or tester wants to create a Raft server. the ports // of all the Raft servers (including this one) are in peers[]. this // server's port is peers[me]. all the servers' peers[] arrays // have the same order. persister is a place for this server to // save its persistent state, and also initially holds the most // recent saved state, if any. applyCh is a channel on which the // tester or service expects Raft to send ApplyMsg messages. // Make() must return quickly, so it should start goroutines // for any long-running work. funcMake(peers []*labrpc.ClientEnd, me int, persister *Persister, applyCh chan ApplyMsg) *Raft {
// Raft is a Go object implementing a single Raft peer. type Raft struct { mu sync.Mutex // Lock to protect shared access to this peer's state peers []*labrpc.ClientEnd // RPC end points of all peers persister *Persister // Object to hold this peer's persisted state me int// this peer's index into peers[] dead int32// set by Kill()
// Your data here (2A, 2B, 2C). // Look at the paper's Figure 2 for a description of what // state a Raft server must maintain.
leaderId int// the leader server that current server recognizes state State heartbeatTime time.Time electionTime time.Time
// Persistent state on all servers
currentTerm int// latest term server has seen votedFor int// candidateId that received vote in current term log []LogEntry // log entries; each entry contains command for state machine, and term when entry was received by leader
// Volatile state on all servers
commitIndex int// index of highest log entry known to be committed lastApplied int// index of highest log entry applied to state machine applyCh chan ApplyMsg // the channel on which the tester or service expects Raft to send ApplyMsg messages
// Volatile state on leaders (Reinitialized after election)
nextIndex []int// for each server, index of the next log entry to send to that server matchIndex []int// for each server, index of highest log entry known to be replicated on server
// Snapshot state on all servers lastIncludedIndex int// the snapshot replaces all entries up through and including this index, entire log up to the index discarded lastIncludedTerm int// term of lastIncludedIndex }
// LogEntry is a Go object implementing raft log entry type LogEntry struct { Command interface{} // Command to be executed Term int// Term number when created }
// Get the entry with the given index. // Index and term of *valid* entries start from 1. // If no *valid* entry is found, return an empty entry with term equal to -1. // If log is too short, also return an empty entry with term equal to -1. // Panic if the index of the log entry is already in the snapshot and unable to get from memory. func(rf *Raft) getEntry(index int) *LogEntry { logEntries := rf.log logIndex := index - rf.lastIncludedIndex if logIndex < 0 { log.Panicf("LogEntries.getEntry: index too small. (%d < %d)", index, rf.lastIncludedIndex) } if logIndex == 0 { return &LogEntry{ Command: nil, Term: rf.lastIncludedTerm, } } if logIndex > len(logEntries) { return &LogEntry{ Command: nil, Term: -1, } } return &logEntries[logIndex-1] }
// Get the index and term of the last entry. // Return (0, 0) if the log is empty. func(rf *Raft) lastLogInfo() (index, term int) { logEntries := rf.log index = len(logEntries) + rf.lastIncludedIndex logEntry := rf.getEntry(index) return index, logEntry.Term }
