如果遇到multiple definition of 'lineno'; yas-grammar.o:(.bss+0x0): first defined here 这样的错误,我们需要分别进入misc和pipe目录下,修改内部的Makefile,添加参数-fcommon。相关解决方案在Stack overflow上:Fail to compile the Y86 simulatur (CSAPP)
如果遇到/usr/bin/ld: cannot find -ltk: No such file or directory相关报错,可能是缺少组件。在Arch Linux下,通过pacman -S tk即可解决。
/* * Architecture Lab: Part A * * High level specs for the functions that the students will rewrite * in Y86-64 assembly language */
/* $begin examples */ /* linked list element */ typedefstructELE { long val; structELE *next; } * list_ptr;
/* sum_list - Sum the elements of a linked list */ longsum_list(list_ptr ls) { long val = 0; while (ls) { val += ls->val; ls = ls->next; } return val; }
/* rsum_list - Recursive version of sum_list */ longrsum_list(list_ptr ls) { if (!ls) return0; else { long val = ls->val; long rest = rsum_list(ls->next); return val + rest; } }
/* copy_block - Copy src to dest and return xor checksum of src */ longcopy_block(long *src, long *dest, long len) { long result = 0; while (len > 0) { long val = *src++; *dest++ = val; result ^= val; len--; } return result; } /* $end examples */
typedefstructELE { long val; structELE *next; } * list_ptr;
/* sum_list - Sum the elements of a linked list */ longsum_list(list_ptr ls) { long val = 0; while (ls) { val += ls->val; ls = ls->next; } return val; }
typedefstructELE { long val; structELE *next; } * list_ptr;
/* rsum_list - Recursive version of sum_list */ longrsum_list(list_ptr ls) { if (!ls) return0; else { long val = ls->val; long rest = rsum_list(ls->next); return val + rest; } }
/* copy_block - Copy src to dest and return xor checksum of src */ longcopy_block(long *src, long *dest, long len) { long result = 0; while (len > 0) { long val = *src++; *dest++ = val; result ^= val; len--; } return result; }
#/* $begin seq-all-hcl */ #################################################################### # HCL Description of Control for Single Cycle Y86-64 Processor SEQ # # Copyright (C) Randal E. Bryant, David R. O'Hallaron, 2010 # ####################################################################
## Your task is to implement the iaddq instruction ## The file contains a declaration of the icodes ## for iaddq (IIADDQ) ## Your job is to add the rest of the logic to make it work
#################################################################### # C Include's. Don't alter these # ####################################################################
#################################################################### # Declarations. Do not change/remove/delete any of these # ####################################################################
##### Symbolic represenations of Y86-64 function codes ##### wordsig FNONE 'F_NONE' # Default function code
##### Symbolic representation of Y86-64 Registers referenced explicitly ##### wordsig RRSP 'REG_RSP' # Stack Pointer wordsig RNONE 'REG_NONE' # Special value indicating "no register"
##### ALU Functions referenced explicitly ##### wordsig ALUADD 'A_ADD' # ALU should add its arguments
##### Possible instruction status values ##### wordsig SAOK 'STAT_AOK' # Normal execution wordsig SADR 'STAT_ADR' # Invalid memory address wordsig SINS 'STAT_INS' # Invalid instruction wordsig SHLT 'STAT_HLT' # Halt instruction encountered
##### Signals that can be referenced by control logic ####################
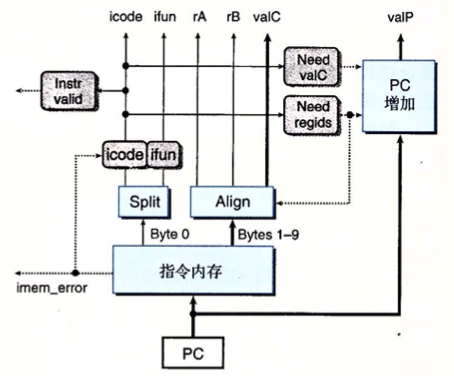
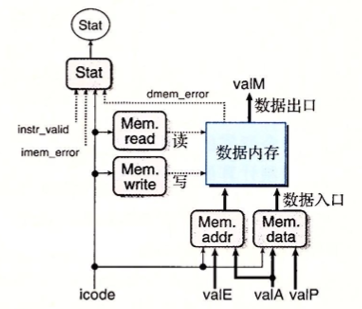
##### Fetch stage inputs ##### wordsig pc 'pc' # Program counter ##### Fetch stage computations ##### wordsig imem_icode 'imem_icode' # icode field from instruction memory wordsig imem_ifun 'imem_ifun' # ifun field from instruction memory wordsig icode 'icode' # Instruction control code wordsig ifun 'ifun' # Instruction function wordsig rA 'ra' # rA field from instruction wordsig rB 'rb' # rB field from instruction wordsig valC 'valc' # Constant from instruction wordsig valP 'valp' # Address of following instruction boolsig imem_error 'imem_error' # Error signal from instruction memory boolsig instr_valid 'instr_valid' # Is fetched instruction valid?
