课程相关的资源、视频和教材见Lab util: Unix utilities 开头。
总算来到文件系统这一节了,相比之前的虚拟地址和并发编程各种狂轰乱炸,现在应该好多了…
在这个Lab中,我们将为xv6的文件系统实现大文件以及添加符号链接。
感觉FK和Morris大神都讲的很好,信息量有点大,又恰到好处…
准备
对应课程
本次的作业是Lab FS,我们将修改xv6相关代码,使得其文件系统支持更大的文件,并实现符号链接功能。
按照课程进度,我们需要看掉课程的Lecture 14, 15, 16,也就是B站课程 的P13, P14, P15,同时我们需要阅读PDF中的第八章File system。
系统环境
使用Arch Linux虚拟机作为实验环境… 2022/10已经喜提Linux 6.0 kernel,不愧是Arch发行版…
环境依赖配置,编译使用make qemu等,如遇到问题,见第一次的Lab util: Unix utilities
使用准备
参考本次的实验说明书:Lab fs: File system
从仓库clone下来课程文件:
1 git clone git://g.csail.mit.edu/xv6-labs-2021
切换到本次作业的fs分支即可:
1 2 cd xv6-labs-2021 git checkout fs
在作业完成后可以使用make grade对所有结果进行评分。
题目
大文件实现
要求和提示
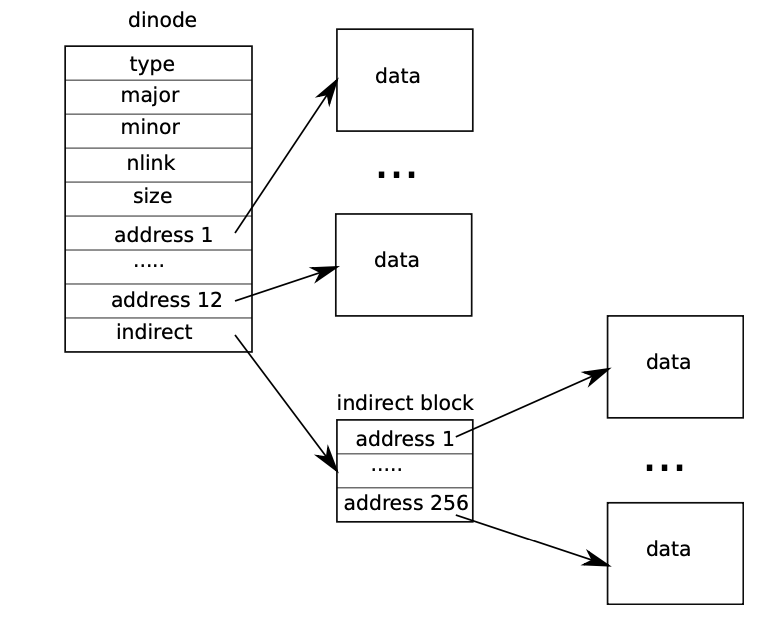
在这个部分中,我们将为xv6提高其文件系统所能支持的最大文件大小。当前xv6所支持的最大文件大小被限制在268个块,也就是268*BSIZE个字节(在xv6中BSIZE块内存大小为1024)。这个限制的原因来自在xv6的inode中,存储有12个“直接”块编号和一个“间接”块编号,在“间接”块编号指向的块中又可以存储256个块编号。因此,一个文件最多可以对应12 + 256 = 268 12+256=268 12 + 256 = 268
这是在PDF中图8.3,很好的表示了这一结构:
在这部分作业中,我们将使用bigfile进行测试能创建的最大文件,如果我们暂时还没有对当前xv6修改,我们会获得这样的结果:
1 2 3 4 5 $ bigfile .. wrote 268 blocks bigfile: file is too small $
我们的测试失败的原因是因为,测试要求我们能够创建一个拥有65803个块的文件,但是目前xv6只支持到268个块。
为此我们需要更改xv6的文件系统代码来实现这一点,我们需要在每个inode中实现一个二级“间接”块,也就是在二级“间接”块编号指向的256字节块中再填入256个“间接”块编号。最终我们的文件大小为65803个块,也就是256 × 256 + 256 + 11 256\times256+256+11 256 × 256 + 256 + 11
在此之前我们还有一些信息需要了解:
mkfs程序创建了xv6的文件系统镜像,并决定了整个文件系统总共拥有多少个文件块。这个大小是由kernel/param.h中的FSSIZE来控制的,我们通过查看代码很容易发现在这个Lab中文件系统的总共拥有200000个文件块。我们在主目录下尝试make qemu的过程中也会见到mkfs/mkfs产生的输出:
1 nmeta 70 (boot, super, log blocks 30 inode blocks 13, bitmap blocks 25) blocks 199930 total 200000
这行信息描述了mkfs/mkfs中创建的文件系统:这其中含有70个元数据块(用于描述文件系统的文件块),以及199930个数据文件块,总共200000个文件块。
请注意如果我们在Lab中有需要重建文件系统,我们需要在主目录下运行make clean强制重建fs.img镜像。
现在让我们回到代码上来,磁盘中的inode格式被定义在kernel/fs.h中的结构体struct dinode:
1 2 3 4 5 6 7 8 9 10 11 12 13 #define NDIRECT 12 #define NINDIRECT (BSIZE / sizeof(uint)) #define MAXFILE (NDIRECT + NINDIRECT) struct dinode { short type; short major; short minor; short nlink; uint size; uint addrs[NDIRECT+1 ]; };
这个结构与书中8.3的结构体对应。
此外,我们可以在kernel/fs.c中的bmp()中找到在磁盘中查找文件传输数据功能的代码,请仔细阅读。我们在读取或者写入文件时都会调用bmap()。在写入时,bmap()会根据需要分配新的块来保存文件内容,如果需要的话,也会分配一个“间接”块来保存块地址。
bmap()会处理两种类型的块编号。其中,bn参数是一个 “逻辑块号”,也就是文件中的块号,相对于文件的开始位置。ip->addrs[]中的块编号,以及bread()的参数,是磁盘块编号。我们可以把bmap()看作是将文件的逻辑块号映射成磁盘块号。
我们的目标是修改bmap()时期除了”直接“块和“间接”块以外还能实现二级“间接”块,根据刚才给出的设定,我们设置11个“直接”块,而不是12个,以便为我们的二级“间接”块腾出空间,且我们不能改变磁盘上一个inode 的大小。ip->addrs[]的前11个元素应该是“直接”块,第12个应该是“间接”块(就像当前的一样),第13个应该是二级“间接”块。
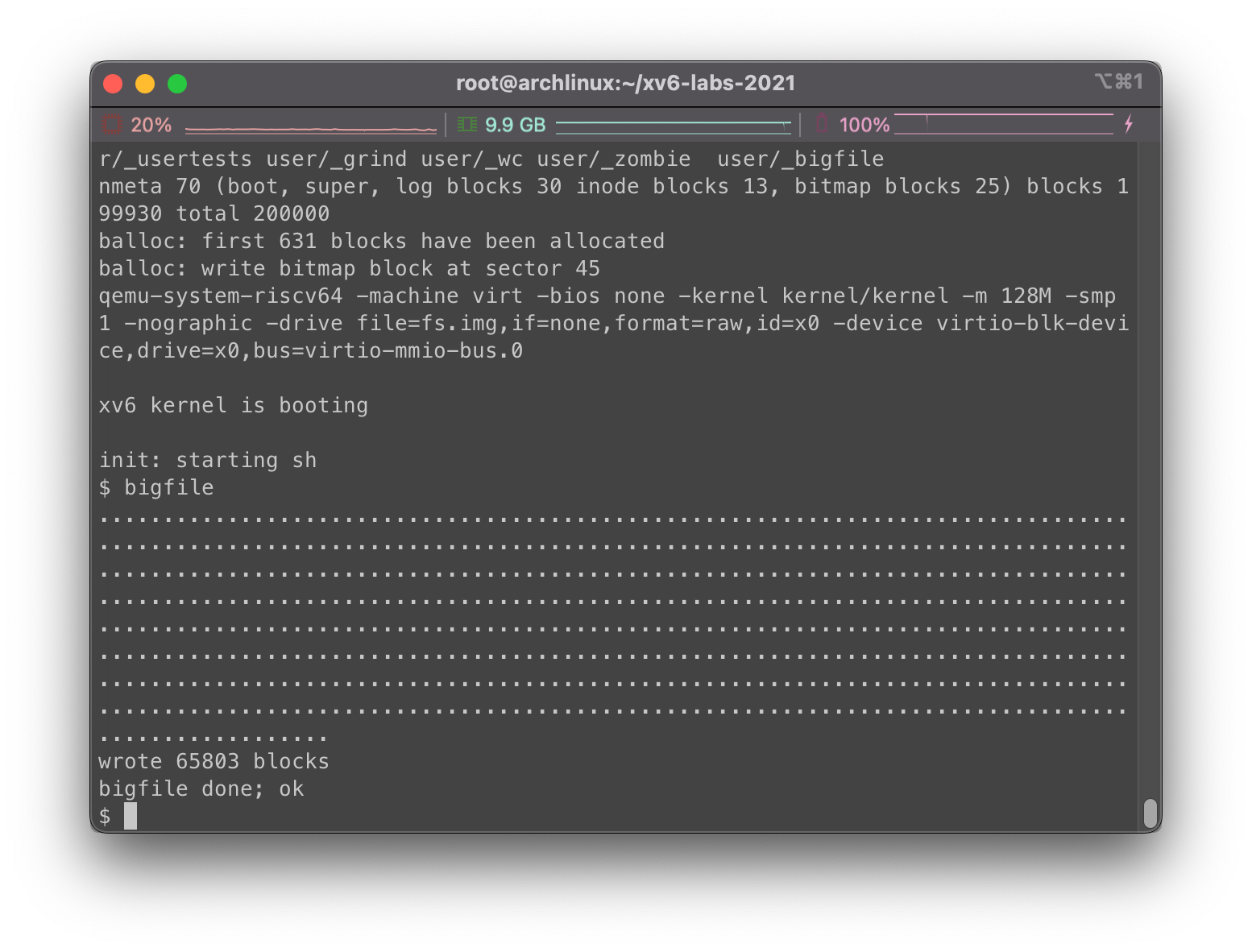
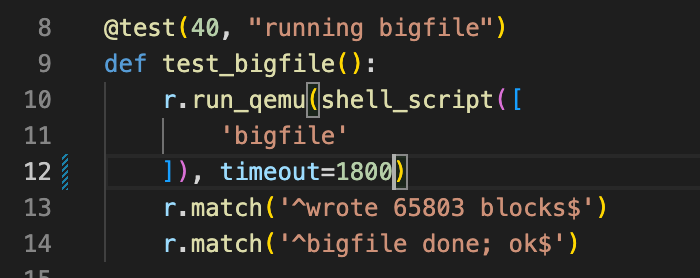
如下为bigfile成功运行示例,注意bigfile至少需要一分半钟运行时间,请耐心等待:
1 2 3 4 5 $ bigfile .................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................. wrote 65803 blocks done; ok $
相关提示:
确保你理解了bmap()的代码内容,并尝试画出ip->addrs[],“间接”块、二级“间接”块和它所指向的“间接”块以及数据块之间的关系图,以辅助理解。
思考一下我们怎样来使用逻辑块号来索引二级“间接”块,以及其指向的“间接”块。那就按照顺序往下数呗…
如果你改变了NDIRECT的定义,我们可能需要改变kernel/file.h结构体struct inode中addrs[]的声明。确保inode结构和dinode结构在其addrs[]数组中有相同数量的元素。
如果你改变了NDIRECT的定义,确保重建了fs.img镜像,因为mkfs程序会使用NDIRECT作为参数来构建文件系统。
如果你的文件系统发生了一些异常情况,例如崩溃,请在主目录下删除fs.img(在Unix里面做这个,而不是qemu下的xv6),make会重建一个新的文件系统镜像。
对于每个文件块,在bread()之后不要忘记进行brelse()。
我们只有在必要的时候才选择分配“间接”块和二级“间接”块,逻辑应当和原版的bmap()类似。
确保itruc能够释放一个文件中所有数据块,包括二级“间接”块。
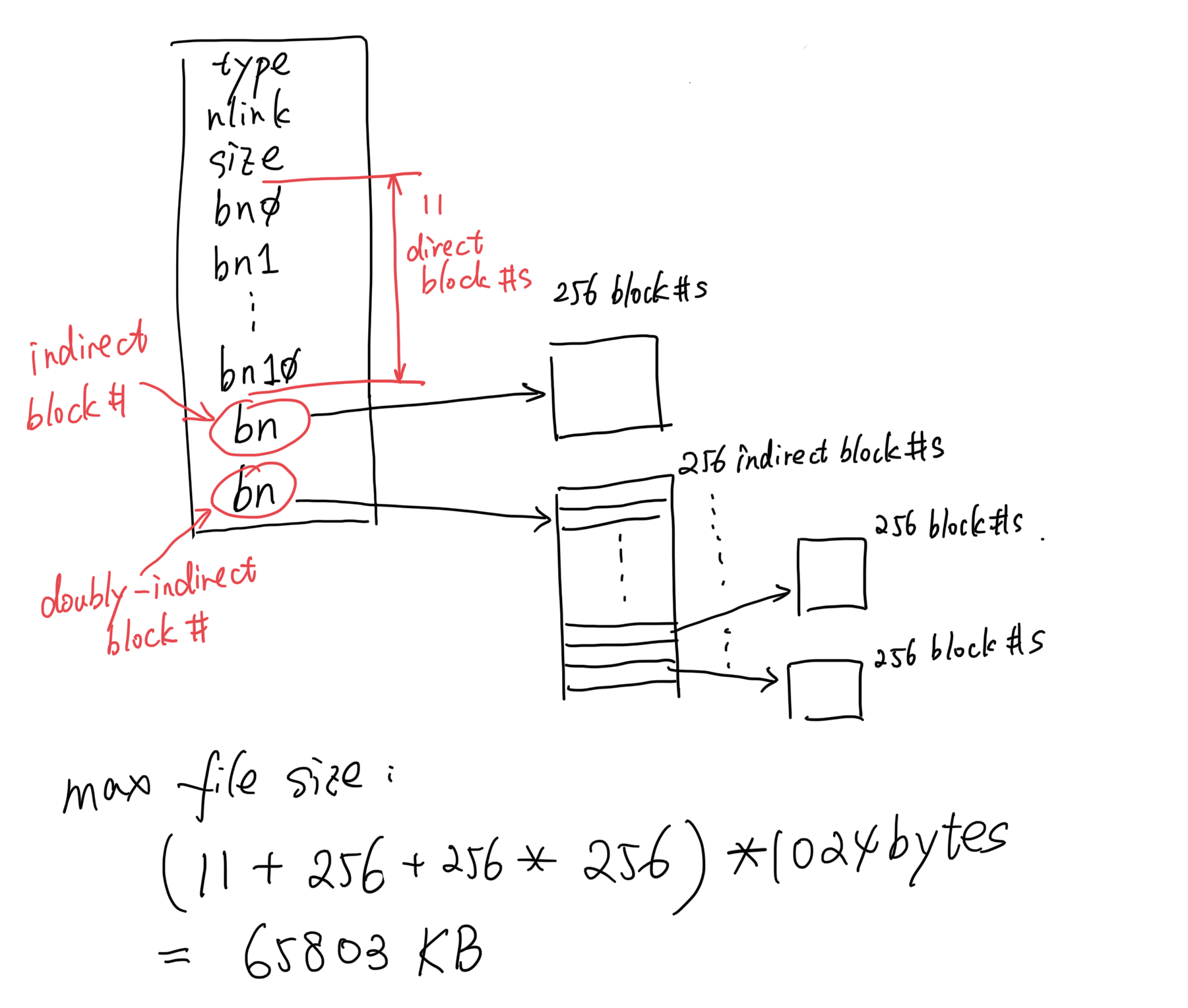
dinode和inode定义修改虽然在一个inode中目前还是13个块,但是现在的结构我们做出了一点小改变,现在的inode结构图刚才已经画过了,这里再挂一下:
依据这张图,我们对kernel/fs.h中的结构体struct dinode进行小幅度修改:
1 2 3 4 5 6 7 8 9 10 11 12 13 #define NDIRECT 11 #define NINDIRECT (BSIZE / sizeof(uint)) #define MAXFILE (NDIRECT + NINDIRECT + NINDIRECT * NINDIRECT) struct dinode { short type; short major; short minor; short nlink; uint size; uint addrs[NDIRECT+2 ]; };