// Get the slice of the log with index from startIndex to endIndex. // startIndex included and endIndex excluded, therefore startIndex should be no greater than endIndex. func(rf *Raft) getSlice(startIndex, endIndex int) []LogEntry { logEntries := rf.log logStartIndex := startIndex - rf.lastIncludedIndex logEndIndex := endIndex - rf.lastIncludedIndex if logStartIndex <= 0 { Debug(dError, "LogEntries.getSlice: startIndex out of range. startIndex: %d, len: %d.", startIndex, len(logEntries)) log.Panicf("LogEntries.getSlice: startIndex out of range. (%d < %d)", startIndex, rf.lastIncludedIndex) } if logEndIndex > len(logEntries)+1 { Debug(dError, "LogEntries.getSlice: endIndex out of range. endIndex: %d, len: %d.", endIndex, len(logEntries)) log.Panicf("LogEntries.getSlice: endIndex out of range. (%d > %d)", endIndex, len(logEntries)+1+rf.lastIncludedIndex) } if logStartIndex > logEndIndex { Debug(dError, "LogEntries.getSlice: startIndex > endIndex. (%d > %d)", startIndex, endIndex) log.Panicf("LogEntries.getSlice: startIndex > endIndex. (%d > %d)", startIndex, endIndex) } returnappend([]LogEntry(nil), logEntries[logStartIndex-1:logEndIndex-1]...) }
// Get the index of first entry and last entry with the given term. // Return (-1,-1) if no such term is found func(rf *Raft) getBoundsWithTerm(term int) (minIndex int, maxIndex int) { logEntries := rf.log if term == 0 { return0, 0 } minIndex, maxIndex = math.MaxInt, -1 for i := rf.lastIncludedIndex + 1; i <= rf.lastIncludedIndex+len(logEntries); i++ { if rf.getEntry(i).Term == term { minIndex = min(minIndex, i) maxIndex = max(maxIndex, i) } } if maxIndex == -1 { return-1, -1 } return }
// save Raft's persistent state to stable storage, // where it can later be retrieved after a crash and restart. // see paper's Figure 2 for a description of what should be persistent. func(rf *Raft) persist() { Debug(dPersist, "S%d Saving persistent state to stable storage at T%d.", rf.me, rf.currentTerm) // Your code here (2C). w := new(bytes.Buffer) e := labgob.NewEncoder(w) if err := e.Encode(rf.currentTerm); err != nil { Debug(dError, "Raft.persist: failed to encode \"rf.currentTerm\". err: %v, data: %v", err, rf.currentTerm) } if err := e.Encode(rf.votedFor); err != nil { Debug(dError, "Raft.persist: failed to encode \"rf.votedFor\". err: %v, data: %v", err, rf.votedFor) } if err := e.Encode(rf.log); err != nil { Debug(dError, "Raft.persist: failed to encode \"rf.log\". err: %v, data: %v", err, rf.log) } if err := e.Encode(rf.lastIncludedIndex); err != nil { Debug(dError, "Raft.persist: failed to encode \"rf.lastIncludedIndex\". err: %v, data: %v", err, rf.lastIncludedIndex) } if err := e.Encode(rf.lastIncludedTerm); err != nil { Debug(dError, "Raft.persist: failed to encode \"rf.lastIncludedTerm\". err: %v, data: %v", err, rf.lastIncludedTerm) } data := w.Bytes() rf.persister.SaveRaftState(data) }
// restore previously persisted state. func(rf *Raft) readPersist(data []byte) { if data == nil || len(data) < 1 { // bootstrap without any state? return } Debug(dPersist, "S%d Restoring previously persisted state at T%d.", rf.me, rf.currentTerm) // Your code here (2C). r := bytes.NewBuffer(data) d := labgob.NewDecoder(r) rf.mu.Lock() defer rf.mu.Unlock() if err := d.Decode(&rf.currentTerm); err != nil { Debug(dError, "Raft.readPersist: failed to decode \"rf.currentTerm\". err: %v, data: %s", err, data) } if err := d.Decode(&rf.votedFor); err != nil { Debug(dError, "Raft.readPersist: failed to decode \"rf.votedFor\". err: %v, data: %s", err, data) } if err := d.Decode(&rf.log); err != nil { Debug(dError, "Raft.readPersist: failed to decode \"rf.log\". err: %v, data: %s", err, data) } if err := d.Decode(&rf.lastIncludedIndex); err != nil { Debug(dError, "Raft.readPersist: failed to decode \"rf.lastIncludedIndex\". err: %v, data: %s", err, data) } if err := d.Decode(&rf.lastIncludedTerm); err != nil { Debug(dError, "Raft.readPersist: failed to decode \"rf.lastIncludedTerm\". err: %v, data: %s", err, data) } }
// Raft is a Go object implementing a single Raft peer. type Raft struct { mu sync.Mutex // Lock to protect shared access to this peer's state peers []*labrpc.ClientEnd // RPC end points of all peers persister *Persister // Object to hold this peer's persisted state me int// this peer's index into peers[] dead int32// set by Kill()
// Your data here (2A, 2B, 2C). // Look at the paper's Figure 2 for a description of what // state a Raft server must maintain.
