MIT 6.824 Lab 1: MapReduce实验
继CMU 15-213和MIT 6.S081之后继续作死开一新坑… 这次是大名鼎鼎的分布式系统,感觉会很难,不过哪次又不是这样呢…
MIT 6.824的最新课程官网在这里:6.824 Home Page: Spring 2022 - MIT PDOS
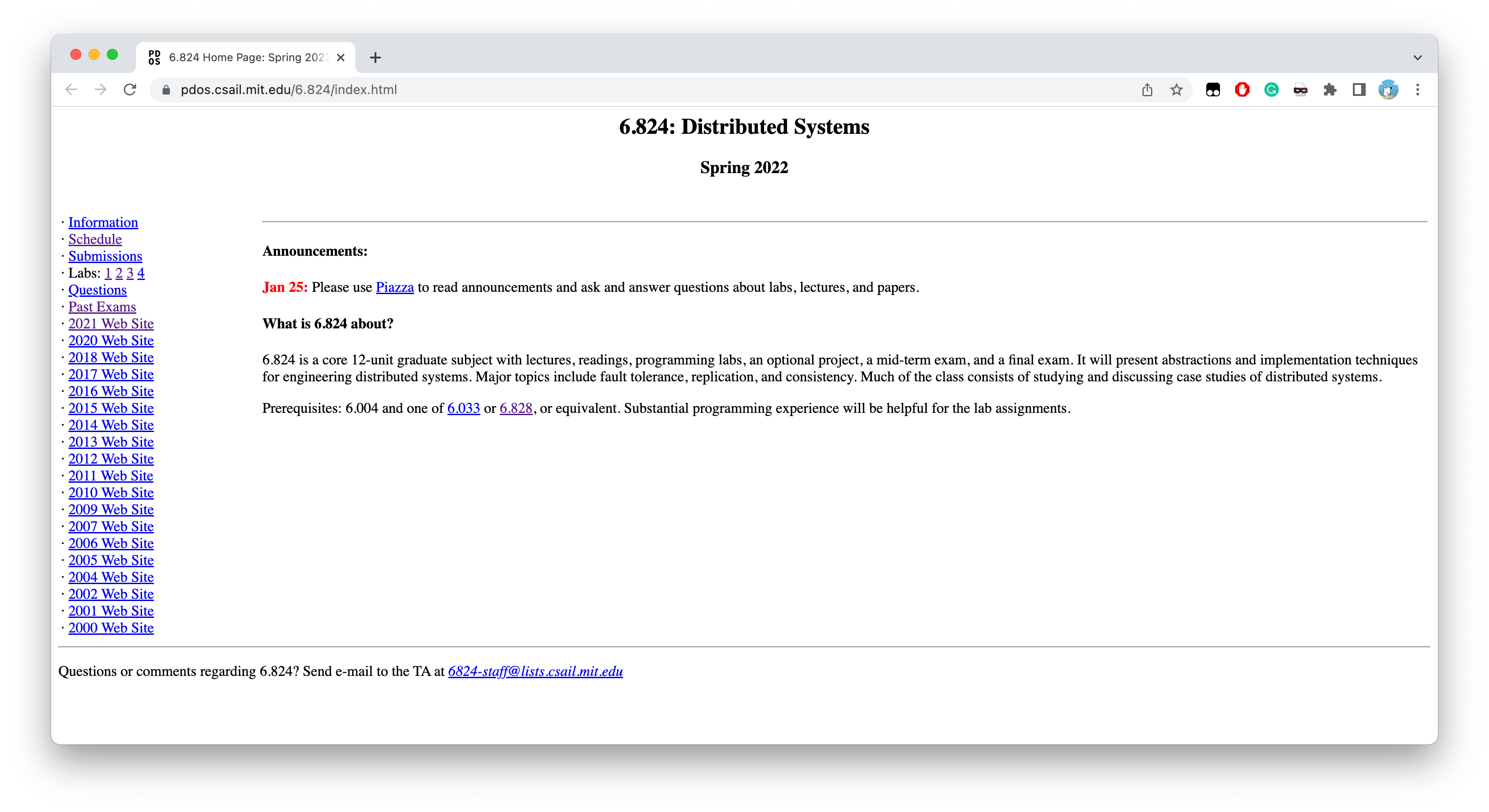
其前继课程是MIT 6.004以及MIT 6.033和MIT 6.828之间二选一…
在课程日程里,我们能够看到相关课程安排,包括每次上课的内容、需要阅读的教材章节、上课的视频、关键笔记以及Lab大作业。
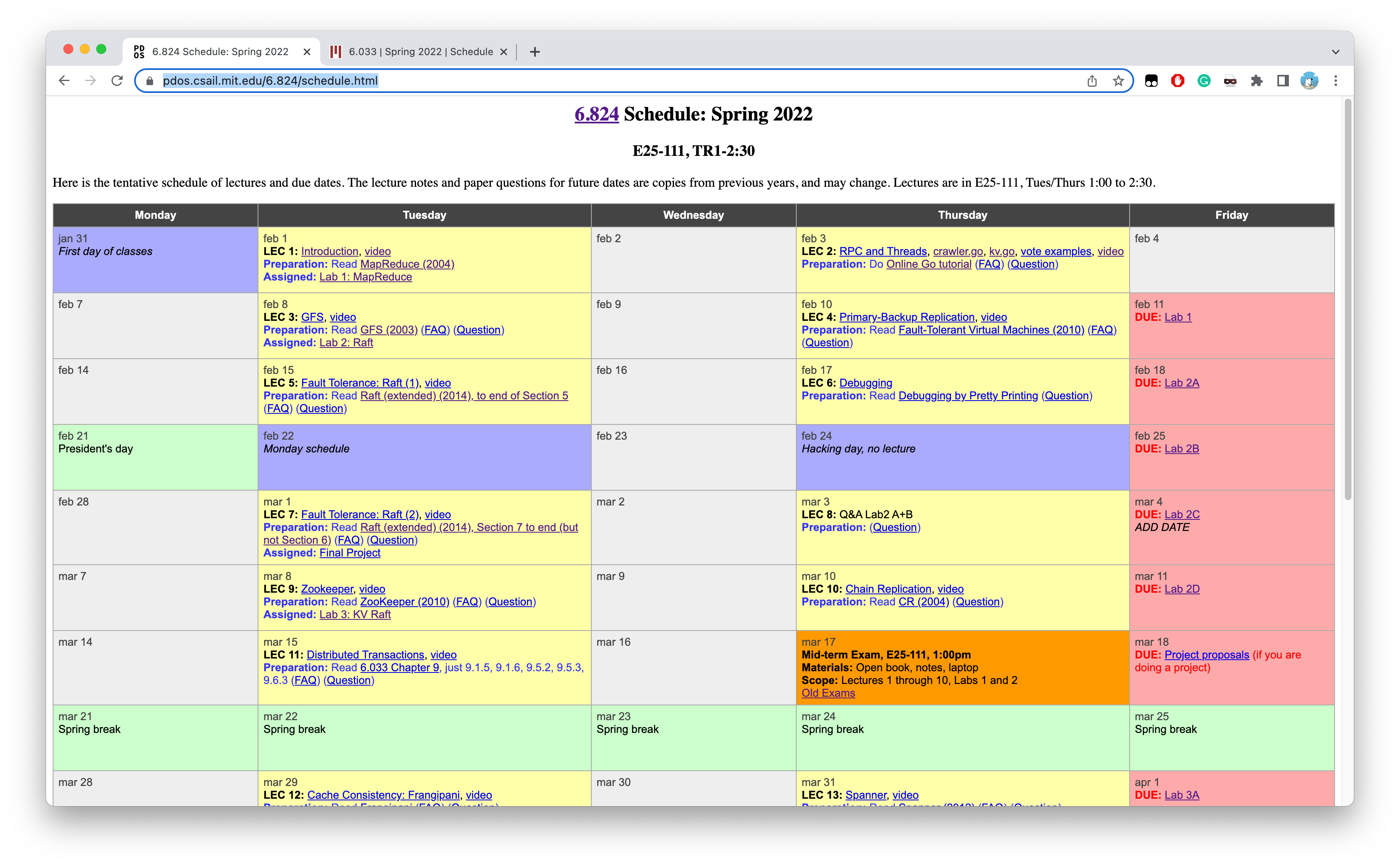
随便点开几个网课视频Video就能发现,转到的YouTube网课视频貌似都是2021年的,已经是疫情时期的了,够新鲜热乎的…
B站上面有面向这次MIT 6.824 2021课程录像的翻译字幕,还是上次整MIT 6.S081课程字幕的佬,salute一波~
视频在MIT 6.824 2021 分布式系统 [中英文字幕],字幕的代码仓库在6.824-2021-video-subtitles。
教材方面,就没见什么教材… 该啃英文论文咯(苦笑
这次课程使用的语言是Golang,我对Golang的掌握程度属于会一点但是不多的感觉🤦♂️。在🦐写了两个月不到,学了个寂寞的Golang…
准备
对应课程
这次的作业是Lab 1: Map Reduce,请阅读MapReduce的相关论文,链接在这里:MapReduce (2004)。
课程相关,建议看掉Lecture 1和Lecture2,也就是B站课程的P1和P2。了解一下MapReduce的基本概念,以及Golang并发编程和RPC的演示。
在Lecture6,也就是B站课程的P6中,有这次Lab的相关Q&A,可以小小的借鉴一下。
系统环境
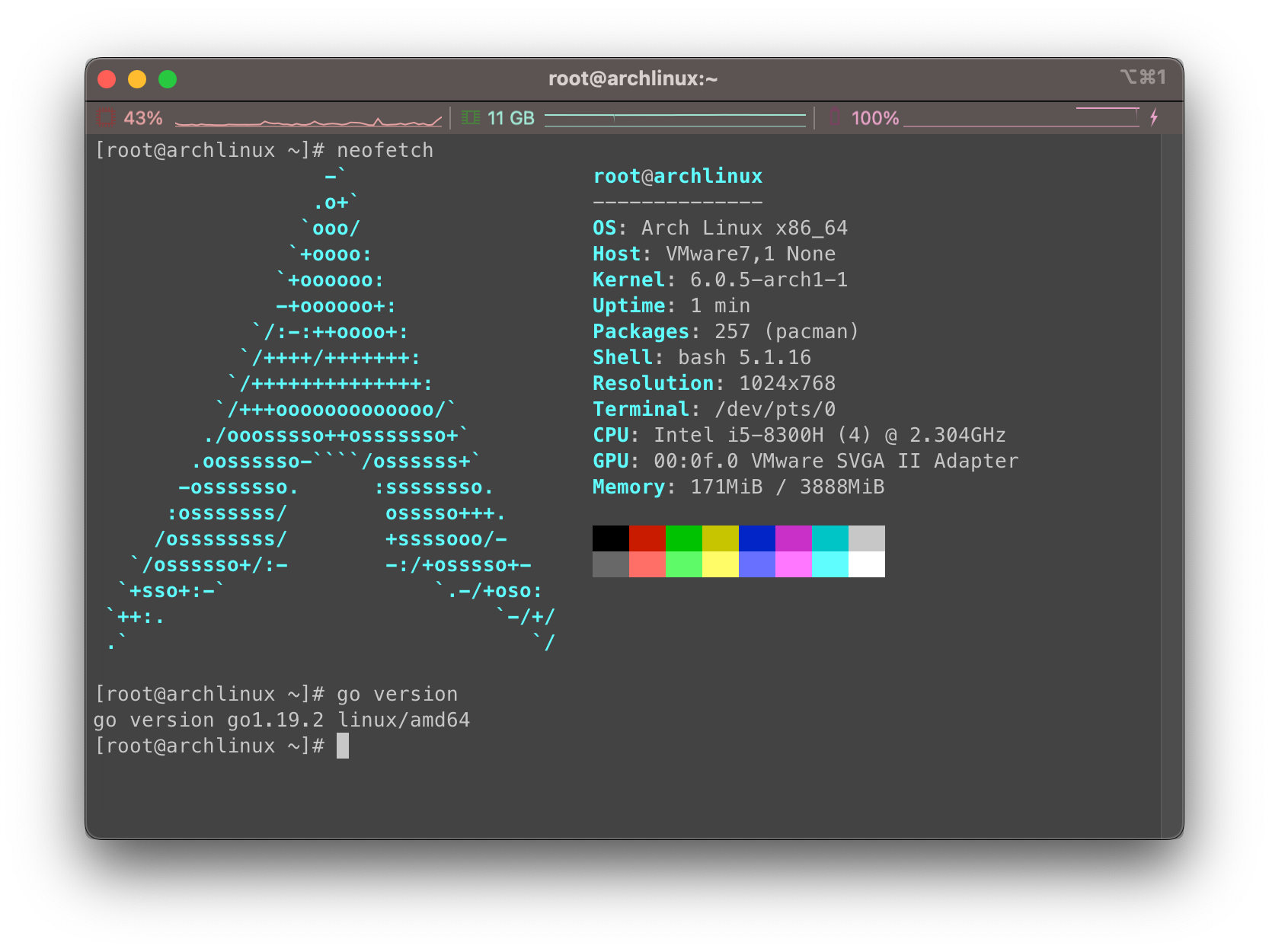
继续使用Arch Linux虚拟机作为我的实验机器,这里已经提前装上了Go:
使用准备
首先我们需要安装Go,这里给出课程Go安装指南:setup Go
Linux发行版用自己的包管理工具即可,macOS请用brew或者Go官网给的dmg安装包,见Download and install。至于Windows,MIT给出的理由是不建议,因为Windows或者WSL环境极其难配置…
以我的Arch Linux为例,只需要:
1 | $ sudo pacman -S go |
接下来我们从仓库中clone下来我们的Lab:
1 | $ git clone git://g.csail.mit.edu/6.824-golabs-2022 6.824 |
本Lab的实验说明书详见:Lab 1: MapReduce
最终我们会使用src/main下的test-mr.sh完成评分工作:
1 | $ cd src/main |
题目
MapReduce简介
概念介绍
MapReduce简单的来说,我们可以看成两个动作,一个是map将任务拆解分配,一个是reduce将结果取出组合。下图源自MapReduce论文:
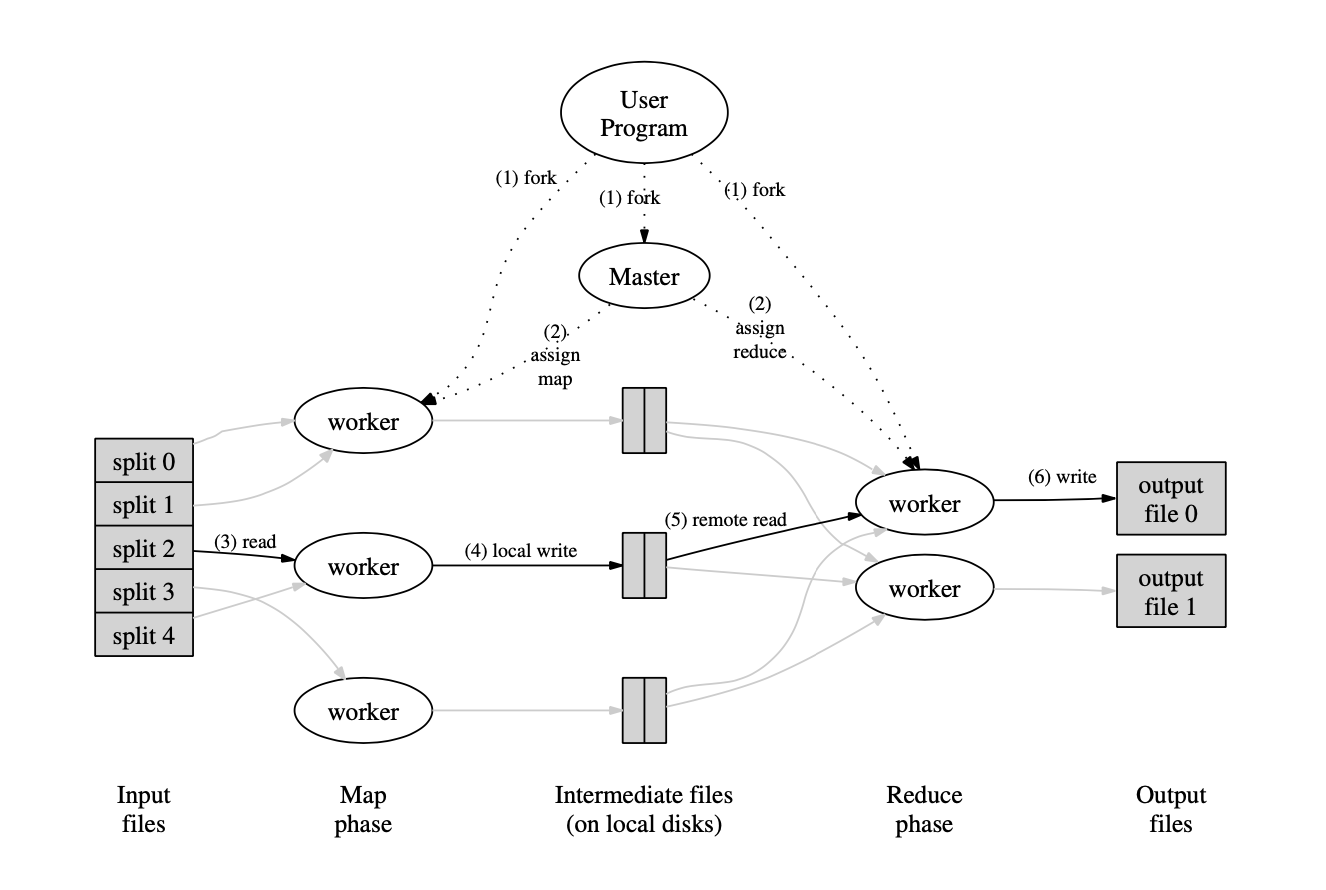
可以看到经历了几个流程:
- 用户程序中的 MapReduce 库首先将输入文件划分为(M)片,每片大小一般在 16MB 到 64MB 之间(由用户通过一个可选的参数指定)。之后,它在集群的很多台机器上都启动了相同的程序拷贝。
- 其中有一个拷贝程序是特别的master。剩下的都是 worker,它们接收 master 分配的任务。其中有 M 个 Map 任务和 R 个 Reduce 任务要分配。master 挑选一个空闲的 worker 并且给它分配一个 map 任务或者 reduce 任务。
- 被分配到 Map 任务的 worker 会去读取相应的输入块的内容。它从输入文件中解析出键值对并且将每个键值对传送给用户定义的 Map 函数。而由 Map 函数产生的中间键值对缓存在内存中。
- 被缓存的键值对会阶段性地写回本地磁盘,并且被划分函数分割成 R 份。这些缓存对在磁盘上的位置会被回传给 master,master 再负责将这些位置转发给 Reduce worker。
- 当 Reduce worker 从 master 那里接收到这些位置信息时,它会使用远程过程调用从 Map worker 的本地磁盘中获取缓存的数据。当 Reduce worker 读入全部的中间数据之后,它会根据中间键对它们进行排序,这样所有具有相同键的键值对就都聚集在一起了。排序是必须的,因为会有许多不同的键被映射到同一个 reduce task 中。如果中间数据的数量太大,以至于不能够装入内存的话,还需要另外的排序。
- Reduce worker 遍历已经排完序的中间数据。每当遇到一个新的中间键,它会将 key 和相应的中间值传递给用户定义的 Reduce 函数。Reduce 函数的输出会被添加到这个 Reduce 部分的输出文件中。
