LRU 算法小结
简介
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。该算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 t,当须淘汰一个页面时,选择现有页面中其 t 值最大的,即最近最少使用的页面予以淘汰。
当然不同的地方LRU算法的应用也略有不同:
-
操作系统
地址映射过程中,若在页面中发现所要访问的页面不在内存中,则发生缺页中断 。
缺页中断 就是要访问的页不在主存,需要操作系统将其调入主存后再进行访问。 在这个时候,被内存映射的文件实际上成了一个分页交换文件。
当发生缺页中断时,如果当前内存中并没有空闲的页面,操作系统就必须在内存选择一个页面将其移出内存,以便为即将调入的页面让出空间。用来选择淘汰哪一页的规则叫做页面置换算法,我们可以把页面置换算法看成是淘汰页面的规则。
利用局部性原理,根据一个作业在执行过程中过去的页面访问历史来推测未来的行为。它认为过去一段时间里不曾被访问过的页面,在最近的将来可能也不会再被访问。所以,这种算法的实质是:当需要淘汰一个页面时,总是选择在最近一段时间内最久不用的页面予以淘汰。
-
MySQL Buffer Pool
MySQL 在查询数据时,对于 InnoDB 存储引擎而言,会先将磁盘上的数据以页为单位,先将数据页加载进内存,然后以缓存页的形式存放在**「Buffer Pool」**中。Buffer Pool 是 InnoDB 的一块内存缓冲区,在 MySQL 启动时,会按照配置的缓存页的大小,将 Buffer Pool 缓存区初始化为许多个缓存页,默认情况下,缓存页大小为 16KB。
为了方便理解,对于磁盘上的数据所在的页,叫做数据页,当加载进 Buffer Pool 中后,叫做缓存页,这两者是一一对应的
将 LRU 算法应用到缓存页的淘汰策略上,那么就是在 InnoDB 存储引擎层内部,维护了一个链表,这些链表中的元素存储的就是指向缓存页的指针。
在 MySQL 启动的时候,这个链表为空。MySQL 启动以后,在进行数据查询时,InnoDB 会先判断要查询的数据所在的数据页,是否存在于 Buffer Pool 的缓存页当中,如果不存在,就从磁盘中读取对应数据页,存放到 Buffer Pool 一个空闲的缓存页当中,然后将这个缓冲页放入到链表的头部;如果要查询的数据已经存在于 Buffer Pool 当中了,那么就将对应的缓存页从链表的中间移动到链表头部。
这样随着 MySQL 的运行,空闲的缓存页越来越少,LRU 链表越来越长,直到某一时刻,剩余的空闲缓存页数为 0,当需要申请一个新的空闲缓存页的时候,就需要淘汰一个缓存页了,此时只需要把链表尾部的那个缓存页刷入到磁盘,然后清空缓存页里面的数据,这样就空余出一个新的缓存页了。
-
冷热分离
MySQL 的优化思路就是:对数据进行冷热分离,将 LRU 链表分成两部分,一部分用来存放冷数据,也就是刚从磁盘读进来的数据,另一部分用来存放热点数据,也就是经常被访问到数据。其中,存放冷数据的区域占这个 LRU 链表的多少呢?这由参数 「innodb_old_blocks_pct」 控制,默认是 37%(约八分之三)。
当从磁盘读取数据页后,会先将数据页存放到 LRU 链表冷数据区的头部,如果这些缓存页在 1 秒之后被访问,那么就将缓存页移动到热数据区的头部;如果是 1 秒之内被访问,则不会移动,缓存页仍然处于冷数据区中。1 秒这个数值,是由参数
innodb_old_blocks_time控制。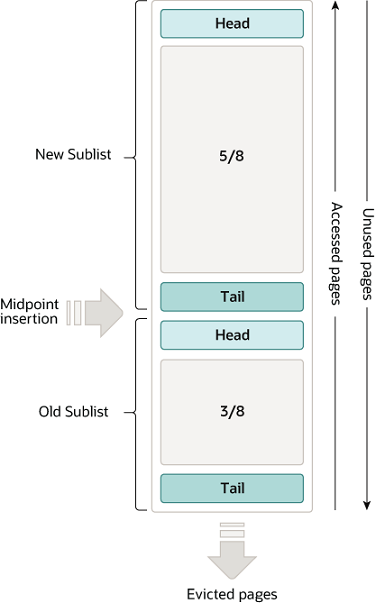
-
-
Redis LRU实现
Redis初始的实现算法很简单,随机从dict中取出五个key,淘汰一个lru字段值最小的。(随机选取的key是个可配置的参数maxmemory-samples,默认值为5).