##### Decode stage computations ##### wordsig valA 'vala' # Value from register A port wordsig valB 'valb' # Value from register B port
##### Execute stage computations ##### wordsig valE 'vale' # Value computed by ALU boolsig Cnd 'cond' # Branch test
##### Memory stage computations ##### wordsig valM 'valm' # Value read from memory boolsig dmem_error 'dmem_error' # Error signal from data memory
#################################################################### # Control Signal Definitions. # ####################################################################
## What register should be used as the A source? word srcA = [ icode in { IRRMOVQ, IRMMOVQ, IOPQ, IPUSHQ } : rA; icode in { IPOPQ, IRET } : RRSP; 1 : RNONE; # Don't need register ];
## What register should be used as the B source? word srcB = [ icode in { IOPQ, IRMMOVQ, IMRMOVQ } : rB; icode in { IPUSHQ, IPOPQ, ICALL, IRET } : RRSP; 1 : RNONE; # Don't need register ];
## What register should be used as the E destination? word dstE = [ icode in { IRRMOVQ } && Cnd : rB; icode in { IIRMOVQ, IOPQ} : rB; icode in { IPUSHQ, IPOPQ, ICALL, IRET } : RRSP; 1 : RNONE; # Don't write any register ];
## What register should be used as the M destination? word dstM = [ icode in { IMRMOVQ, IPOPQ } : rA; 1 : RNONE; # Don't write any register ];
## Select input A to ALU word aluA = [ icode in { IRRMOVQ, IOPQ } : valA; icode in { IIRMOVQ, IRMMOVQ, IMRMOVQ } : valC; icode in { ICALL, IPUSHQ } : -8; icode in { IRET, IPOPQ } : 8; # Other instructions don't need ALU ];
## Select input B to ALU word aluB = [ icode in { IRMMOVQ, IMRMOVQ, IOPQ, ICALL, IPUSHQ, IRET, IPOPQ } : valB; icode in { IRRMOVQ, IIRMOVQ } : 0; # Other instructions don't need ALU ];
## Set the ALU function word alufun = [ icode == IOPQ : ifun; 1 : ALUADD; ];
## Should the condition codes be updated? bool set_cc = icode in { IOPQ };
## Set read control signal bool mem_read = icode in { IMRMOVQ, IPOPQ, IRET };
## Set write control signal bool mem_write = icode in { IRMMOVQ, IPUSHQ, ICALL };
## Select memory address word mem_addr = [ icode in { IRMMOVQ, IPUSHQ, ICALL, IMRMOVQ } : valE; icode in { IPOPQ, IRET } : valA; # Other instructions don't need address ];
## Select memory input data word mem_data = [ # Value from register icode in { IRMMOVQ, IPUSHQ } : valA; # Return PC icode == ICALL : valP; # Default: Don't write anything ];
## Determine instruction status word Stat = [ imem_error || dmem_error : SADR; !instr_valid: SINS; icode == IHALT : SHLT; 1 : SAOK; ];
################ Program Counter Update ############################
## What address should instruction be fetched at
word new_pc = [ # Call. Use instruction constant icode == ICALL : valC; # Taken branch. Use instruction constant icode == IJXX && Cnd : valC; # Completion of RET instruction. Use value from stack icode == IRET : valM; # Default: Use incremented PC 1 : valP; ]; #/* $end seq-all-hcl */
## What register should be used as the A source? word srcA = [ icode in { IRRMOVQ, IRMMOVQ, IOPQ, IPUSHQ } : rA; icode in { IPOPQ, IRET } : RRSP; 1 : RNONE; # Don't need register ];
## What register should be used as the B source? word srcB = [ icode in { IOPQ, IRMMOVQ, IMRMOVQ, IIADDQ } : rB; icode in { IPUSHQ, IPOPQ, ICALL, IRET } : RRSP; 1 : RNONE; # Don't need register ];
## What register should be used as the E destination? word dstE = [ icode in { IRRMOVQ } && Cnd : rB; icode in { IIRMOVQ, IOPQ, IIADDQ} : rB; icode in { IPUSHQ, IPOPQ, ICALL, IRET } : RRSP; 1 : RNONE; # Don't write any register ];
## What register should be used as the M destination? word dstM = [ icode in { IMRMOVQ, IPOPQ } : rA; 1 : RNONE; # Don't write any register ];
## Select input A to ALU word aluA = [ icode in { IRRMOVQ, IOPQ } : valA; icode in { IIRMOVQ, IRMMOVQ, IMRMOVQ, IIADDQ } : valC; icode in { ICALL, IPUSHQ } : -8; icode in { IRET, IPOPQ } : 8; # Other instructions don't need ALU ];
## Select input B to ALU word aluB = [ icode in { IRMMOVQ, IMRMOVQ, IOPQ, ICALL, IPUSHQ, IRET, IPOPQ, IIADDQ } : valB; icode in { IRRMOVQ, IIRMOVQ } : 0; # Other instructions don't need ALU ];
## Set the ALU function word alufun = [ icode == IOPQ : ifun; 1 : ALUADD; ];
## Should the condition codes be updated? bool set_cc = icode in { IOPQ, IIADDQ };
################ Program Counter Update ############################