- 当所有的 Map tasks 和 Reduce tasks 都已经完成的时候,master 将唤醒用户程序。到此为止,用户代码中的 MapReduce 调用返回。
文件结构
如果你使用VS Code或者GoLand打开了Lab,看到了很多DuplicateDecl重复声明错误,远远望过去一片红,请不要慌张… 这次的Lab不是这么用的
首先根据论文的意思,很多任务只要能通过类似“分治” 的策略完成,那么我们就能将其转化为MapReduce模型,我们只需要抽象的完成顶层的master节点(也称coordinator节点)以及各个worker节点的实现即可。至于不同的分治任务,我们只需要实现不同的map和reduce函数即可。
根据这种理论,我们看到在目录src/mrapps下存放了多种map和reduce的组合,表示了不同场景的解决方案。例如wc.go就表示了word count字数统计功能,indexer.go表示了文字索引功能。
以wc.go为例,我们使用go plugin将其编译为共享库(.so)的形式:
1 | $ cd src/main |
然后我们运行相关程序的时候只需要将编译好的共享库文件以参数的方式传入即可。在Lab提示中给出了一份使用简单的顺序操作的MapReduce实现,命令如下:
1 | $ go run -race mrsequential.go wc.so pg*.txt |
简单的看一下这个src/main下的mrsequential.go,可以看到有这么一个叫做loadPlugin的方法,可以将wc.so读入并解析出map和reduce的两个函数,实现模块化编程:
1 | // |
这个函数在src/main下的mrworker.go中也有,我们到时候实现使用它来运行分布式MapReduce的worker节点。而src/main下的mrcoordinator.go就没有传入动态库的必要了,我们到时候使用它来运行分布式MapReduce的coordinator节点。
在最终测试的test-mr.sh中我们时常会看到这样的命令,说明这些节点是独立运行的,互相之间通过RPC等方式通信:
1 | echo '***' Starting wc test. |
顺着mrworker.go和mrcoordinator.go两个文件下的方法,我们就摸到了我们这次作业的核心位置,也就是我们需要完成的部分。在src/mr文件夹下,存在着三个文件,其中worker.go实现了worker节点的具体行为,coordinator.go实现了coordinator节点的具体行为,rpc.go则规定了RPC通信中需要传递的变量等信息,这三个文件全部需要我们实现。
要求和提示
在这个Lab中,我们需要构建MapReduce系统,我们将实现一个worker进程,使得其能够调用map和reduce函数,处理文件的读写;同时我们需要实现一个coordinator进程,使得其可以给各个worker分配任务,并且处理出错了的worker进程。
其中Lab提供了MapReduce的顺序实现,见src/main/mrsequential.go。该程序在单一进程中运行了map和reduce操作。另外还提供了MapReduce的相关应用,例如文件mrapps/wc.go实现了单词计数word count,文件mrapps/indexer.go实现了文本索引。我们可以使用如下命令运行顺序版本的单词计数:
1 | $ cd ~/6.824 |
注意,使用-race可以启用Go的竞争检测,且强烈建议在编写和测试Lab代码时开启竞争检测。
对于mrsequential.go,其输出文件是mr-out-0,其输入文件是pg-xxx.txt。
我们可以放心地从文件mrsequential.go中借鉴代码。此外,请阅读mrapps/wc.go文件,来查看MapReduce应用的具体实现。
在我们要实现的分布式MapReduce中,包含两个程序,分别是coordinator和worker。在同一时间,会有一个coordinator和一个或多个worker进程在运行。在真正的系统中,worker进程会在不同的机器上运行,但是在这个Lab中我们暂时让他们在单机上运行。worker进程通过RPC和coordinator进行通信,每个worker进程都会向coordinator请求分配任务,然后从一个或多个文件中读取任务指定的数据,再执行当前任务,最终将任务的输出写入一个或多个文件中。coordinator应该关注这个worker是否在规定的合理时间内完成了这个任务(这个实验中规定的合理时间是10秒),如果发生超时,就应该将相同任务交给另一个worker节点。
在当前框架下已经存在少量代码帮助我们开始,例如coordinator和worker节点的main routine就位于main/mrcoordinator.go 和 main/mrworker.go中,不要修改这两个文件。本次作业应当实现文件mr/coordinator.go, mr/worker.go和mr/rpc.go中的相应功能。