leaderId int// the leader server that current server recognizes state State heartbeatTime time.Time electionTime time.Time
// Persistent state on all servers
currentTerm int// latest term server has seen votedFor int// candidateId that received vote in current term log []LogEntry // log entries; each entry contains command for state machine, and term when entry was received by leader
// Volatile state on all servers
commitIndex int// index of highest log entry known to be committed lastApplied int// index of highest log entry applied to state machine applyCh chan ApplyMsg // the channel on which the tester or service expects Raft to send ApplyMsg messages
// Volatile state on leaders (Reinitialized after election)
nextIndex []int// for each server, index of the next log entry to send to that server matchIndex []int// for each server, index of highest log entry known to be replicated on server
// Snapshot state on all servers lastIncludedIndex int// the snapshot replaces all entries up through and including this index, entire log up to the index discarded lastIncludedTerm int// term of lastIncludedIndex snapshot []byte// snapshot stored in memory }
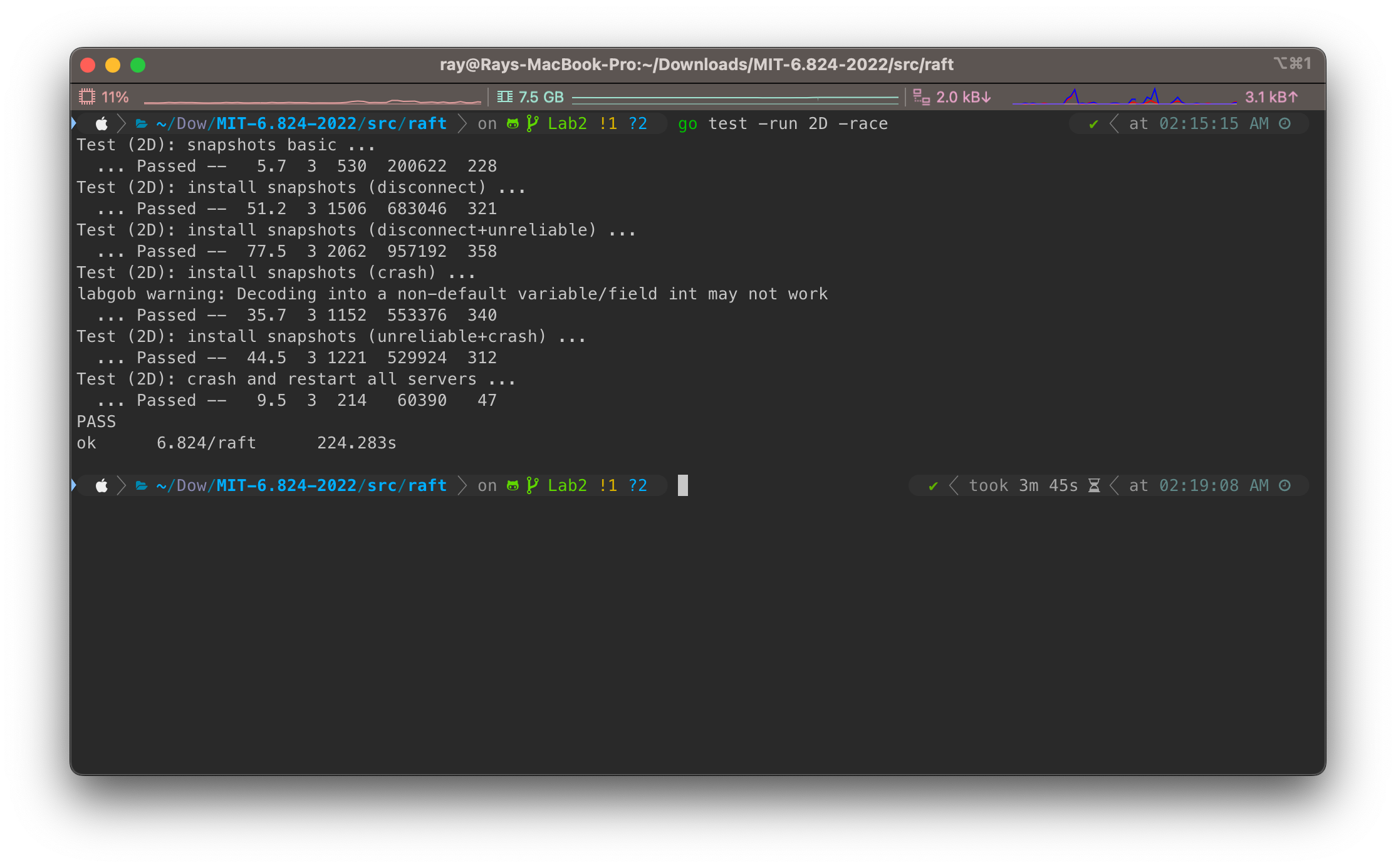
// Snapshot is the service says it has created a snapshot that has // all info up to and including index. this means the // service no longer needs the log through (and including) // that index. Raft should now trim its log as much as possible. func(rf *Raft) Snapshot(index int, snapshot []byte) { // Your code here (2D). Debug(dSnap, "S%d Snapshotting through index %d.", rf.me, index) rf.mu.Lock() defer rf.mu.Unlock() lastLogIndex, _ := rf.lastLogInfo() if rf.lastIncludedIndex >= index { Debug(dSnap, "S%d Snapshot already applied to persistent storage. (%d >= %d)", rf.me, rf.lastIncludedIndex, index) return } if rf.commitIndex < index { Debug(dWarn, "S%d Cannot snapshot uncommitted log entries, discard the call. (%d < %d)", rf.me, rf.commitIndex, index) return } newLog := rf.getSlice(index+1, lastLogIndex+1) newLastIncludeTerm := rf.getEntry(index).Term