这里也不难看到,我们将NDIRECT修改为11,表示为11个“直接”块,同时将addrs[]大小修改为NDIRECT+2,很明显前11个为“直接”块,接下来一个是“间接”块,然后是二级“间接”块(先放“间接”块再放二级“间接”块,这样从小到大,不够了再上更大的拓展块,开销更加合理)。
由于我们更改了NDIRECT等定义,我们也需要顺道去kernel/file.h结构体struct inode下进行修改,这里存储的是内存中的inode数据结构定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 struct inode { uint dev; uint inum; int ref; struct sleeplock lock ; int valid; short type; short major; short minor; short nlink; uint size; uint addrs[NDIRECT+2 ]; };
我们仅需将addrs[]大小修改为NDIRECT+2
bmap查询函数修改原先的逻辑中,我们在bmap中先看当前的bn位置是否超过了“直接”块能处理的范围,如果超过了再用“间接”块来进行处理。
现在我们无非在这段后面再追加一段逻辑,用来处理二级“间接块”即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 static uintbmap (struct inode *ip, uint bn) { uint addr, *a; struct buf *bp ; if (bn < NDIRECT){ if ((addr = ip->addrs[bn]) == 0 ) ip->addrs[bn] = addr = balloc(ip->dev); return addr; } bn -= NDIRECT; if (bn < NINDIRECT){ if ((addr = ip->addrs[NDIRECT]) == 0 ) ip->addrs[NDIRECT] = addr = balloc(ip->dev); bp = bread(ip->dev, addr); a = (uint*)bp->data; if ((addr = a[bn]) == 0 ){ a[bn] = addr = balloc(ip->dev); log_write(bp); } brelse(bp); return addr; } bn -= NINDIRECT; if (bn < NINDIRECT * NINDIRECT){ int index = bn / NINDIRECT; int offset = bn % NINDIRECT; if ((addr = ip->addrs[NDIRECT + 1 ]) == 0 ) ip->addrs[NDIRECT + 1 ] = addr = balloc(ip->dev); bp = bread(ip->dev, addr); a = (uint*)bp->data; if ((addr = a[index]) == 0 ){ a[index] = addr = balloc(ip->dev); log_write(bp); } brelse(bp); bp = bread(ip->dev, addr); a = (uint*)bp->data; if ((addr = a[offset]) == 0 ){ a[offset] = addr = balloc(ip->dev); log_write(bp); } brelse(bp); return addr; } panic("bmap: out of range" ); }
itruc文件释放函数修改在kernel/fs.c下的itruc()函数中,我们也需要进行修改以适应当前的数据结构。
原先的功能也类似,很好理解,我们先查看“直接”块中的数据并尝试对对应的数据块进行释放。随后是“间接”块,内容其实大差不差,我们不过是遍历“间接”块中间的数据块编号。