关于如何运行MapReduce的单词计数程序,示例如下,首先我们需要确保相关的plugin插件是最新编译的:
1 | $ go build -race -buildmode=plugin ../mrapps/wc.go |
在main目录下,我们启动coordinator进程:
1 | $ rm mr-out* |
其中参数pg-*.txt是mrcoordinator.go的输入文件,每个文件被分成“一段”,作为一个map任务的输入。使用-race将启用竞争检查。
在其他终端会话中,我们运行worker进程:
1 | $ go run -race mrworker.go wc.so |
当worker和coordinator进程都结束后,查看一下输出文件mr-out-*。如果我们已经完成了当前Lab,那么输出文件结合后排序结果应当与之前运行的简单顺序版本相吻合。例如如下效果:
1 | $ cat mr-out-* | sort | more |
在main/test-mr.sh中Lab提供了一个测试脚本,这个测试将检测MapReduce应用wc和indexer,查看当给定pg-xxx.txt文件作为输入后,程序是否能产生正确的输出。检测脚本还会检查我们的map和reduce任务是否是并行运行的,并还会测试是否考虑到了worker进程在运行任务时崩溃的意外状况。
如果我们现在还没有对Lab做出修改操作,我们直接运行测试脚本,脚本会阻塞,因为coordinator进程不会结束:
1 | $ cd ~/6.824/src/main |
我们在mr/coordinator.go下的Done函数中将ret := false改为true,就可以让coordinator进程立即退出。这样我们就会得到如下输出:
1 | $ bash test-mr.sh |
测试脚本会查看每一个reduce任务输出的名为mr-out-X的文件。由于在mr/coordinator.go和mr/worker.go中的行为还未实现,因此不会产生这些文件,因此测试会失败。
当Lab中的代码实现正确完成后,如下是测试脚本的成功输出示例:
1 | $ bash test-mr.sh |
我们有可能还会看到一些来自Go下的RPC包的错误输出例如:
1 | 2019/12/16 13:27:09 rpc.Register: method "Done" has 1 input parameters; needs exactly three |
我们可以直接忽略掉这些信息,因为当我们注册coordinator节点作为RPC服务器时会检查其所有方法是否与RPC固定格式匹配(即3个输入参数),显然的Done方法并不会被RPC调用。
另外这里还有一些要求需要注意:
- 在
map阶段,我们需要将函数处理的中间结果,根据他们的key我们分到不同的bucket桶中,方便后续nReduce个reduce任务读出。其中nReduce表示的是reduce任务的数量,是由main/mrcoordinator.go传递给MakeCoordinator()的参数。因此,每个map任务都需要产生nReduce个中间文件,供reduce任务使用。 - worker节点实现中需要将第X个
reduce任务的输出放在文件mr-out-X中。 - 在
mr-out-X文件中每行需要包含一个Reduce函数产生的结果,且每行的格式应当使用Go中的"%v %v"格式,我们填入对应的键值对。关于格式问题,可以参考main/mrsequential.go文件中,注释带有"this is the correct format"的代码。如果格式相差太多,会导致测试脚本的失败。 - 改动的代码位置只有
mr/coordinator.go,mr/worker.go和mr/rpc.go,其他文件可以暂作修改方便调试,但是请在最后改回来。 - worker进程需要在当前文件夹下存放
map任务产生的中间文件,随后worker节点将读取这些文件并作为输入传给reduce任务。 main/mrcordinator.go要求实现mr/coordinator.go中的Done()方法,当Done()返回true时,代表整个MapReduce工作的结束,此时mrcoordinator.go也会退出。- 当所有工作全部结束时,工作进程也应当退出。一种简单的实现方法就是,使用
call()函数返回值:如果worker节点显示无法和coordinator进行通信,那么他就可以假设coordinator节点因为全部工作已经结束而退出了,因此自己也可以退出了。这个取决于我们的设计,我们也可以设置一个“请退出”的伪任务,让coordinator节点分发给各个worker节点。
相关提示:
-
关于开发调试等相关提示可以查看网页:Guidance page
-
我们可以从
mr/worker.go的Worker()开始,这个函数将负责向coordinator节点发送RPC请求任务。然后我们尝试修改coordinator节点行为,让其给worker分发还未开始进行的map任务的相关文件。然后我们修改worker节点行为,读取文件输入并调用对应的map函数,正如mrsequential.go中做的那样。 -