## What address should instruction be fetched at
word new_pc = [ # Call. Use instruction constant icode == ICALL : valC; # Taken branch. Use instruction constant icode == IJXX && Cnd : valC; # Completion of RET instruction. Use value from stack icode == IRET : valM; # Default: Use incremented PC 1 : valP; ];
测试
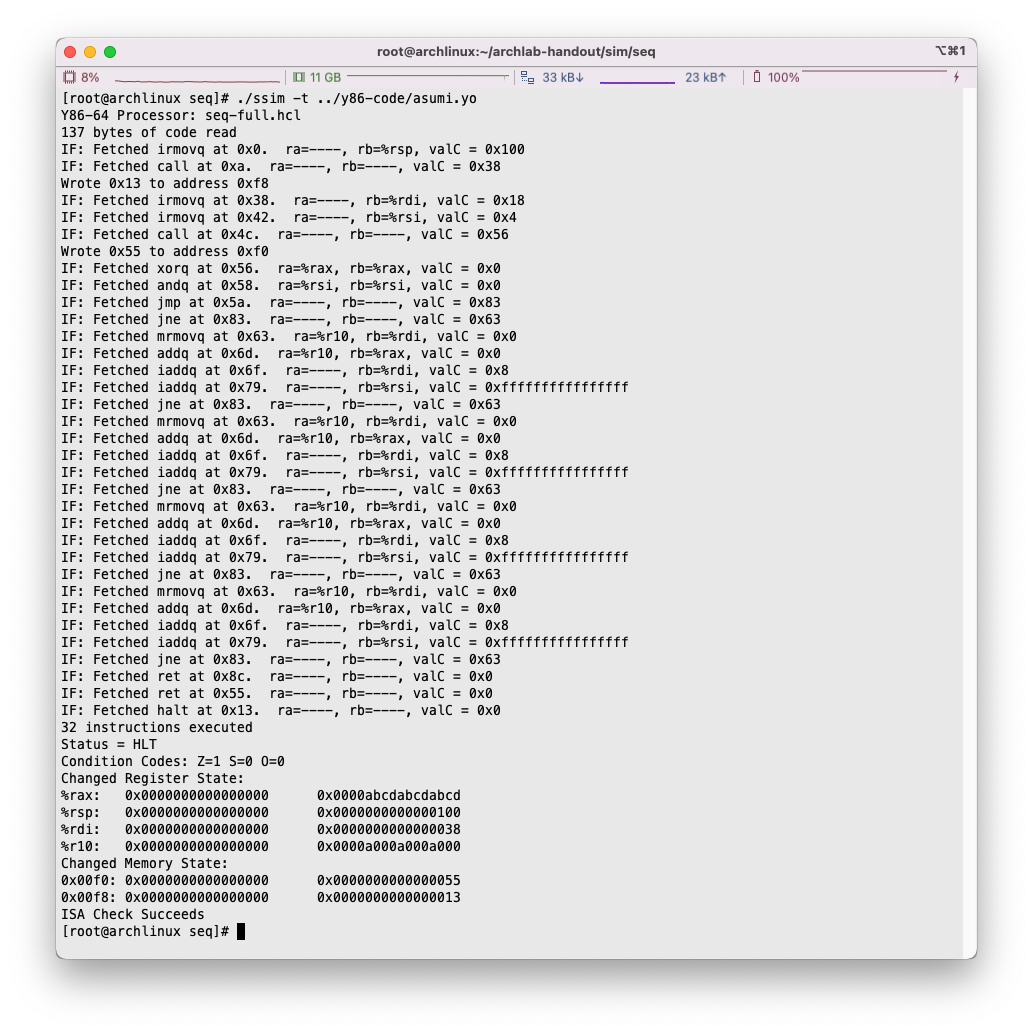
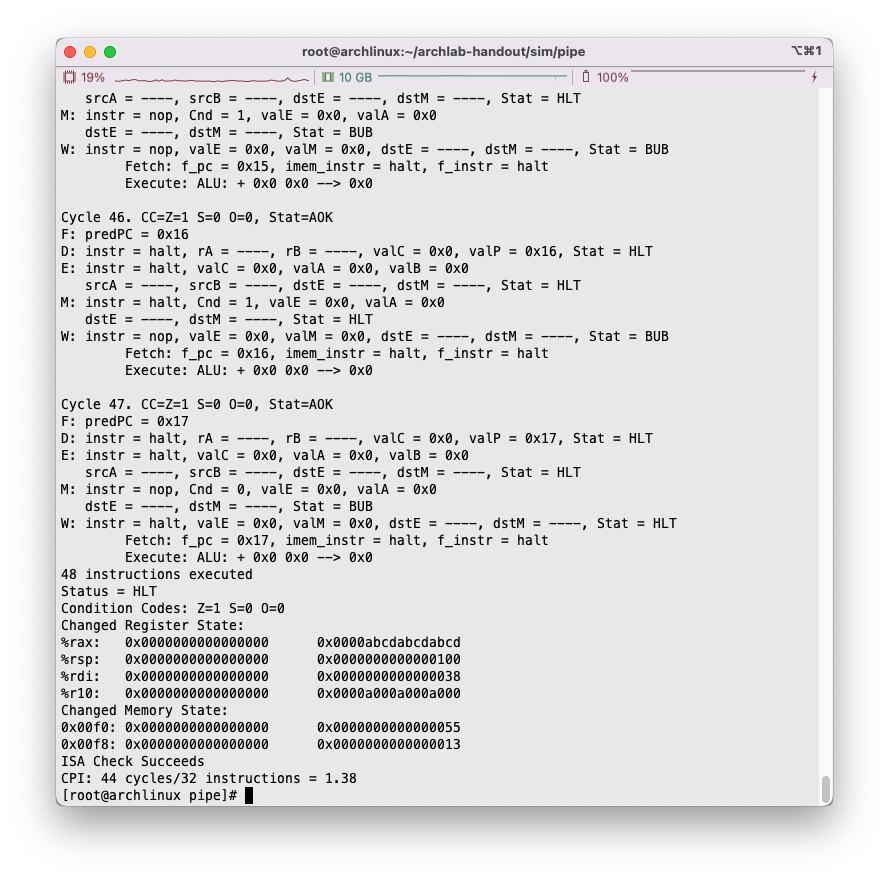
我们在sim/seq目录下,进行编译。使用命令make clean; make ssim VERSION=full。
由于tcl内部有部分数据结构已经被弃用,编译时可能会爆出错误psim.c:853:8: error: ‘Tcl_Interp’ {aka ‘struct Tcl_Interp’} has no member named ‘result’,详见Stack overflow,最简单的处理办法就是在Makefile上的CFLAGS上添加参数-DUSE_INTERP_RESULT。
#/* $begin ncopy-ys */ ################################################################## # ncopy.ys - Copy a src block of len words to dst. # Return the number of positive words (>0) contained in src. # # Include your name and ID here. # # Describe how and why you modified the baseline code. # ################################################################## # Do not modify this portion # Function prologue. # %rdi = src, %rsi = dst, %rdx = len ncopy:
################################################################## # You can modify this portion # Loop header xorq %rax,%rax # count = 0; andq %rdx,%rdx # len <= 0? jle Done # if so, goto Done:
Loop: mrmovq (%rdi), %r10 # read val from src... rmmovq %r10, (%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle Npos # if so, goto Npos: irmovq $1, %r10 addq %r10, %rax # count++ Npos: irmovq $1, %r10 subq %r10, %rdx # len-- irmovq $8, %r10 addq %r10, %rdi # src++ addq %r10, %rsi # dst++ andq %rdx,%rdx # len > 0? jg Loop # if so, goto Loop: ################################################################## # Do not modify the following section of code # Function epilogue. Done: ret ################################################################## # Keep the following label at the end of your function End: #/* $end ncopy-ys */
#/* $begin pipe-all-hcl */ #################################################################### # HCL Description of Control for Pipelined Y86-64 Processor # # Copyright (C) Randal E. Bryant, David R. O'Hallaron, 2014 # ####################################################################
## Your task is to implement the iaddq instruction ## The file contains a declaration of the icodes ## for iaddq (IIADDQ) ## Your job is to add the rest of the logic to make it work
#################################################################### # C Include's. Don't alter these # ####################################################################
#################################################################### # Declarations. Do not change/remove/delete any of these # ####################################################################
##### Symbolic represenations of Y86-64 function codes ##### wordsig FNONE 'F_NONE' # Default function code
##### Symbolic representation of Y86-64 Registers referenced ##### wordsig RRSP 'REG_RSP' # Stack Pointer wordsig RNONE 'REG_NONE' # Special value indicating "no register"
##### ALU Functions referenced explicitly ########################## wordsig ALUADD 'A_ADD' # ALU should add its arguments
##### Possible instruction status values ##### wordsig SBUB 'STAT_BUB' # Bubble in stage wordsig SAOK 'STAT_AOK' # Normal execution wordsig SADR 'STAT_ADR' # Invalid memory address wordsig SINS 'STAT_INS' # Invalid instruction wordsig SHLT 'STAT_HLT' # Halt instruction encountered
##### Signals that can be referenced by control logic ##############
##### Pipeline Register F ##########################################
wordsig F_predPC 'pc_curr->pc' # Predicted value of PC
##### Intermediate Values in Fetch Stage ###########################
wordsig imem_icode 'imem_icode' # icode field from instruction memory wordsig imem_ifun 'imem_ifun' # ifun field from instruction memory wordsig f_icode 'if_id_next->icode' # (Possibly modified) instruction code wordsig f_ifun 'if_id_next->ifun' # Fetched instruction function wordsig f_valC 'if_id_next->valc' # Constant data of fetched instruction wordsig f_valP 'if_id_next->valp' # Address of following instruction boolsig imem_error 'imem_error' # Error signal from instruction memory boolsig instr_valid 'instr_valid' # Is fetched instruction valid?