现在我们需要在这段代码末尾添加一段逻辑来释放二级“间接”块,好吧,那就继续套娃…
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 void itrunc (struct inode *ip) { int i, j, k; struct buf *bp , *ibp ; uint *a, *b; for (i = 0 ; i < NDIRECT; i++){ if (ip->addrs[i]){ bfree(ip->dev, ip->addrs[i]); ip->addrs[i] = 0 ; } } if (ip->addrs[NDIRECT]){ bp = bread(ip->dev, ip->addrs[NDIRECT]); a = (uint*)bp->data; for (j = 0 ; j < NINDIRECT; j++){ if (a[j]) bfree(ip->dev, a[j]); } brelse(bp); bfree(ip->dev, ip->addrs[NDIRECT]); ip->addrs[NDIRECT] = 0 ; } if (ip->addrs[NDIRECT + 1 ]){ bp = bread(ip->dev, ip->addrs[NDIRECT + 1 ]); a = (uint*)bp->data; for (j = 0 ; j < NINDIRECT; j++){ if (a[j]){ ibp = bread(ip->dev, a[j]); b = (uint*)ibp->data; for (k = 0 ; k < NINDIRECT; k++){ if (b[k]) bfree(ip->dev, b[k]); } brelse(ibp); bfree(ip->dev, a[j]); } } brelse(bp); bfree(ip->dev, ip->addrs[NDIRECT + 1 ]); ip->addrs[NDIRECT + 1 ] = 0 ; } ip->size = 0 ; iupdate(ip); }
测试
我们在主目录下执行make clean; make qemu,然后在xv6中执行bigfile,可以看到成功写入了65803个文件块:
符号链接实现
要求和提示
在这一部分中,我们将为xv6添加符号链接(软链接)功能。符号链接通过路径名指向一个被链接的文件;当一个符号链接被打开时,内核会跟踪符号链接访问对应的文件。符号链接类似于硬链接,但是硬链接只仅限于指向同一磁盘的文件,而符号链接可以跨越磁盘。虽然xv6不支持多设备,但是实现这个系统调用是一个很好的练习,可以帮助我们了解路径名查询的工作原理。
我们的目标是实现系统调用symlink(char *target, char *path),他将在指定路径上创建一个新的符号链接,指向由目标命名的文件。想了解更多用法,我们可以查看symlink的man页面。为了测试symlink系统调用,我们需要向主目录下Makefile文件中加入symlinktest(添加系统调用的基操,忘记了的话去重温下Lab Syscall)。成功的symlinktest运行结果示例如下:
1 2 3 4 5 6 7 8 9 $ symlinktest Start: test symlinks test symlinks: ok Start: test concurrent symlinks test concurrent symlinks: ok $ usertests ... ALL TESTS PASSED $
相关提示:
首先,为symlink创建一个新的系统调用编号,在user/usys.pl和user/user.h中添加条目,并在kernel/sysfile.c中实现sys_symlink。(不记得的强烈建议重新去看一下Lab Syscall)
向kernel/stat.h中添加一个新的文件类型T_SYMLINK,以表示符号链接。