相关的应用程序中的
map和reduce函数在运行时通过Go plugin加载进来,使用.so共享库文件。 -
如果我们修改了
mr/目录下的任何代码,我们可能需要重新编译.so文件。 -
这个实验需要不同的workers节点共享同一个文件系统,如果所有的worker进程都运行在单机上面那自然不是问题。实际上,如果worker节点运行在不同机器上,我们会需要一个像GFS一样的全局文件系统。
-
产生的中间文件的命名可以设置为
mr-X-Y,其中X是map任务的编号,Y是reduce任务的编号。 -
worker节点的
map任务需要将中间产生的键值对存储在文件中,以方便被reduce任务正确的读取。为了规范写入格式,我们可以使用Go下的encoding/json包,将键值对以JSON的格式写入打开的文件中:1
2
3enc := json.NewEncoder(file)
for _, kv := ... {
err := enc.Encode(&kv)然后我们可以使用如下代码读取文件:
1
2
3
4
5
6
7
8dec := json.NewDecoder(file)
for {
var kv KeyValue
if err := dec.Decode(&kv); err != nil {
break
}
kva = append(kva, kv)
} -
在
map部分中,worker需要使用worker.go中的函数ihash(key),来选择当前key对应的reduce任务。 -
大胆的借鉴顺序版本中
mrsequential.go给出的文件读写和排序中间结果键值对的相关代码。 -
coordinator节点作为RPC服务端,应当是并发运行地接受请求的,所以不要忘记对共享数据上锁。
-
使用Go的竞争检测,运行
go build -race和go run -race命令。test-mr.sh脚本运行时已经加入了-race参数。 -
worker节点有时候需要进行等待,例如直到最后一个
map任务完成,reduce任务才可以开始。一种可能的解决方案是。一种可能的解决方案是worker节点周期性的向coordinator节点请求任务,并在期间使用time.Sleep()。另一种解决方案是,在coordinator节点中相关的RPC处理函数使用time.Sleep()或者sync.Cond等方式循环等待。由于Go对每一个RPC都使用了单独的线程,所以这样的忙等待不会阻碍coordinator节点处理其他RPC请求。 -
coordinator节点不能很好的区分出,worker节点发生了崩溃,还是由于某种原因长时间的停滞卡住,还是单纯的执行太慢。对worker节点长时间无反应的最好处理方法是,一旦等待一段时间后,该worker依然未响应,我们可以放弃它,并把该worker正处理的任务交给其他worker。在这个Lab中,coordinator节点会等待10s,之后coordinator节点会认为这个worker节点已经离线(当然也有可能worker节点还是在正常工作的)
-
如果我们选择实现任务副本(见论文章节3.6),注意到测试代码会测试一种情形,当worker节点执行任务且没有崩溃,那么代码不应当安排不相干的任务。任务副本对应的时间间隔应该安排得更久(例如10s以上),以免对我们的测试脚本的测试产生影响。(注:备份任务不会被测试)
-
如果想手动的worker节点崩溃恢复,我们可以使用
mrapps/crash.go这个应用plugin。在这个MapReduce的模块中,实现了map和reduce函数中的随机退出。 -
为了确保不会有节点发现由于崩溃产生的写了一半的文件,在MapReduce论文中提及了一种巧妙的方式,我们可以使用临时文件,一旦完成写入我们再将其原子性的重命名为对应名字。我们可以使用
ioutil.TempFile来创建临时文件,并使用os.Rename来对其进行重命名。 -
test-mr.sh在mt-tmp子目录下运行各进程,如果测试脚本提示错误,而你想查看中间文件和最终结果文件来了解发生了什么,你可以查看那个子目录。你可以调整test-mr.sh,使其在提示失败时退出(否则脚本可能会继续测试,并且覆盖输出的文件)。 -
test-mr-many.sh提供了一个带有超时的test-mr.sh的基本脚本,并将测试次数作为参数。你不能同时运行多个test-mr.sh,因为coordinator将会占用同一个socket,这会造成冲突。 -
Go RPC只发送名称以大写字母开头的结构字段。子结构也需要使用大写的字段名称。
-
当我们向RPC传递一个回复内容数据结构的指针时,
*reply所指向的对象应该是零分配的。RPC调用代码总是像下面一样:1
2reply := SomeType{}
call(..., &reply)我们并不需要在调用RPC之前设置任何字段的值。如果不遵守这样的要求,直接将回复内容的数据结构初始化为该数据类型的非默认值,而RPC服务端将回复内容设置为默认值时,就会出现问题,你会发现写入似乎没有生效,而在调用者一方看,非默认值仍然会存在。