##### Pipeline Register D ########################################## wordsig D_icode 'if_id_curr->icode' # Instruction code wordsig D_rA 'if_id_curr->ra' # rA field from instruction wordsig D_rB 'if_id_curr->rb' # rB field from instruction wordsig D_valP 'if_id_curr->valp' # Incremented PC
##### Intermediate Values in Decode Stage #########################
wordsig d_srcA 'id_ex_next->srca' # srcA from decoded instruction wordsig d_srcB 'id_ex_next->srcb' # srcB from decoded instruction wordsig d_rvalA 'd_regvala' # valA read from register file wordsig d_rvalB 'd_regvalb' # valB read from register file
##### Pipeline Register E ########################################## wordsig E_icode 'id_ex_curr->icode' # Instruction code wordsig E_ifun 'id_ex_curr->ifun' # Instruction function wordsig E_valC 'id_ex_curr->valc' # Constant data wordsig E_srcA 'id_ex_curr->srca' # Source A register ID wordsig E_valA 'id_ex_curr->vala' # Source A value wordsig E_srcB 'id_ex_curr->srcb' # Source B register ID wordsig E_valB 'id_ex_curr->valb' # Source B value wordsig E_dstE 'id_ex_curr->deste' # Destination E register ID wordsig E_dstM 'id_ex_curr->destm' # Destination M register ID
##### Intermediate Values in Execute Stage ######################### wordsig e_valE 'ex_mem_next->vale' # valE generated by ALU boolsig e_Cnd 'ex_mem_next->takebranch' # Does condition hold? wordsig e_dstE 'ex_mem_next->deste' # dstE (possibly modified to be RNONE)
##### Pipeline Register M ######################### wordsig M_stat 'ex_mem_curr->status' # Instruction status wordsig M_icode 'ex_mem_curr->icode' # Instruction code wordsig M_ifun 'ex_mem_curr->ifun' # Instruction function wordsig M_valA 'ex_mem_curr->vala' # Source A value wordsig M_dstE 'ex_mem_curr->deste' # Destination E register ID wordsig M_valE 'ex_mem_curr->vale' # ALU E value wordsig M_dstM 'ex_mem_curr->destm' # Destination M register ID boolsig M_Cnd 'ex_mem_curr->takebranch' # Condition flag boolsig dmem_error 'dmem_error' # Error signal from instruction memory
##### Intermediate Values in Memory Stage ########################## wordsig m_valM 'mem_wb_next->valm' # valM generated by memory wordsig m_stat 'mem_wb_next->status' # stat (possibly modified to be SADR)
##### Pipeline Register W ########################################## wordsig W_stat 'mem_wb_curr->status' # Instruction status wordsig W_icode 'mem_wb_curr->icode' # Instruction code wordsig W_dstE 'mem_wb_curr->deste' # Destination E register ID wordsig W_valE 'mem_wb_curr->vale' # ALU E value wordsig W_dstM 'mem_wb_curr->destm' # Destination M register ID wordsig W_valM 'mem_wb_curr->valm' # Memory M value
#################################################################### # Control Signal Definitions. # ####################################################################
## What address should instruction be fetched at word f_pc = [ # Mispredicted branch. Fetch at incremented PC M_icode == IJXX && !M_Cnd : M_valA; # Completion of RET instruction W_icode == IRET : W_valM; # Default: Use predicted value of PC 1 : F_predPC; ];
## Determine icode of fetched instruction word f_icode = [ imem_error : INOP; 1: imem_icode; ];
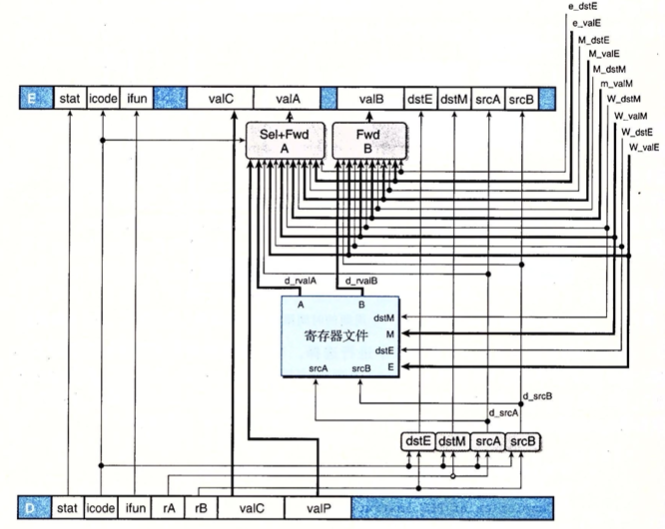
## What register should be used as the A source? word d_srcA = [ D_icode in { IRRMOVQ, IRMMOVQ, IOPQ, IPUSHQ } : D_rA; D_icode in { IPOPQ, IRET } : RRSP; 1 : RNONE; # Don't need register ];
## What register should be used as the B source? word d_srcB = [ D_icode in { IOPQ, IRMMOVQ, IMRMOVQ } : D_rB; D_icode in { IPUSHQ, IPOPQ, ICALL, IRET } : RRSP; 1 : RNONE; # Don't need register ];
## What register should be used as the E destination? word d_dstE = [ D_icode in { IRRMOVQ, IIRMOVQ, IOPQ} : D_rB; D_icode in { IPUSHQ, IPOPQ, ICALL, IRET } : RRSP; 1 : RNONE; # Don't write any register ];
## What register should be used as the M destination? word d_dstM = [ D_icode