我们需要在kernel/fcntl.h中添加一个新的标志O_NOFOLLOW,我们可以与open系统调用一起使用。请注意,传递给open的标志是按照位检测的,所以新标志不应当与现有的标志位重叠。在添加标志位之后,只要我们将symlinktest加入到Makefile中,user/symlinktest.c就可以顺利通过编译。
我们将实现symlink(target, path)系统调用,在指定目录下创建一个指向目标的新符号链接。需要注意的是,系统调用的成功并不需要目标的存在。因此,我们需要选择一个地方来存储符号链接的目标路径(例如,在inode下的数据块中)。最后symlink应当返回一个整数,代表成功(0)或者失败(-1),类似于link和unlink。
我们需要修改open系统调用,以处理路径指向符号链接的情况。如果该文件不存在,open系统调用需要返回失败。当一个进程在打开标志中指定O_NOFOLLOW标志位时,open应当打开链接(但不跟踪符号链接)。
如果被链接的文件也是一个符号链接,我们必须递归地跟踪他,直到到达一个非链接文件。如果链接形成了一个循环,我们需要返回一个错误代码。我们也可以提前设定一个阈值(例如10),当链接的深度到达阈值就返回错误代码来近似地处理这个问题。
其他系统调用(例如link和unlink)则不能跟踪符号链接,这些系统调用只能操作符号链接本身。
在这个Lab中,我们不需要处理指向文件夹的符号链接。
系统调用配置
首先有一些关于系统调用的前提配置需要做好,之前Lab Syscall做过好多遍了,就懒得说了…
首先,我们去user/usys.pl中注册新的系统调用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 print "# generated by usys.pl - do not edit\n" ;print "#include \"kernel/syscall.h\"\n" ;sub entry my $name = shift ; print ".global $name\n" ; print "${name} :\n" ; print " li a7, SYS_${name} \n" ; print " ecall\n" ; print " ret\n" ; } entry("fork" ); entry("exit" ); entry("wait" ); entry("pipe" ); entry("read" ); entry("write" ); entry("close" ); entry("kill" ); entry("exec" ); entry("open" ); entry("mknod" ); entry("unlink" ); entry("fstat" ); entry("link" ); entry("mkdir" ); entry("chdir" ); entry("dup" ); entry("getpid" ); entry("sbrk" ); entry("sleep" ); entry("uptime" ); entry("symlink" )
然后在user/user.h 中在系统调用部分进行声明:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 int fork (void ) ;int exit (int ) __attribute__ ((noreturn )) ;int wait (int *) ;int pipe (int *) ;int write (int , const void *, int ) ;int read (int , void *, int ) ;int close (int ) ;int kill (int ) ;int exec (char *, char **) ;int open (const char *, int ) ;int mknod (const char *, short , short ) ;int unlink (const char *) ;int fstat (int fd, struct stat*) ;int link (const char *, const char *) ;int mkdir (const char *) ;int chdir (const char *) ;int dup (int ) ;int getpid (void ) ;char * sbrk (int ) ;int sleep (int ) ;int uptime (void ) ;int symlink (char *, char *) ;