思路整理
信息量很大… 抛开一些实现的细节我们先看一点基本的问题,我们以单词统计功能word count为例,观察一下顺序版本的MapReduce是怎么实现的。
我们查看src/main文件夹下的mrsequential.go文件,在导入map和reduce函数之后,我们执行map相关任务,生成中间结果:
1 | // |
可以看出来,我们以单个文件为单位,将不同的文本文件分配给map函数,map函数实现的逻辑不难理解,位于mrapps/wc.go中:
1 | // |
简单来说,就是每出现一个单词W,就向kva数组中加入一个键值对{W, 1}。
接下来,我们在mrsequential.go中执行reduce相关操作,读取中间结果:
1 | // |
可以看出,上述操作首先排序key,然后将其归类,并通过如下的reduce方法,汇总出了key单词对应的数量,最终写入文件,顺序的完成了整个操作。
1 | // |
简单的来看,顺序的单词计数整个操作流程可以视作如下几步,我们这里以A, B, C表示三种不同的单词为例:
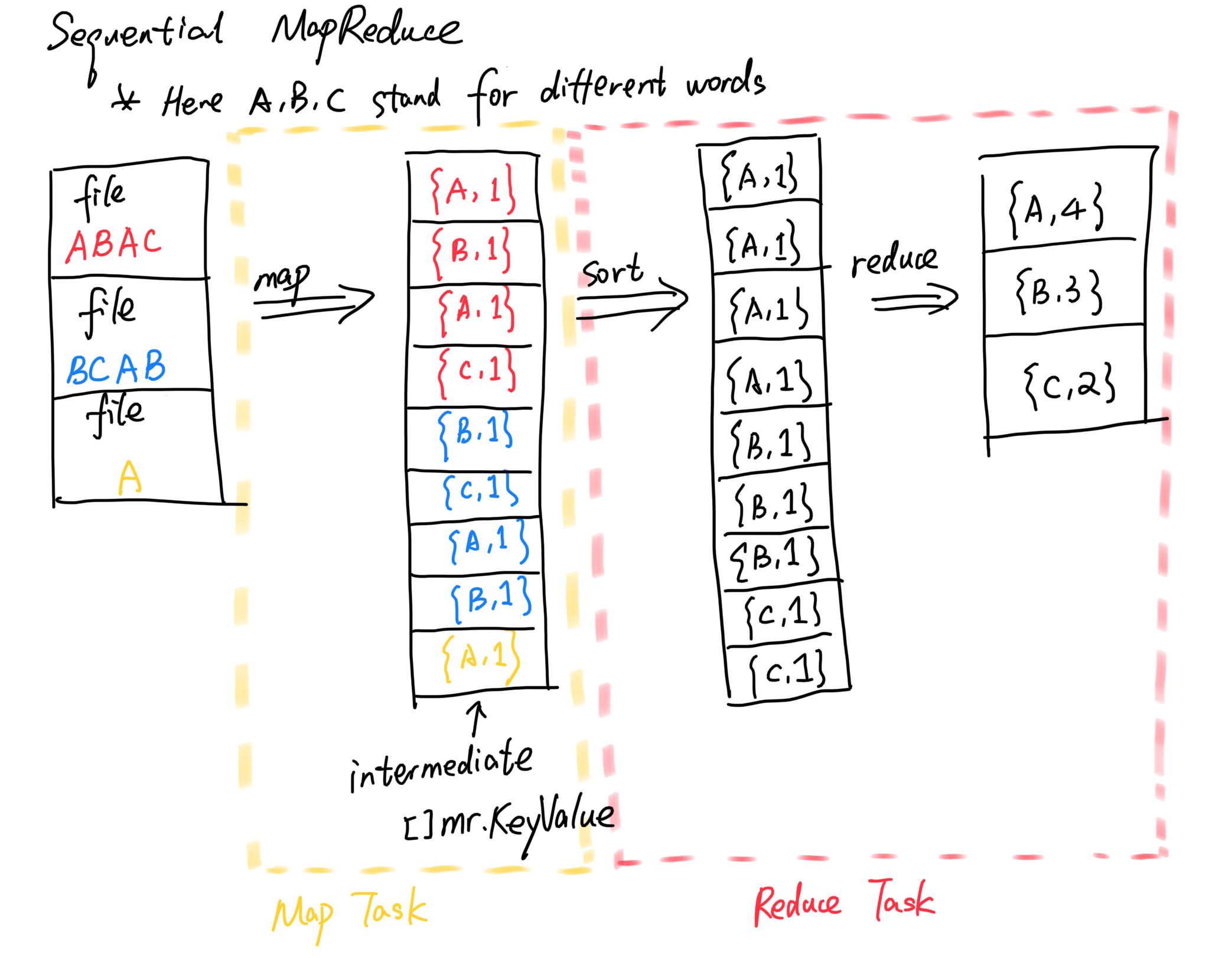
整个流程简单来看分为了读取输入执行map,重排序,reduce整合统计三步,这里我们的中间文件仅仅保存在了内存中,也并没有写入磁盘中。
在我们新实现的分布式MapReduce中,由于是多个节点协同工作,我们需要确保映射的正确性,我们不能让一个单词在多个reduce任务中被统计,否则结果里面我们就会看到这个单词的计数多次出现却没有最终累加在一起。根据提示,题目给出的建议是每个map任务都根据ihash哈希函数,将对应的单词key放入不同的桶中,供后来的reduce节点拉取。这里我们假设只存在两个reduce任务,且A, B单词映射到0号任务,C单词映射到1号任务:
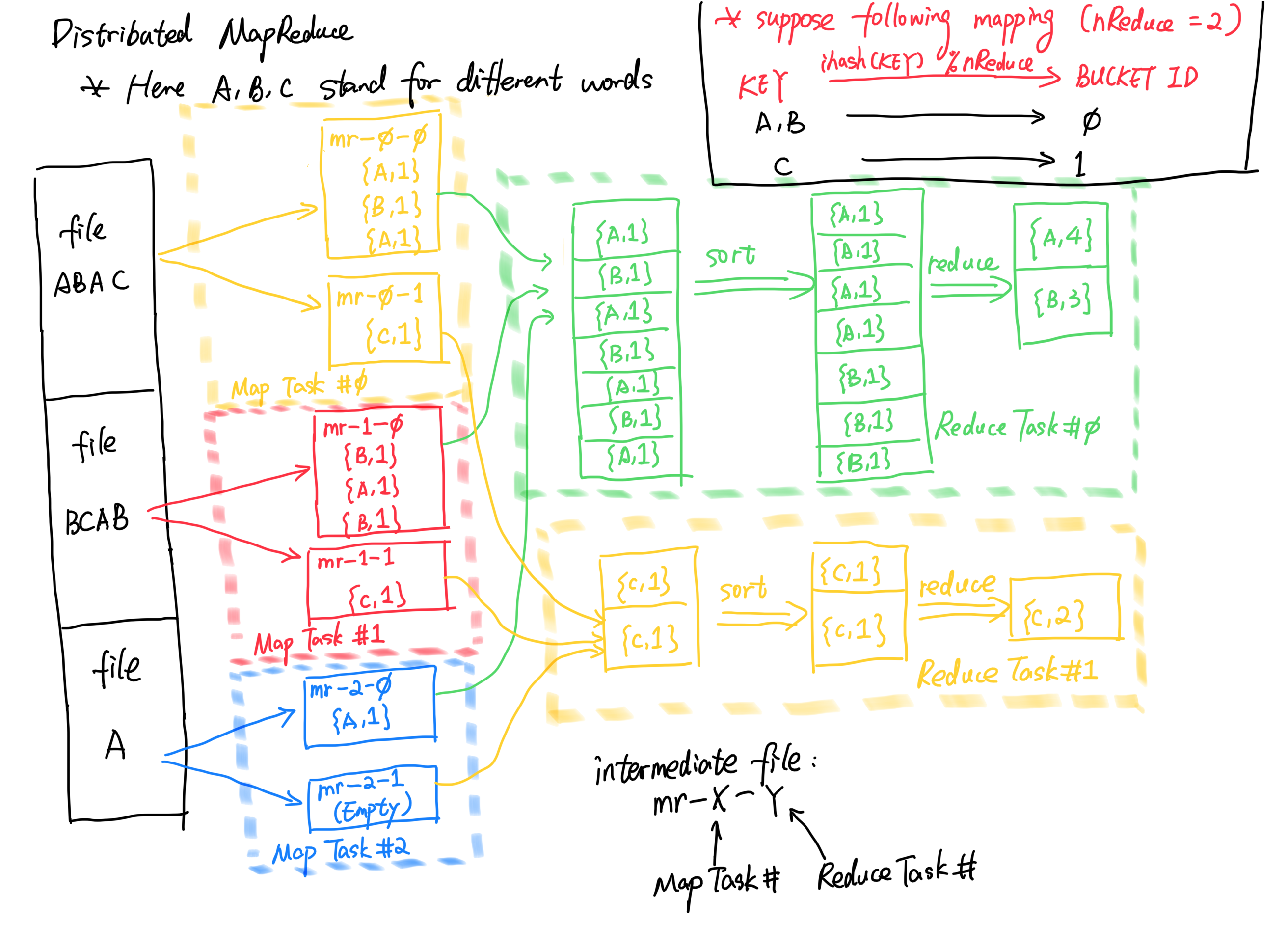
可以看到,0号reduce任务最终只归纳到了A和B单词的出现频次,而1号reduce任务收集到了C单词的频次,我们最终只需要将输出结果收集合并即可。
值得提到的是,在这样的情形下,所有reduce任务的开始仍然需要等待所有map任务的结束。其中map任务和reduce任务都是幂等性的,即不管执行多少次预期结果产生的文件内容都不会发生变化,因此也很好的适应了worker节点发生崩溃的情况。另外由于文件系统的特性,当我们使用os.Rename覆盖一个文件时,如果被覆盖的文件被打开正在读写,那读写操作不会受影响,只有inode和文件名之间发生了unlink,inode在文件关闭后才会回收,因此不用担心某个map任务运行由于过于缓慢被认定失败但是在reduce运行到某个阶段再次覆盖了中间文件。
任务数据结构设置
Task基本任务结构
由于worker和coordinator之间穿插了大量的RPC任务调度,很自然的我们需要对任务相关的数据创建一个统一的数据结构管理,在这里我新建了taskset.go文件并设置了如下的Task数据结构:
1 | type TaskType int |
这个数据结构将直接用于coordinator节点和worker节点直接的RPC通信。其中Type表示了当前的任务类型,例如map还是reduce任务等;TaskId表示了当前任务的ID序号;ReducerTasksNum表示了在本次处理中参与了多少个reduce任务,我们的map任务需要这个数量来创建对应的中间文件;Files表示了当前任务要处理的文件,不难想到map任务只有一个文件需要处理,而reduce任务有“map任务数量”的文件要处理。
另外在任务方面,我不是很希望worker节点向coordinator节点RPC请求任务的时候会在服务端由于队列空了拉不出来任务而卡住,希望一次RPC请求就是简单直接的,因此我在这里引入了两个“伪任务”。其中WaitTask用于告诉worker节点当前任务队列为空无法分配到新任务,但是后续还有任务没刷出来,可以等等再请求;ExitTask用于告诉worker节点目前所有map和reduce任务都已经完结,可以直接退出了。
我们顺带实现了Task的初始化函数:
1 | func NewTask(taskType TaskType, taskId int, nReduce int, files []string) *Task { |
TaskMetaData元数据结构
同时我们注意到每个任务自身也是存在状态的,例如尚未开始、已经交由worker节点处理、已经处理完成这几种状态,worker节点只需要工作并不需要了解这些状态,我们将这些状态交由coordinator节点管理,此外coordinator节点中还维护了一个工作队列chan *Task用于拉取任务。
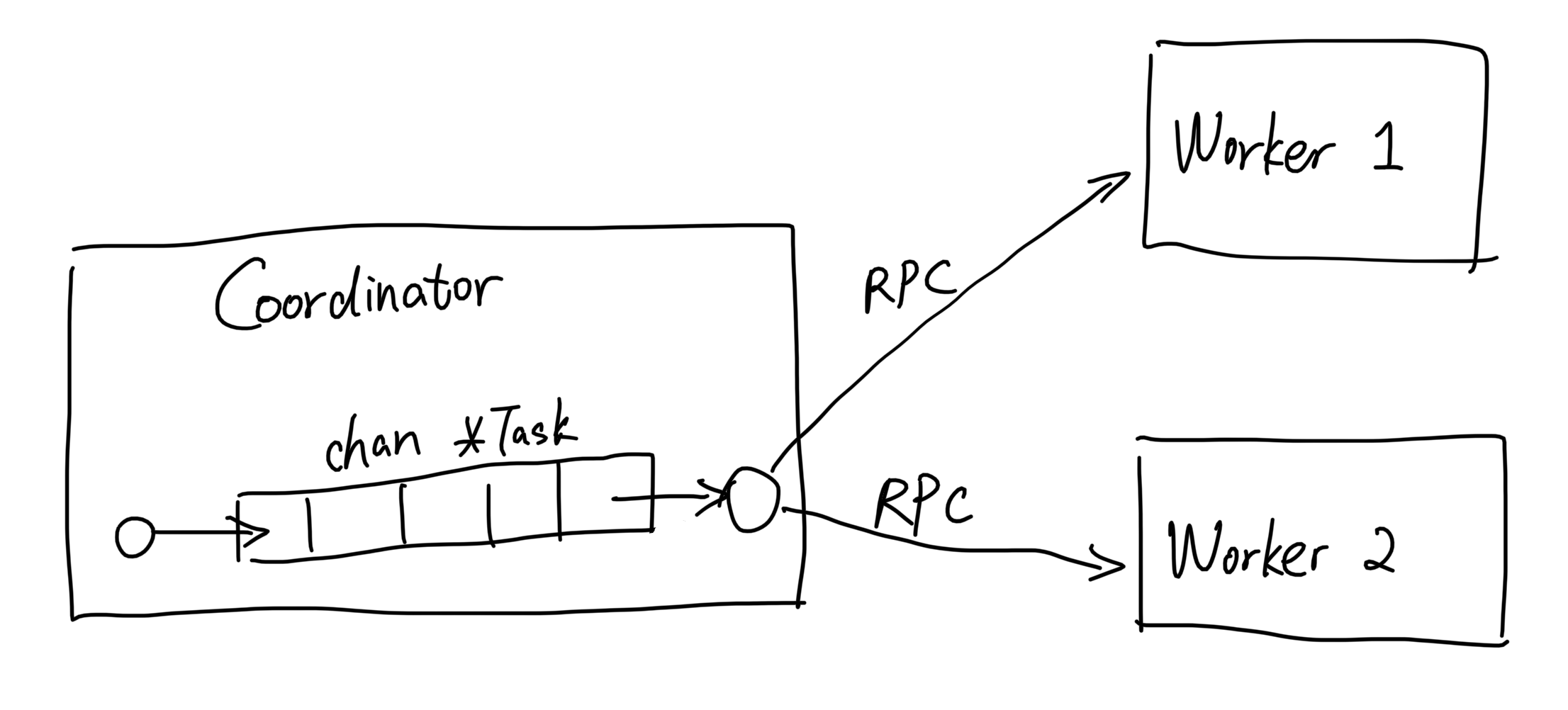
为此我们创建一个类TaskMetaData:
1 | type TaskStatus int |