in { IMRMOVQ, IPOPQ } : D_rA; 1 : RNONE; # Don't write any register ];
## What should be the A value? ## Forward into decode stage for valA word d_valA = [ D_icode in { ICALL, IJXX } : D_valP; # Use incremented PC d_srcA == e_dstE : e_valE; # Forward valE from execute d_srcA == M_dstM : m_valM; # Forward valM from memory d_srcA == M_dstE : M_valE; # Forward valE from memory d_srcA == W_dstM : W_valM; # Forward valM from write back d_srcA == W_dstE : W_valE; # Forward valE from write back 1 : d_rvalA; # Use value read from register file ];
word d_valB = [ d_srcB == e_dstE : e_valE; # Forward valE from execute d_srcB == M_dstM : m_valM; # Forward valM from memory d_srcB == M_dstE : M_valE; # Forward valE from memory d_srcB == W_dstM : W_valM; # Forward valM from write back d_srcB == W_dstE : W_valE; # Forward valE from write back 1 : d_rvalB; # Use value read from register file ];
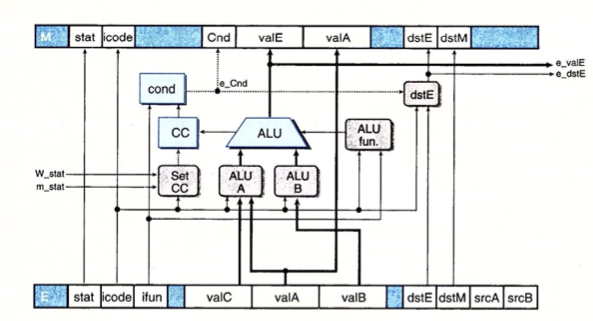
## Select input A to ALU word aluA = [ E_icode in { IRRMOVQ, IOPQ } : E_valA; E_icode in { IIRMOVQ, IRMMOVQ, IMRMOVQ } : E_valC; E_icode in { ICALL, IPUSHQ } : -8; E_icode in { IRET, IPOPQ } : 8; # Other instructions don't need ALU ];
## Select input B to ALU word aluB = [ E_icode in { IRMMOVQ, IMRMOVQ, IOPQ, ICALL, IPUSHQ, IRET, IPOPQ } : E_valB; E_icode in { IRRMOVQ, IIRMOVQ } : 0; # Other instructions don't need ALU ];
## Set the ALU function word alufun = [ E_icode == IOPQ : E_ifun; 1 : ALUADD; ];
## Should the condition codes be updated? bool set_cc = E_icode == IOPQ && # State changes only during normal operation !m_stat in { SADR, SINS, SHLT } && !W_stat in { SADR, SINS, SHLT };
## Generate valA in execute stage word e_valA = E_valA; # Pass valA through stage
## Set dstE to RNONE in event of not-taken conditional move word e_dstE = [ E_icode == IRRMOVQ && !e_Cnd : RNONE; 1 : E_dstE; ];
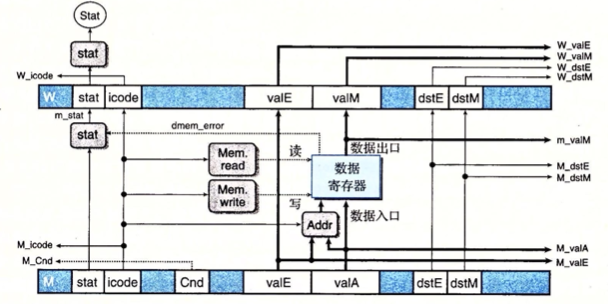
## Select memory address word mem_addr = [ M_icode in { IRMMOVQ, IPUSHQ, ICALL, IMRMOVQ } : M_valE; M_icode in { IPOPQ, IRET } : M_valA; # Other instructions don't need address ];
## Set read control signal bool mem_read = M_icode in { IMRMOVQ, IPOPQ, IRET };
## Set write control signal bool mem_write = M_icode in { IRMMOVQ, IPUSHQ, ICALL };
#/* $begin pipe-m_stat-hcl */ ## Update the status word m_stat = [ dmem_error : SADR; 1 : M_stat; ]; #/* $end pipe-m_stat-hcl */
## Set E port register ID word w_dstE = W_dstE;
## Set E port value word w_valE = W_valE;
## Set M port register ID word w_dstM = W_dstM;
## Set M port value word w_valM = W_valM;
## Update processor status word Stat = [ W_stat == SBUB : SAOK; 1 : W_stat; ];
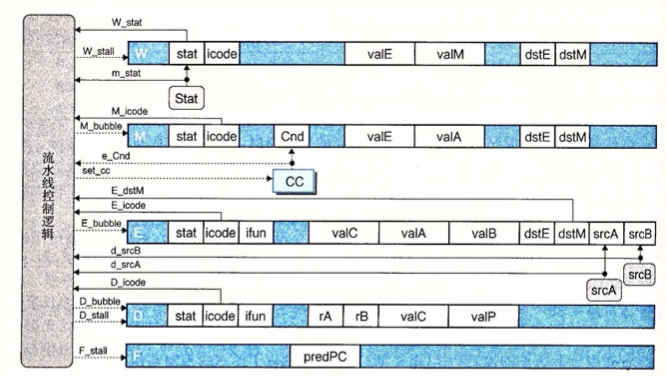
################ Pipeline Register Control #########################
# Should I stall or inject a bubble into Pipeline Register F? # At most one of these can be true. bool F_bubble = 0; bool F_stall = # Conditions for a load/use hazard E_icode in { IMRMOVQ, IPOPQ } && E_dstM in { d_srcA, d_srcB } || # Stalling at fetch while ret passes through pipeline IRET in { D_icode, E_icode, M_icode };
# Should I stall or inject a bubble into Pipeline Register D? # At most one of these can be true. bool D_stall = # Conditions for a load/use hazard E_icode in { IMRMOVQ, IPOPQ } && E_dstM in { d_srcA, d_srcB };
bool D_bubble = # Mispredicted branch (E_icode == IJXX && !e_Cnd) || # Stalling at fetch while ret passes through pipeline # but not condition for a load/use hazard !(E_icode in { IMRMOVQ, IPOPQ } && E_dstM in { d_srcA, d_srcB }) && IRET in { D_icode, E_icode, M_icode };