// InstallSnapshotArgs is the InstallSnapshot RPC arguments structure. // field names must start with capital letters! type InstallSnapshotArgs struct { Term int// leader's term LeaderId int// so follower can redirect clients LastIncludedIndex int// the snapshot replaces all entries up through and including this index LastIncludedTerm int// term of lastIncludedIndex Data []byte// raw bytes of the snapshot chunk, starting at offset }
// InstallSnapshotReply is the InstallSnapshot RPC reply structure. // field names must start with capital letters! type InstallSnapshotReply struct { Term int// currentTerm, for leader to update itself }
func(rf *Raft) applyLogsLoop() { for !rf.killed() { // Apply logs periodically until the last committed index. rf.mu.Lock() // To avoid the apply operation getting blocked with the lock held, // use a slice to store all committed messages to apply, and apply them only after unlocked var appliedMsgs []ApplyMsg for rf.commitIndex > rf.lastApplied { rf.lastApplied++ appliedMsgs = append(appliedMsgs, ApplyMsg{ CommandValid: true, Command: rf.getEntry(rf.lastApplied).Command, CommandIndex: rf.lastApplied, }) Debug(dLog2, "S%d Applying log at T%d. LA: %d, CI: %d.", rf.me, rf.currentTerm, rf.lastApplied, rf.commitIndex) } rf.mu.Unlock() for _, msg := range appliedMsgs { rf.applyCh <- msg } time.Sleep(time.Duration(TickInterval) * time.Millisecond) } }
// Raft is a Go object implementing a single Raft peer. type Raft struct { mu sync.Mutex // Lock to protect shared access to this peer's state peers []*labrpc.ClientEnd // RPC end points of all peers persister *Persister // Object to hold this peer's persisted state me int// this peer's index into peers[] dead int32// set by Kill()
// Your data here (2A, 2B, 2C). // Look at the paper's Figure 2 for a description of what // state a Raft server must maintain.