我们还要在kernel/syscall.h中添加新的系统调用编号:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 #define SYS_fork 1 #define SYS_exit 2 #define SYS_wait 3 #define SYS_pipe 4 #define SYS_read 5 #define SYS_kill 6 #define SYS_exec 7 #define SYS_fstat 8 #define SYS_chdir 9 #define SYS_dup 10 #define SYS_getpid 11 #define SYS_sbrk 12 #define SYS_sleep 13 #define SYS_uptime 14 #define SYS_open 15 #define SYS_write 16 #define SYS_mknod 17 #define SYS_unlink 18 #define SYS_link 19 #define SYS_mkdir 20 #define SYS_close 21 #define SYS_symlink 22
并在kernel/syscall.c中的syscalls表中添加新的映射关系,指向需要执行的函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 extern uint64 sys_chdir (void ) ;extern uint64 sys_close (void ) ;extern uint64 sys_dup (void ) ;extern uint64 sys_exec (void ) ;extern uint64 sys_exit (void ) ;extern uint64 sys_fork (void ) ;extern uint64 sys_fstat (void ) ;extern uint64 sys_getpid (void ) ;extern uint64 sys_kill (void ) ;extern uint64 sys_link (void ) ;extern uint64 sys_mkdir (void ) ;extern uint64 sys_mknod (void ) ;extern uint64 sys_open (void ) ;extern uint64 sys_pipe (void ) ;extern uint64 sys_read (void ) ;extern uint64 sys_sbrk (void ) ;extern uint64 sys_sleep (void ) ;extern uint64 sys_unlink (void ) ;extern uint64 sys_wait (void ) ;extern uint64 sys_write (void ) ;extern uint64 sys_uptime (void ) ;extern uint64 sys_symlink (void ) ;static uint64 (*syscalls[]) (void ) = {[SYS_fork] sys_fork, [SYS_exit] sys_exit, [SYS_wait] sys_wait, [SYS_pipe] sys_pipe, [SYS_read] sys_read, [SYS_kill] sys_kill, [SYS_exec] sys_exec, [SYS_fstat] sys_fstat, [SYS_chdir] sys_chdir, [SYS_dup] sys_dup, [SYS_getpid] sys_getpid, [SYS_sbrk] sys_sbrk, [SYS_sleep] sys_sleep, [SYS_uptime] sys_uptime, [SYS_open] sys_open, [SYS_write] sys_write, [SYS_mknod] sys_mknod, [SYS_unlink] sys_unlink, [SYS_link] sys_link, [SYS_mkdir] sys_mkdir, [SYS_close] sys_close, [SYS_symlink] sys_symlink, };
接下来我们就差在kernel/sysfile.c下加入一个名字叫做sys_symlink的实现函数了。
另外记得把symlinktest添加在主目录的Makefile里面:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 UPROGS=\ $U/_cat\ $U/_echo\ $U/_forktest\ $U/_grep\ $U/_init\ $U/_kill\ $U/_ln\ $U/_ls\ $U/_mkdir\ $U/_rm\ $U/_sh\ $U/_stressfs\ $U/_usertests\ $U/_grind\ $U/_wc\ $U/_zombie\ $U/_symlinktest\
sys_symlink系统调用实现如果我们需要实现symlink系统调用,和普通的文件一样,我们都需要创建inode,并将其视作一个特殊的文件,我们将符号链接指向的目标路径信息也可以直接存储在这个inode下的文件数据块中。
首先根据提示,我们要先声明符号链接的新文件类型,向kernel/stat.h中添加一个新的文件类型T_SYMLINK:
1 2 3 4 #define T_DIR 1 #define T_FILE 2 #define T_DEVICE 3 #define T_SYMLINK 4
随后我们在kernel/sysfile.c下创建系统调用核心函数sys_symlink:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 uint64 sys_symlink (void ) { struct inode *ip ; char target[MAXPATH], path[MAXPATH]; int n; if ((n = argstr(0 , target, MAXPATH)) < 0 || argstr(1 , path, MAXPATH) < 0 ) return -1 ; begin_op(); if ((ip = create(path, T_SYMLINK, 0 , 0 )) == 0 ){ end_op(); return -1 ; } if (writei(ip, 0 , (uint64)target, 0 , n) != n) { iunlockput(ip); end_op(); return -1 ; } iunlockput(ip); end_op(); return 0 ; }
在这里我们将指向目标路径信息,写入inode下的第一个数据块。需要注意的是,如果writei写入错误,在返回异常前,要及时释放inode下的锁。
sys_open函数修改首先,我们根据提示在kernel/fcntl.h中补全O_NOFOLLOW的定义,注意不要与其他标志位冲突:
1 2 3 4 5 6 #define O_RDONLY 0x000 #define O_WRONLY 0x001 #define O_RDWR 0x002 #define O_CREATE 0x200 #define O_TRUNC 0x400 #define O_NOFOLLOW 0x004