这里只是简单的包装了一下,其中Status表示了当前的任务状态,例如还在队列中等待中、从队列取出交由worker处理中、已完成这三种状态;StartTime表示了任务从队列取出交给worker时刻的时间戳,表示任务的开始时间,我们使用这个时间戳来检查是否发生了崩溃超时需要重新分配任务;Task就是任务对象的本体。
我们顺带实现了TaskMetaData的初始化函数:
1 | func NewTaskMetaData(task *Task) *TaskMetaData { |
可以看出当刚被创建出来的时候,这个任务是处于在等待状态的,由于还没有开始运行,因此时间戳也暂时无需设置,直到这个任务从队列中被取出我们才需要进行设置。
TaskSet数据集结构
但是最重要的是我们需要使用具体的Task反查到这些元数据,因为worker节点只会请求Task类型的任务,并提交Task类型任务的完成信息,例如当worker提交某个任务完成的时候,coordinator节点需要根据回传的Task定位到对应的TaskMetaData,然后将里面的Status修改为Done。因此我们需要一个集合来统一管理,这里我设置了一个TaskSet:
1 | type TaskSet struct { |
里面存在两个map,分别管理map任务和reduce任务,key就是任务的ID序号。我们后续会使用这个数据集完成检查任务超时,标记任务完成等操作,所有任务状态相关的操作都需要经过数据集。
初始化函数如下:
1 | func NewTaskSet() *TaskSet { |
由于核心的操作都需要经过这个状态数据集,我们在这里安排了多个方法,这里逐一介绍下功能和使用场景。
首先看到的是RegisterTask()函数,我们使用这个函数在数据集中创建其对应位置,简称“注册”操作。在这个操作后我们一般直接就会紧跟着将任务插入队列中:
1 | func (ts *TaskSet) RegisterTask(task *Task) { |
这里还实现了StartTask()函数,当任务从队列中被取出即将RPC回复给节点开始工作时,我们需要根据Task反查到对应的元数据,做一些小小的修改,例如时间戳到更新和修改状态:
1 | func (ts *TaskSet) StartTask(task *Task) { |
同理我们还有CompleteTask()函数,当worker节点回传某任务已经完成后,我们需要根据RPC请求中携带的Task反查元数据,然后做修改。需要注意的是,可能worker节点执行缓慢,等到他返回的时候任务由于超时已经重分配被其他worker节点处理掉了,可以加一个处理的小细节:
1 | func (ts *TaskSet) CompleteTask(task *Task) bool { |
CheckComplete()函数用于检查某类任务是否全部完成了,这个函数一般会在任务队列为空的时候触发,因为我们并不确定此时任务是否全部完成,只能确定任务全部被worker节点取出了。如果检查出map或者reduce任务都完成,我们可以实现coordinator节点状态的切换,这个后续再提。
1 | func (ts *TaskSet) CheckComplete(taskType TaskType) bool { |
CheckTimeout()函数用于检查任务数据集中是否有任务在worker下的运行时间超出了设定的阈值,并将这些任务列在一个列表中。通过这个方法,我们可以额外开辟一个一个线程,通过定期检查的方式来重启超时任务:
1 | const TaskTimeout time.Duration = 10 |
RPC参数设置
接下来,我们来讨论一下RPC通信中的参数设置。在这里我假定coordinator节点作为RPC的服务端,worker节点作为RPC的客户端,客户端只会向服务端发起两类RPC请求:
- 请求新任务,worker节点向coordinator节点请求,coordinator节点从队列中拉取
Task。如果拉不到,还能返回ExitTask或者WaitTask。 - 提交任务,worker节点完成了指定的任务,并将处理好的
Task原封不动的放在请求里发给coordinator节点。coordinator收到请求后会尝试修改任务数据集,将对应任务元数据状态修改为Done。
关于RPC相关参数配置,我们都在rpc.go下实现。
请求任务
在这里我直接将RPC请求和响应包装成如下格式:
1 | import "github.com/google/uuid" |
Msg主要用来传递worker和coordinator的一些状态消息,NodeId是发送请求/响应的节点对应的UUID,以方便区分(在开始运行时会随机生成)。响应内容主体就是返回的Task,表示给worker节点分配的新任务。
提交任务
提交任务的时候则相反,在worker发送的请求中携带了Task,表示刚刚完成的任务。其他内容基本一致:
1 | type SubmitTaskArgs struct { |
Coordinator节点实现
总体框架