# Should I stall or inject a bubble into Pipeline Register E? # At most one of these can be true. bool E_stall = 0; bool E_bubble = # Mispredicted branch (E_icode == IJXX && !e_Cnd) || # Conditions for a load/use hazard E_icode in { IMRMOVQ, IPOPQ } && E_dstM in { d_srcA, d_srcB};
# Should I stall or inject a bubble into Pipeline Register M? # At most one of these can be true. bool M_stall = 0; # Start injecting bubbles as soon as exception passes through memory stage bool M_bubble = m_stat in { SADR, SINS, SHLT } || W_stat in { SADR, SINS, SHLT };
# Should I stall or inject a bubble into Pipeline Register W? bool W_stall = W_stat in { SADR, SINS, SHLT }; bool W_bubble = 0; #/* $end pipe-all-hcl */
## What address should instruction be fetched at word f_pc = [ # Mispredicted branch. Fetch at incremented PC M_icode == IJXX && !M_Cnd : M_valA; # Completion of RET instruction W_icode == IRET : W_valM; # Default: Use predicted value of PC 1 : F_predPC; ];
## Determine icode of fetched instruction word f_icode = [ imem_error : INOP; 1: imem_icode; ];
## What register should be used as the A source? word d_srcA = [ D_icode in { IRRMOVQ, IRMMOVQ, IOPQ, IPUSHQ } : D_rA; D_icode in { IPOPQ, IRET } : RRSP; 1 : RNONE; # Don't need register ];
## What register should be used as the B source? word d_srcB = [ D_icode in { IOPQ, IRMMOVQ, IMRMOVQ, IIADDQ } : D_rB; D_icode in { IPUSHQ, IPOPQ, ICALL, IRET } : RRSP; 1 : RNONE; # Don't need register ];
## What register should be used as the E destination? word d_dstE = [ D_icode in { IRRMOVQ, IIRMOVQ, IOPQ, IIADDQ} : D_rB; D_icode in { IPUSHQ, IPOPQ, ICALL, IRET } : RRSP; 1 : RNONE; # Don't write any register ];
## What register should be used as the M destination? word d_dstM = [ D_icode in { IMRMOVQ, IPOPQ } : D_rA; 1 : RNONE; # Don't write any register ];
## What should be the A value? ## Forward into decode stage for valA word d_valA = [ D_icode in { ICALL, IJXX } : D_valP; # Use incremented PC d_srcA == e_dstE : e_valE; # Forward valE from execute d_srcA == M_dstM : m_valM; # Forward valM from memory d_srcA == M_dstE : M_valE; # Forward valE from memory d_srcA == W_dstM : W_valM; # Forward valM from write back d_srcA == W_dstE : W_valE; # Forward valE from write back 1 : d_rvalA; # Use value read from register file ];
word d_valB = [ d_srcB == e_dstE : e_valE; # Forward valE from execute d_srcB == M_dstM : m_valM; # Forward valM from memory d_srcB == M_dstE : M_valE; # Forward valE from memory d_srcB == W_dstM : W_valM; # Forward valM from write back d_srcB == W_dstE : W_valE; # Forward valE from write back 1 : d_rvalB; # Use value read from register file ];
## Select input A to ALU word aluA = [ E_icode in { IRRMOVQ, IOPQ } : E_valA; E_icode in { IIRMOVQ, IRMMOVQ, IMRMOVQ, IIADDQ } : E_valC; E_icode in { ICALL, IPUSHQ } : -8; E_icode in { IRET, IPOPQ } : 8; # Other instructions don't need ALU ];
## Select input B to ALU word aluB = [ E_icode in { IRMMOVQ, IMRMOVQ, IOPQ, ICALL, IPUSHQ, IRET, IPOPQ, IIADDQ } : E_valB; E_icode in { IRRMOVQ, IIRMOVQ } : 0; # Other instructions don't need ALU ];
## Set the ALU function word alufun = [ E_icode == IOPQ : E_ifun; 1 : ALUADD; ];
## Should the condition codes be updated? bool set_cc = E_icode in {IOPQ, IIADDQ} && # State changes only during normal operation !m_stat in { SADR, SINS, SHLT } && !W_stat in { SADR, SINS, SHLT };
## Generate valA in execute stage word e_valA = E_valA; # Pass valA through stage
## Set dstE to RNONE in event of not-taken conditional move word e_dstE = [ E_icode == IRRMOVQ && !e_Cnd : RNONE; 1 : E_dstE; ];
################ Pipeline Register Control #########################
# Should I stall or inject a bubble into Pipeline Register F? # At most one of these can be true. bool F_bubble = 0; bool F_stall = # Conditions for a load/use hazard E_icode in { IMRMOVQ, IPOPQ } && E_dstM in { d_srcA, d_srcB } || # Stalling at fetch while ret passes through pipeline IRET in { D_icode, E_icode, M_icode };
# Should I stall or inject a bubble into Pipeline Register D? # At most one of these can be true. bool D_stall = # Conditions for a load/use hazard E_icode in { IMRMOVQ, IPOPQ } && E_dstM in { d_srcA, d_srcB };
bool D_bubble = # Mispredicted branch (E_icode == IJXX && !e_Cnd) || # Stalling at fetch while ret passes through pipeline # but not condition for a load/use hazard !(E_icode in { IMRMOVQ, IPOPQ } && E_dstM in { d_srcA, d_srcB }) && IRET in { D_icode, E_icode, M_icode };