leaderId int// the leader server that current server recognizes state State heartbeatTime time.Time electionTime time.Time
// Persistent state on all servers
currentTerm int// latest term server has seen votedFor int// candidateId that received vote in current term log []LogEntry // log entries; each entry contains command for state machine, and term when entry was received by leader
// Volatile state on all servers
commitIndex int// index of highest log entry known to be committed lastApplied int// index of highest log entry applied to state machine applyCh chan ApplyMsg // the channel on which the tester or service expects Raft to send ApplyMsg messages
// Volatile state on leaders (Reinitialized after election)
nextIndex []int// for each server, index of the next log entry to send to that server matchIndex []int// for each server, index of highest log entry known to be replicated on server
// Snapshot state on all servers lastIncludedIndex int// the snapshot replaces all entries up through and including this index, entire log up to the index discarded lastIncludedTerm int// term of lastIncludedIndex snapshot []byte// snapshot stored in memory
// Temporary location to give the service snapshot to the apply thread // All apply messages should be sent in one go routine, we need the temporary space for applyLogsLoop to handle the snapshot apply waitingIndex int// lastIncludedIndex to be sent to applyCh waitingTerm int// lastIncludedTerm to be sent to applyCh waitingSnapshot []byte// snapshot to be sent to applyCh }
func(rf *Raft) applyLogsLoop() { for !rf.killed() { // Apply logs periodically until the last committed index. rf.mu.Lock() // To avoid the apply operation getting blocked with the lock held, // use a slice to store all committed messages to apply, and apply them only after unlocked var appliedMsgs []ApplyMsg
// InstallSnapshot sends an apply message with the snapshot to applyCh. // The state machine should cooperate with raft code later to decide whether to install the snapshot using CondInstallSnapshot function. // No snapshot related status in raft code should be changed right now, // which could result in inconsistency between the status machine and raft code, as the snapshot is not applied immediately. func(rf *Raft) InstallSnapshot(args *InstallSnapshotArgs, reply *InstallSnapshotReply) { rf.mu.Lock() defer rf.mu.Unlock() Debug(dSnap, "S%d <- S%d Received install snapshot request at T%d.", rf.me, args.LeaderId, rf.currentTerm)
if args.Term < rf.currentTerm { Debug(dSnap, "S%d Term is lower, rejecting install snapshot request. (%d < %d)", rf.me, args.Term, rf.currentTerm) reply.Term = rf.currentTerm return } rf.checkTerm(args.Term) reply.Term = rf.currentTerm
Debug(dTimer, "S%d Resetting ELT, wait for next potential heartbeat timeout.", rf.me) rf.setElectionTimeout(randHeartbeatTimeout())
// All apply messages should be sent in one go routine (applyLogsLoop), // otherwise the apply action could be out of order, where the snapshot apply could cut in line when the command apply is running. if rf.waitingIndex >= args.LastIncludedIndex { Debug(dSnap, "S%d A newer snapshot already exists, rejecting install snapshot request. (%d <= %d)", rf.me, args.LastIncludedIndex, rf.waitingIndex) return } rf.leaderId = args.LeaderId rf.waitingSnapshot = args.Data rf.waitingIndex = args.LastIncludedIndex rf.waitingTerm = args.LastIncludedTerm }