关于coordinator节点的相关代码,都在coordinator.go下实现。
一个coordinator节点中需要多种状态,正如上文提到的,reduce任务只有在所有map任务结束之后才可以开始,因此分为map进行中、reduce进行中和全部完成三个阶段:
1 | type CoordinatorStatus int |
另外在一个运行中的coordinator节点中,可能有以下四种线程同步的运行:
- 处理“请求任务”的函数
FetchTask,需要从队列中拉取Task,如果拉不出来还需要处理其他特殊情况,涉及到状态数据集的扫描和节点状态的切换。 - 处理“提交任务”的函数
SubmitTask,需要对数据集根据完成的Task进行修改。 - 超时检查函数
timeoutDetecter(),会在后台不断的循环检查,查看数据集中是否有超时任务,如果有,重新注册任务并插入队列。 - 状态检查函数
Done(),会通过查询coordinator节点的状态来判定节点是否需要结束,每秒检查一次。由mrcoordinator.go发起,用于判断什么时候结束进程。
对于这四种情况,由于都需要访问任务数据集和coordinator节点状态,需要使用加锁来进行保护。
节点属性
在这里我给一个coordinator配置了以下几项参数:
1 | import "github.com/google/uuid" |
其中Id是节点UUID,节点启动时随机生成;Mutex是锁,用于防止上述的四种线程之间发生竞争;CoordinatorStage用于表示coordinator节点的状态;MapperTaskNum和ReducerTaskNum表示map和reduce安排的数量,其中map的数量是由文件数量决定的,reduce数量根据mrcoordinator.go传入的nReduce;TaskChannel即任务队列,每次我们都会操作队列,加入任务拉取任务;TaskSet就是我们刚才说的任务数据集;Files是这次需要处理的多个文本文件。
主函数
我们先来看启动的主函数,可以看到传入了需要处理的文件files,以及reduce任务的数量nReduce。我们需要初始化coordinator节点参数,注册所有map任务并加入队列,开启超时检查,启动RPC服务。
1 | const ChannelSize int = 10 |
不难看出我们一开始处于map进行中阶段,并开辟了一个缓冲区长度为ChannelSize的队列。
注册map任务
在所有操作的一开始,我们需要创建出worker节点需要的所有map任务,将这些任务注册在任务数据集中,然后插入队列。很显然,我们给每一个文件都分配一个Task,Task的初始状态为Waiting表示还没有开始执行:
1 | func (c *Coordinator) registerMapTasks() { |
请求任务处理函数
在请求任务处理函数FetchTask中,我们需要从任务队列中拉取任务,放进RPC的返回数据结构中。如果拉取不到,那就看看是不是当前阶段的所有任务都做完了,我们使用checkStageComplete()进行检查,如果确实全部完成了,我们再使用toNextStage()让coordinator节点切换到下一个状态。
1 | func (c *Coordinator) FetchTask(args *FetchTaskArgs, reply *FetchTaskReply) error { |
其中checkStageComplete()实现很简单,我们根据当前的coordinator状态,查看对应的map或者reduce任务数据集即可:
1 | func (c *Coordinator) checkStageComplete() bool { |
切换状态toNextStage()的逻辑也不难理解,如果当前是map处理中状态,就转reduce处理中状态,并使用registerReduceTasks()生成reduce任务,注册到任务数据集中,插入队列;如果当前是全部完成的状态,那就啥都不用做。注册reduce任务我们后面再提。
1 | func (c *Coordinator) toNextStage() { |
注册reduce任务
和注册map任务类似的逻辑,我们遵循提示中给出的命名规则信息,即mr-tmp-X-Y,其中X是map任务的ID,Y是reduce任务的ID,据此,我们将reduce任务ID对应的文件名加入各个Task中。
接下来我们依次在任务数据集中注册Task,并插入任务队列。
1 | const IntermediateNameTemplate string = "mr-tmp-%d-%d" |
提交任务处理函数
在提交任务处理中,问题就显得比较简单了,我们只需要使用刚才在任务数据集中配置的CompleteTask()函数,如果任务被重复提交了我们还会发送对应信息,贴心一点:
1 | func (c *Coordinator) SubmitTask(args *SubmitTaskArgs, reply *SubmitTaskReply) error { |