# Should I stall or inject a bubble into Pipeline Register E? # At most one of these can be true. bool E_stall = 0; bool E_bubble = # Mispredicted branch (E_icode == IJXX && !e_Cnd) || # Conditions for a load/use hazard E_icode in { IMRMOVQ, IPOPQ } && E_dstM in { d_srcA, d_srcB};
# Should I stall or inject a bubble into Pipeline Register M? # At most one of these can be true. bool M_stall = 0; # Start injecting bubbles as soon as exception passes through memory stage bool M_bubble = m_stat in { SADR, SINS, SHLT } || W_stat in { SADR, SINS, SHLT };
# Should I stall or inject a bubble into Pipeline Register W? bool W_stall = W_stat in { SADR, SINS, SHLT }; bool W_bubble = 0;
测试
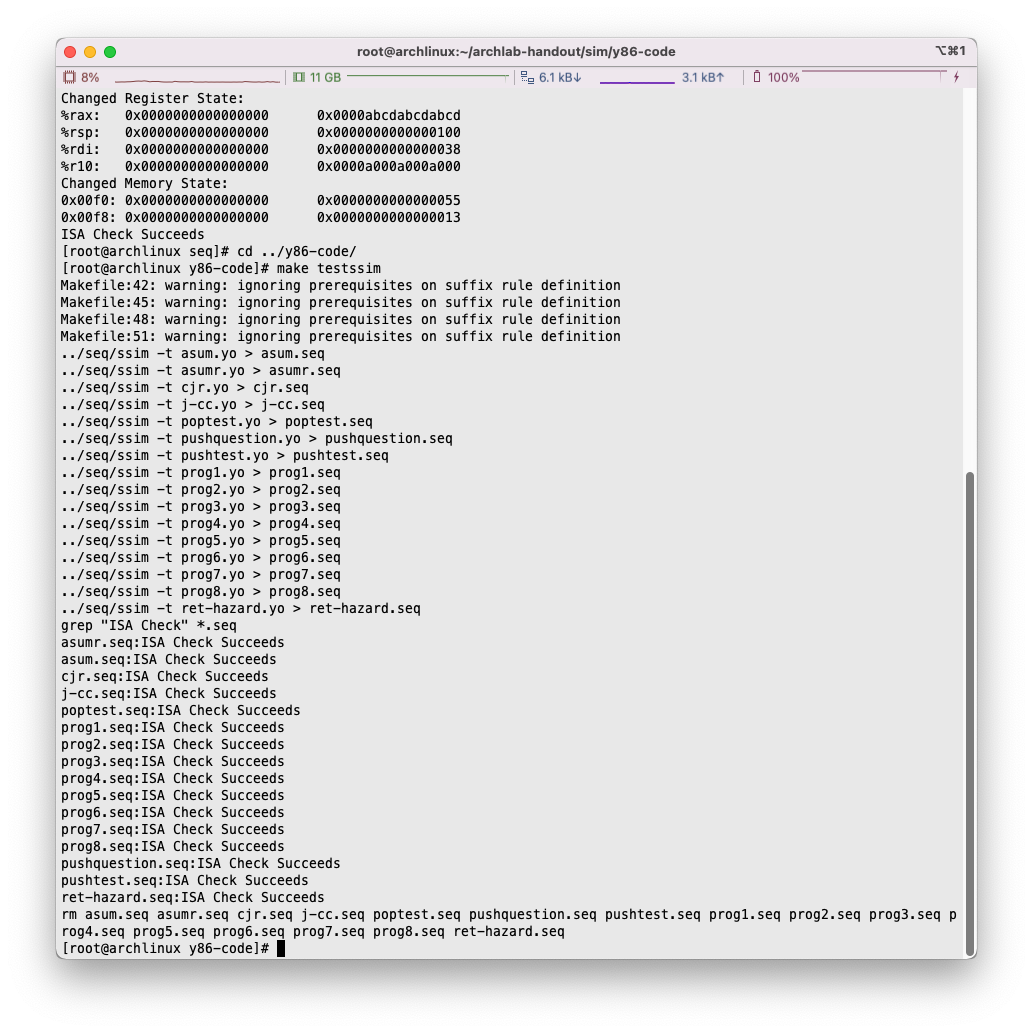
不管怎么说,我们先对刚才修改完成的hcl文件进行测试,我们使用命令make clean; make VERSION=full。
我们在编译时也会遇到类似Part B的错误:
由于 tcl 内部有部分数据结构已经被弃用,编译时可能会爆出错误 psim.c:853:8: error: ‘Tcl_Interp’ {aka ‘struct Tcl_Interp’} has no member named ‘result’,详见 Stack overflow,最简单的处理办法就是在 Makefile 上的 CFLAGS 上添加参数 -DUSE_INTERP_RESULT。
#/* $begin ncopy-ys */ ################################################################## # ncopy.ys - Copy a src block of len words to dst. # Return the number of positive words (>0) contained in src. # # Include your name and ID here. # # Describe how and why you modified the baseline code. # ################################################################## # Do not modify this portion # Function prologue. # %rdi = src, %rsi = dst, %rdx = len ncopy:
################################################################## # You can modify this portion # Loop header xorq %rax,%rax # count = 0; andq %rdx,%rdx # len <= 0? jle Done # if so, goto Done:
Loop: mrmovq (%rdi), %r10 # read val from src... rmmovq %r10, (%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle Npos # if so, goto Npos: irmovq $1, %r10 addq %r10, %rax # count++ Npos: irmovq $1, %r10 subq %r10, %rdx # len-- irmovq $8, %r10 addq %r10, %rdi # src++ addq %r10, %rsi # dst++ andq %rdx,%rdx # len > 0? jg Loop # if so, goto Loop: ################################################################## # Do not modify the following section of code # Function epilogue. Done: ret ################################################################## # Keep the following label at the end of your function End: #/* $end ncopy-ys */
#/* $begin ncopy-ys */ ################################################################## # ncopy.ys - Copy a src block of len words to dst. # Return the number of positive words (>0) contained in src. # # Include your name and ID here. # # Describe how and why you modified the baseline code. # ################################################################## # Do not modify this portion # Function prologue. # %rdi = src, %rsi = dst, %rdx = len ncopy:
################################################################## # You can modify this portion # Loop header xorq %rax,%rax # count = 0; andq %rdx,%rdx # len <= 0? jle Done # if so, goto Done:
Loop: mrmovq (%rdi), %r10 # read val from src... rmmovq %r10, (%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle Npos # if so, goto Npos: iaddq $1, %rax # count++ Npos: iaddq $-1, %rdx # len-- iaddq $8, %rdi # src++ iaddq $8, %rsi # dst++ andq %rdx,%rdx # len > 0? jg Loop # if so, goto Loop: ################################################################## # Do not modify the following section of code # Function epilogue. Done: ret ################################################################## # Keep the following label at the end of your function End: #/* $end ncopy-ys */