在3.0的时候,又改进了一版算法,首先第一次随机选取的key都会放入一个pool中(pool的大小为16),pool中的key是按lru大小顺序排列的。接下来每次随机选取的keylru值必须小于pool中最小的lru才会继续放入,直到将pool放满。放满之后,每次如果有新的key需要放入,需要将pool中lru最大的一个key取出。
淘汰的时候,直接从pool中选取一个lru最小的值然后将其淘汰。

相比朴素的LRU算法需要维护一个完整的先来后到的访问链表,Redis的随机选取在一方面节省了内存方面的开销,但是也牺牲了一部分的精确程度。
朴素LRU算法的实现
我们就以这道 Leetcode 题目为例分析一下了:146. LRU 缓存机制
题目
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制 。
实现 LRUCache 类:
LRUCache(int capacity)以正整数作为容量capacity初始化 LRU 缓存int get(int key)如果关键字key存在于缓存中,则返回关键字的值,否则返回-1。void put(int key, int value)如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组「关键字-值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。
进阶:你是否可以在 O(1) 时间复杂度内完成这两种操作?
示例:
输入
[“LRUCache”, “put”, “put”, “get”, “put”, “get”, “put”, “get”, “get”, “get”]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
输出
[null, null, null, 1, null, -1, null, -1, 3, 4]解释
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
提示:
最多调用 次 get 和 put
题解
这就是一道很经典的LRU题目了
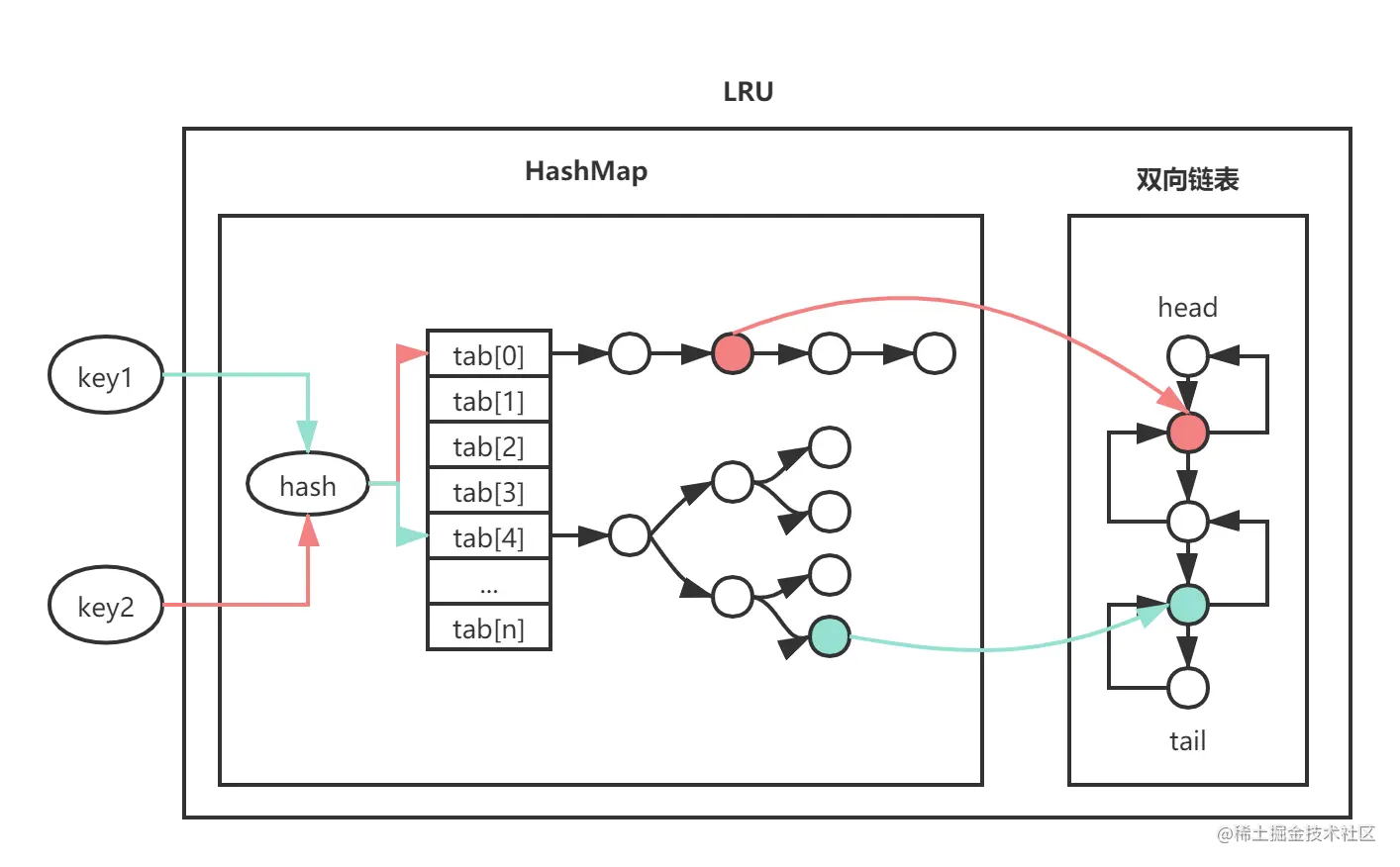
我们常常听说LRU算法是通过一个HashMap哈希表和一个双向链表组合共同完成的,那么两者分别起到了什么作用呢?
双向链表可以用来表示各个节点数据加入时的先来后到的顺序,加上双向链表优秀的数据结构,我们可以十分轻松的调节某一个节点的位置而不用付出过高的复杂度(例如将刚刚访问的节点移到链表的首部表示最近刚被使用过)