超时检查函数
在超时检查函数中,我们需要陷入一个无限循环,直到当前coordinator状态到达全部完成位置才可以退出。每次循环中,我们就根据当前coordinator状态信息确定要扫描的任务类型,调用任务数据集中已经实现的CheckTimeout(),扫出已经超时的任务列表,然后依次重新注册并加回任务队列:
1 | const TimeoutCheckInterval time.Duration = 2 |
状态检查函数
这个Done()函数就是内置的,会每隔一秒钟查看一次coordinator状态,确保查看的时候加锁就好了。另外,当coordinator处于全部完成状态时,最好不要马上退出,留点时间给worker节点退出会更好,如果他们请求了任务,那么我们还来得及回复ExitTask帮助他们优雅的退出~
其中这里的WaitInterval是worker节点在接收到WaitTask任务之后到下一次重新请求任务的等待时间,这个参数会在后续worker节点中提及。两倍是为了确保所有的worker节点都可以在coordinator退出前接到ExitTask从而优雅退出。
1 | const WaitInterval time.Duration = 2 |
Worker节点实现
主函数
在创建函数中,我们直接陷入一个无限循环,不断尝试向coordinator要求新的任务,处理掉提交任务,然后再请求新的,因此总体框架如下:
1 | var Id uuid.UUID = uuid.New() |
其中FetchTask()在worker中实现了向coordinator请求任务;SubmitTask()实现了任务完成后的提交;processMapTask()和processReduceTask()分别根据传入的mapf或者reducef方法,对任务进行处理执行。这些方法我们会后续提到。
请求任务函数
请求任务FetchTask()简单的来说就是调用call发起RPC请求,在这里我额外做了一个重试机制并且指定了在发生失败的情况下的最大重试次数:
1 | const MaxRetryTimes int = 3 |
提交任务函数
提交任务SubmitTask()简单来说也是类似的逻辑,我们只需要将Task填入RPC请求体中即可。这里顺带做了个小功能,通过时间戳计算了任务在当前worker上的执行时间,我们将其填入Msg。这里也实现了失败情况下的重试机制。
1 | func SubmitTask(task *Task) bool { |
map任务处理函数
如果是一个map任务,我们需要读取当前任务对应文件,抽取出里面的单词生成[]KeyValue键值对数组,然后根据哈希函数选择对应的reduce任务编号,并写进对应文件里,遵循提示中给出的mr-tmp-X-Y命名规则。其中的大量代码都可以借鉴mrsequential.go。
我们选择先在内存中临时存放各个文件中的数据,按照映射关系选择对应的下标加入KeyValue键值对。再依次生成临时文件,将内存中数据序列化写入文件,重命名文件。
1 | func processMapTask(mapf func(string, string) []KeyValue, task *Task) { |
映射函数使用calculateReduceBucket()来确定对应下标:
1 | func calculateReduceBucket(key string, nReduce int) int { |
reduce任务处理函数
在reduce任务中,我们需要从各个指定文件中读取内容,拼凑成一整个大[]KeyValue键值对数组。然后再模仿mrsequential.go中的相关代码,排序整合,最终写入到新文件中。
1 | // for sorting by key. |
其中读取文件生成[]KeyValue键值对数组,我们使用了readIntermediateFile()方法,不断的反序列化当前文件直到EOF:
1 | func readIntermediateFile(fileName string) []KeyValue { |
运行
以word count单词计数为例,我们进入src/main文件夹下,在coordinator节点一方运行:
1 | $ go run -race mrcoordinator.go pg-*.txt |
在worker节点一方运行:
1 | $ go build -race -buildmode=plugin ../mrapps/wc.go |
可以看到如下效果:
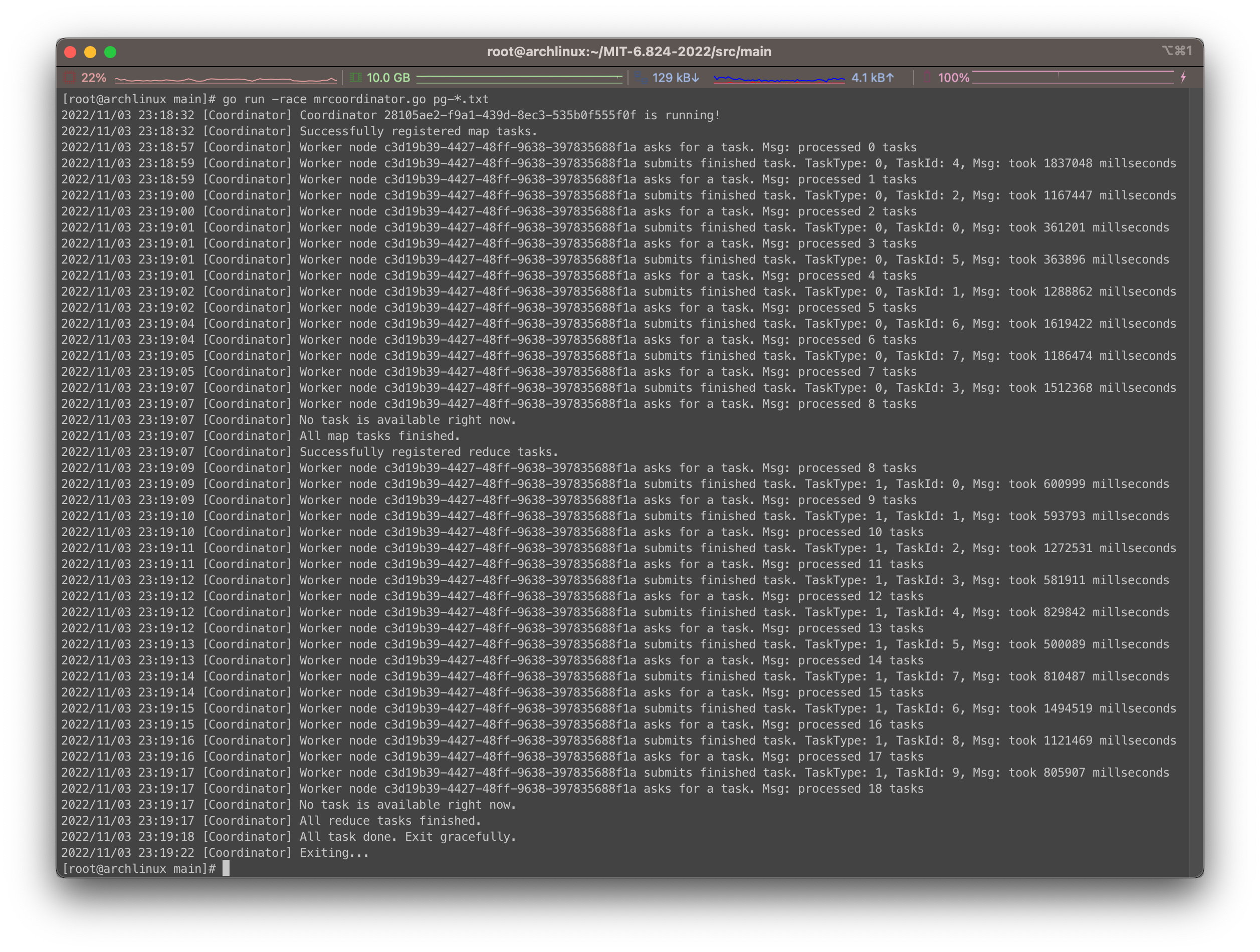
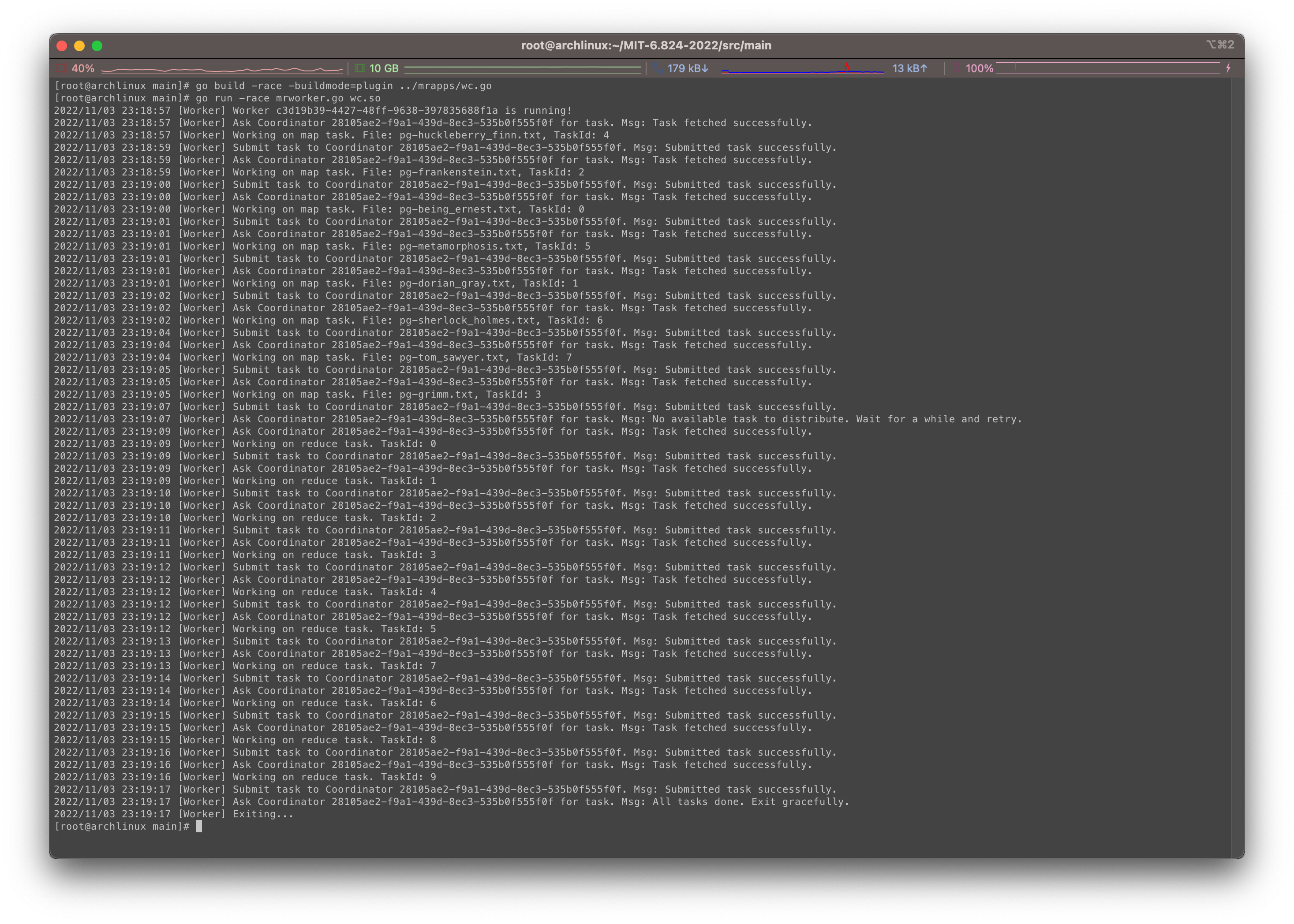
看起来还是很符合预期的。
测试
在src/main下我们执行bash ./test-mr.sh看一下能不能通过所有测试:
通过测试…
总结
从一开始的不知所措,到有所领悟脑袋里一团乱麻不知道从哪里下手,最后还是写出来了,刺激那是真的刺激…
鉴于第一个Lab就这么硬核,妈耶…