随后我们尝试修改sys_open的功能实现,根据提示,只有在O_NOFOLLOW设置的情况下,我们才考虑对符号链接进行递归的跟踪,我们在这里设置一个最大递归深度MAX_SYMLINK_DEPTH,当我们的套娃深度超过这个点的时候我们就直接返回失败,否则我们从当前符号链接对应的inode中读出其指向的目标路径,继续套娃:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 #define MAX_SYMLINK_DEPTH 10 uint64 sys_open (void ) { char path[MAXPATH]; int fd, omode; struct file *f ; struct inode *ip ; int n; if ((n = argstr(0 , path, MAXPATH)) < 0 || argint(1 , &omode) < 0 ) return -1 ; begin_op(); if (omode & O_CREATE){ ip = create(path, T_FILE, 0 , 0 ); if (ip == 0 ){ end_op(); return -1 ; } } else { if ((ip = namei(path)) == 0 ){ end_op(); return -1 ; } ilock(ip); if (ip->type == T_DIR && omode != O_RDONLY){ iunlockput(ip); end_op(); return -1 ; } } if (ip->type == T_DEVICE && (ip->major < 0 || ip->major >= NDEV)){ iunlockput(ip); end_op(); return -1 ; } if (ip->type == T_SYMLINK && !(omode & O_NOFOLLOW)){ int depth = 0 ; while (ip->type == T_SYMLINK){ if (++depth == MAX_SYMLINK_DEPTH){ iunlockput(ip); end_op(); return -1 ; } if (readi(ip, 0 , (uint64)path, 0 , MAXPATH) < 0 ){ iunlockput(ip); end_op(); return -1 ; } iunlockput(ip); if ((ip = namei(path)) == 0 ){ end_op(); return -1 ; } ilock(ip); } } if ((f = filealloc()) == 0 || (fd = fdalloc(f)) < 0 ){ if (f) fileclose(f); iunlockput(ip); end_op(); return -1 ; } if (ip->type == T_DEVICE){ f->type = FD_DEVICE; f->major = ip->major; } else { f->type = FD_INODE; f->off = 0 ; } f->ip = ip; f->readable = !(omode & O_WRONLY); f->writable = (omode & O_WRONLY) || (omode & O_RDWR); if ((omode & O_TRUNC) && ip->type == T_FILE){ itrunc(ip); } iunlock(ip); end_op(); return fd; }
注意到的是namei函数不会对ip上锁,我们获得inode之后需要使用ilock来上锁,而create则会上锁。
测试
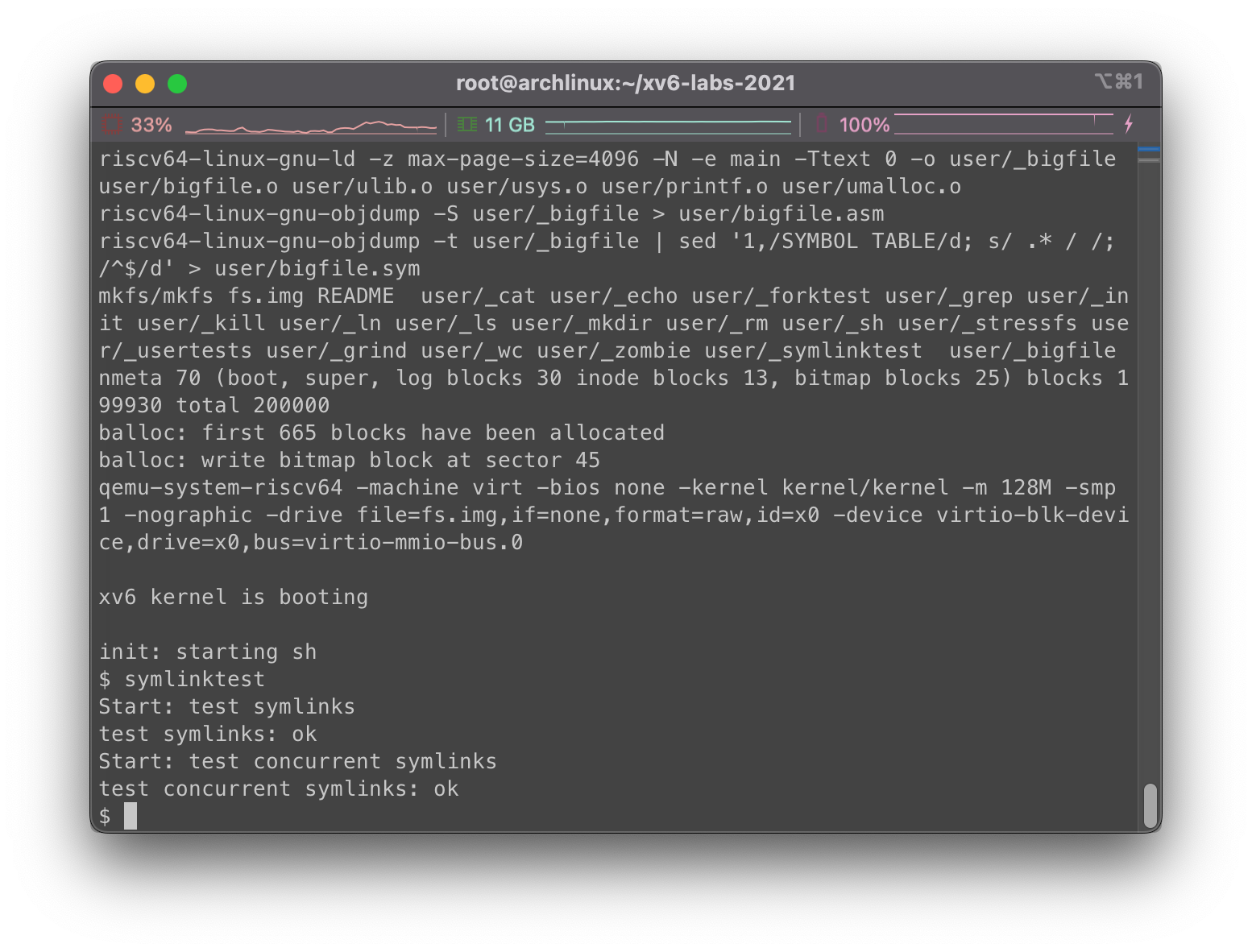
在主目录下运行make clean; make qemu,在xv6下运行symlinktest,我们看到:
看起来没有什么问题。
总结
现在我们对整个Lab进行测试,首先有几点需要注意:
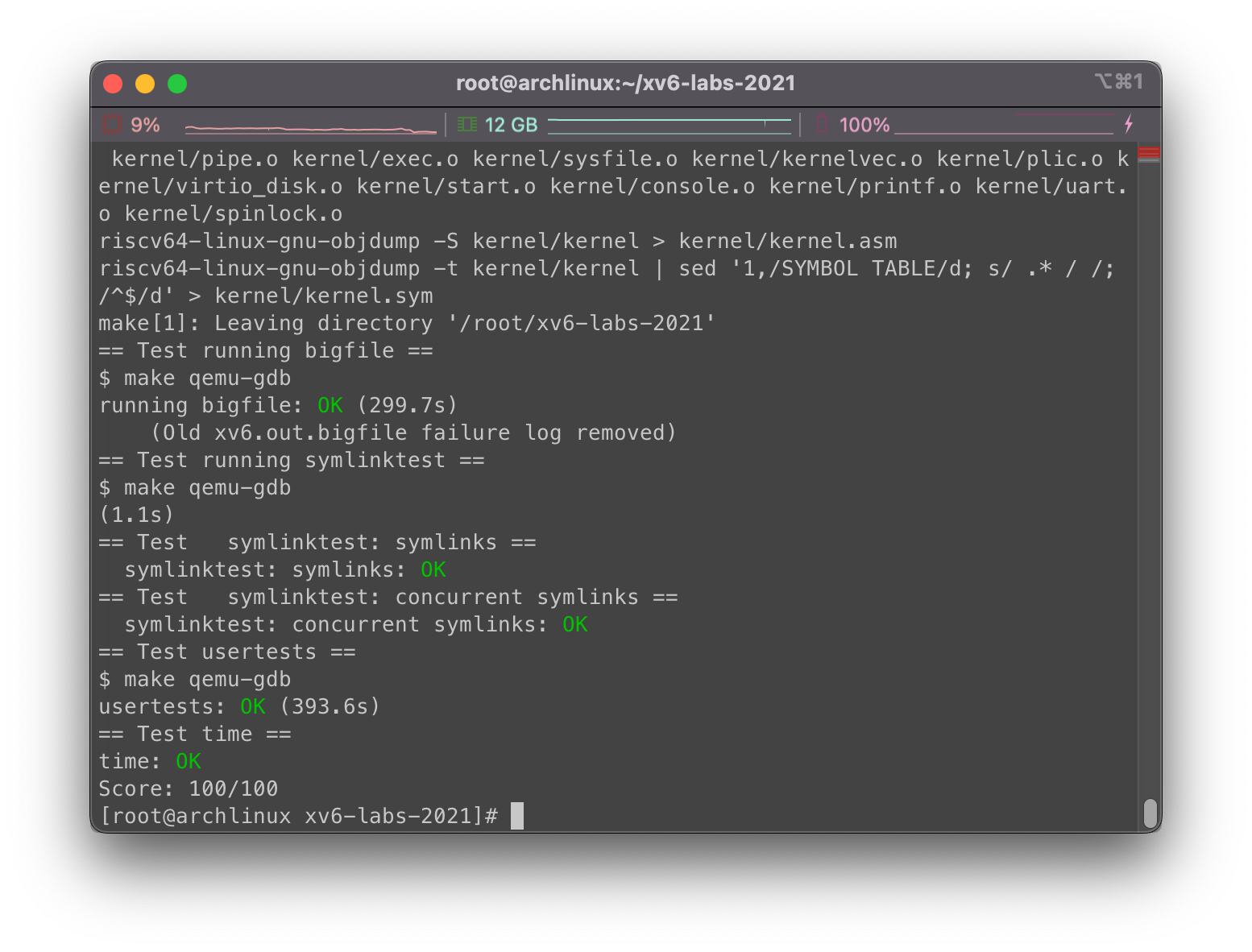
好了,接下来运行make grade,如下是测试结果:
跑的好慢好烫… 我是不是该换电脑了…