而哈希表不出意外,他的功能就很明确了,我们需要通过指定的key查找出双向链表中对应的节点,就是一个很典型的<K, V>键值对查询,即<Integer, DLinkedNode>,我们通过key的相关信息确定节点的位置,并从节点中提取到value等相关信息,同时修改当前节点的prev和next指针,使得节点被移至链表头部。
从外关于LRU的淘汰机制,我们维护一个tail节点,当LRU内部大小超出指定上限时,我们直接对tail节点进行删除操作,也就是抛弃,同时更新tail节点,同时在HashMap哈希表内部也要进行相关的更新删除操作,删除哈希表内部残余的key。
综上:
-
双向链表按照被使用的顺序存储了这些键值对,靠近头部的键值对是最近使用的,而靠近尾部的键值对是最久未使用的。
-
哈希表即为普通的哈希映射(HashMap),通过缓存数据的键映射到其在双向链表中的位置。
这样一来,我们首先使用哈希表进行定位,找出缓存项在双向链表中的位置,随后将其移动到双向链表的头部,即可在 的时间内完成 get 或者 put 操作。具体的方法如下:
-
对于
get操作,首先判断key是否存在:- 如果
key不存在,则返回 ; - 如果
key存在,则key对应的节点是最近被使用的节点。通过哈希表定位到该节点在双向链表中的位置,并将其移动到双向链表的头部,最后返回该节点的值。
- 如果
-
对于
put操作,首先判断key是否存在:-
如果
key不存在,使用key和value创建一个新的节点,在双向链表的头部添加该节点,并将key和该节点添加进哈希表中。然后判断双向链表的节点数是否超出容量,如果超出容量,则删除双向链表的尾部节点,并删除哈希表中对应的项; -
如果
key存在,则与get操作类似,先通过哈希表定位,再将对应的节点的值更新为value,并将该节点移到双向链表的头部。
-
上述各项操作中,访问哈希表的时间复杂度为 ,在双向链表的头部添加节点、在双向链表的尾部删除节点的复杂度也为 。而将一个节点移到双向链表的头部,可以分成「删除该节点」和「在双向链表的头部添加节点」两步操作,都可以在 时间内完成。
PS: 在双向链表的实现中,使用一个伪头部(dummy head)和伪尾部(dummy tail)标记界限,这样在添加节点和删除节点的时候就不需要检查相邻的节点是否存在。
1 | public class LRUCache { |
此外我们可以使用Java内部自带的LinkedHashMap类简化相关操作,由于其数据结构正好为链表,我们可以利用其特性:
1 | class LRUCache extends LinkedHashMap<Integer, Integer>{ |