// CondInstallSnapshot returns if the service wants to switch to snapshot. // Only do so if Raft hasn't had more recent info since it communicate the snapshot on applyCh. func(rf *Raft) CondInstallSnapshot(lastIncludedTerm int, lastIncludedIndex int, snapshot []byte) bool { // Your code here (2D). rf.mu.Lock() defer rf.mu.Unlock() Debug(dSnap, "S%d Installing the snapshot. LLI: %d, LLT: %d", rf.me, lastIncludedIndex, lastIncludedTerm) lastLogIndex, _ := rf.lastLogInfo() if rf.commitIndex >= lastIncludedIndex { Debug(dSnap, "S%d Log entries is already up-to-date with the snapshot. (%d >= %d)", rf.me, rf.commitIndex, lastIncludedIndex) returnfalse } if lastLogIndex >= lastIncludedIndex { rf.log = rf.getSlice(lastIncludedIndex+1, lastLogIndex+1) } else { rf.log = []LogEntry{} } rf.lastIncludedIndex = lastIncludedIndex rf.lastIncludedTerm = lastIncludedTerm rf.lastApplied = lastIncludedIndex rf.commitIndex = lastIncludedIndex rf.snapshot = snapshot rf.persistAndSnapshot(snapshot) returntrue }
func(rf *Raft) leaderSendEntries(args *AppendEntriesArgs, server int) { reply := &AppendEntriesReply{} ok := rf.sendAppendEntries(server, args, reply) if ok { rf.mu.Lock() defer rf.mu.Unlock() Debug(dLog, "S%d <- S%d Received send entry reply at T%d.", rf.me, server, rf.currentTerm) if reply.Term < rf.currentTerm { Debug(dLog, "S%d Term lower, invalid send entry reply. (%d < %d)", rf.me, reply.Term, rf.currentTerm) return } if rf.currentTerm != args.Term { Debug(dWarn, "S%d Term has changed after the append request, send entry reply discarded. "+ "requestTerm: %d, currentTerm: %d.", rf.me, args.Term, rf.currentTerm) return } if rf.checkTerm(reply.Term) { return } // If successful: update nextIndex and matchIndex for follower (§5.3) if reply.Success { Debug(dLog, "S%d <- S%d Log entries in sync at T%d.", rf.me, server, rf.currentTerm) newNext := args.PrevLogIndex + 1 + len(args.Entries) newMatch := args.PrevLogIndex + len(args.Entries) rf.nextIndex[server] = max(newNext, rf.nextIndex[server]) rf.matchIndex[server] = max(newMatch, rf.matchIndex[server]) // If there exists an N such that N > commitIndex, a majority of matchIndex[i] ≥ N, // and log[N].term == currentTerm: set commitIndex = N (§5.3, §5.4). for N := rf.lastIncludedIndex + len(rf.log); N > rf.commitIndex && rf.getEntry(N).Term == rf.currentTerm; N-- { count := 1 for peer, matchIndex := range rf.matchIndex { if peer == rf.me { continue } if matchIndex >= N { count++ } } if count > len(rf.peers)/2 { rf.commitIndex = N Debug(dCommit, "S%d Updated commitIndex at T%d for majority consensus. CI: %d.", rf.me, rf.currentTerm, rf.commitIndex) break } } } else { // If AppendEntries fails because of log inconsistency: decrement nextIndex and retry (§5.3) // the optimization that backs up nextIndex by more than one entry at a time if reply.XTerm == -1 { // follower's log is too short rf.nextIndex[server] = reply.XLen + 1 } else { _, maxIndex := rf.getBoundsWithTerm(reply.XTerm) if maxIndex != -1 { // leader has XTerm rf.nextIndex[server] = maxIndex } else { // leader doesn't have XTerm rf.nextIndex[server] = reply.XIndex } } lastLogIndex, _ := rf.lastLogInfo() nextIndex := rf.nextIndex[server] if nextIndex <= rf.lastIncludedIndex { // current leader does not have enough log to sync the outdated peer, // because logs were cleared after the snapshot, then send an InstallSnapshot RPC instead rf.sendSnapshot(server) } elseif lastLogIndex >= nextIndex { Debug(dLog, "S%d <- S%d Inconsistent logs, retrying.", rf.me, server) newArg := &AppendEntriesArgs{ Term: rf.currentTerm, LeaderId: rf.me, PrevLogIndex: nextIndex - 1, PrevLogTerm: rf.getEntry(nextIndex - 1).Term, Entries: rf.getSlice(nextIndex, lastLogIndex+1), } go rf.leaderSendEntries(newArg, server) } } } }
// Reply false if term < currentTerm (§5.1) if args.Term < rf.currentTerm { Debug(dLog2, "S%d Term is lower, rejecting append request. (%d < %d)", rf.me, args.Term, rf.currentTerm) reply.Term = rf.currentTerm return }
// For Candidates. If AppendEntries RPC received from new leader: convert to follower if rf.state == CandidateState && rf.currentTerm == args.Term { rf.state = FollowerState Debug(dLog2, "S%d Convert from candidate to follower at T%d.", rf.me, rf.currentTerm) }