#/* $begin ncopy-ys */ ################################################################## # ncopy.ys - Copy a src block of len words to dst. # Return the number of positive words (>0) contained in src. # # Include your name and ID here. # # Describe how and why you modified the baseline code. # ################################################################## # Do not modify this portion # Function prologue. # %rdi = src, %rsi = dst, %rdx = len ncopy:
################################################################## # You can modify this portion # Loop header andq %rdx,%rdx # len <= 0? jmp test Loop: mrmovq (%rdi),%r10 rmmovq %r10,(%rsi) andq %r10,%r10 jle Loop1 iaddq $1,%rax Loop1: mrmovq 8(%rdi),%r10 rmmovq %r10,8(%rsi) andq %r10,%r10 jle Loop2 iaddq $1,%rax Loop2: mrmovq 16(%rdi),%r10 rmmovq %r10,16(%rsi) andq %r10,%r10 jle Loop3 iaddq $1,%rax Loop3: mrmovq 24(%rdi),%r10 rmmovq %r10,24(%rsi) andq %r10,%r10 jle Loop4 iaddq $1,%rax Loop4: mrmovq 32(%rdi),%r10 rmmovq %r10,32(%rsi) andq %r10,%r10 jle Loop5 iaddq $1,%rax Loop5: mrmovq 40(%rdi),%r10 rmmovq %r10,40(%rsi) iaddq $48,%rdi iaddq $48,%rsi andq %r10,%r10 jle test iaddq $1,%rax test: iaddq $-6, %rdx # 判断是否满6 jge Loop # 6路展开 iaddq $-8,%rdi iaddq $-8,%rsi iaddq $6, %rdx # 否则恢复原状 jmp test2 #剩下的逐次一个一个处理 Remain: mrmovq (%rdi),%r10 rmmovq %r10,(%rsi) andq %r10,%r10 jle test2 iaddq $1,%rax test2: iaddq $8,%rdi iaddq $8,%rsi iaddq $-1, %rdx jge Remain ################################################################## # Do not modify the following section of code # Function epilogue. Done: ret ################################################################## # Keep the following label at the end of your function End: #/* $end ncopy-ys */
#/* $begin ncopy-ys */ ################################################################## # ncopy.ys - Copy a src block of len words to dst. # Return the number of positive words (>0) contained in src. # # Include your name and ID here. # # Describe how and why you modified the baseline code. # ################################################################## # Do not modify this portion # Function prologue. # %rdi = src, %rsi = dst, %rdx = len ncopy:
################################################################## # You can modify this portion # Loop header andq %rdx,%rdx # len <= 0? jmp test Loop: mrmovq (%rdi),%r10 rmmovq %r10,(%rsi) andq %r10,%r10 jle Loop1 iaddq $1,%rax Loop1: mrmovq 8(%rdi),%r10 rmmovq %r10,8(%rsi) andq %r10,%r10 jle Loop2 iaddq $1,%rax Loop2: mrmovq 16(%rdi),%r10 rmmovq %r10,16(%rsi) andq %r10,%r10 jle Loop3 iaddq $1,%rax Loop3: mrmovq 24(%rdi),%r10 rmmovq %r10,24(%rsi) andq %r10,%r10 jle Loop4 iaddq $1,%rax Loop4: mrmovq 32(%rdi),%r10 rmmovq %r10,32(%rsi) andq %r10,%r10 jle Loop5 iaddq $1,%rax Loop5: mrmovq 40(%rdi),%r10 rmmovq %r10,40(%rsi) iaddq $48,%rdi iaddq $48,%rsi andq %r10,%r10 jle test iaddq $1,%rax test: iaddq $-6, %rdx jge Loop iaddq $6, %rdx jmp test2 L: mrmovq (%rdi),%r10 rmmovq %r10,(%rsi) andq %r10,%r10 jle L1 iaddq $1,%rax L1: mrmovq 8(%rdi),%r10 rmmovq %r10,8(%rsi) andq %r10,%r10 jle L2 iaddq $1,%rax L2: mrmovq 16(%rdi),%r10 rmmovq %r10,16(%rsi) iaddq $24,%rdi iaddq $24,%rsi andq %r10,%r10 jle test2 iaddq $1,%rax test2: iaddq $-3, %rdx # 先减,判断够不够3个 jge L iaddq $2, %rdx # -1则不剩了,直接Done,0 剩一个, 1剩2个 je R0 jl Done mrmovq (%rdi),%r10 rmmovq %r10,(%rsi) andq %r10,%r10 jle R2 iaddq $1,%rax R2: mrmovq 8(%rdi),%r10 rmmovq %r10,8(%rsi) andq %r10,%r10 jle Done iaddq $1,%rax jmp Done R0: mrmovq (%rdi),%r10 rmmovq %r10,(%rsi) andq %r10,%r10 jle Done iaddq $1,%rax ################################################################## # Do not modify the following section of code # Function epilogue. Done: ret ################################################################## # Keep the following label at the end of your function End: #/* $end ncopy-ys */
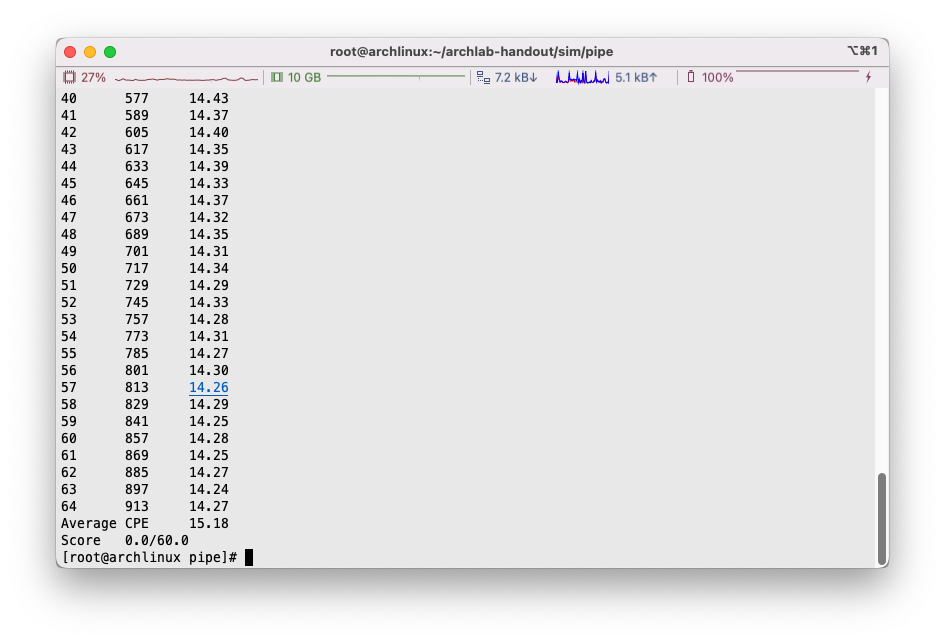
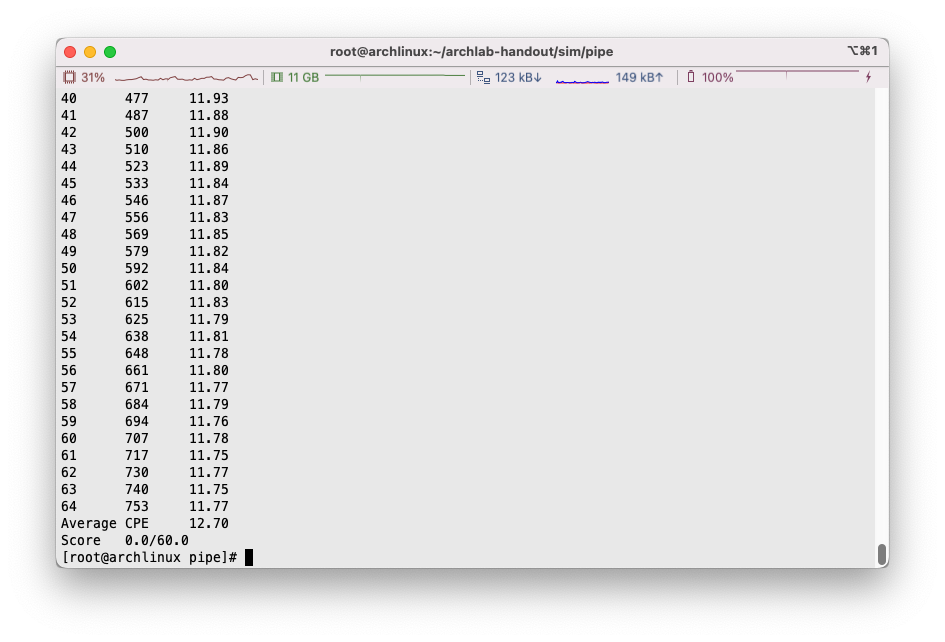
通过对剩余的长度小于6的数组进行3路循环展开优化,我们进一步提升了CPE测试结果:
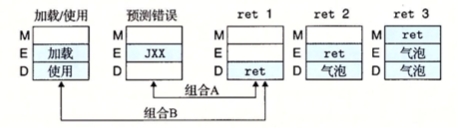
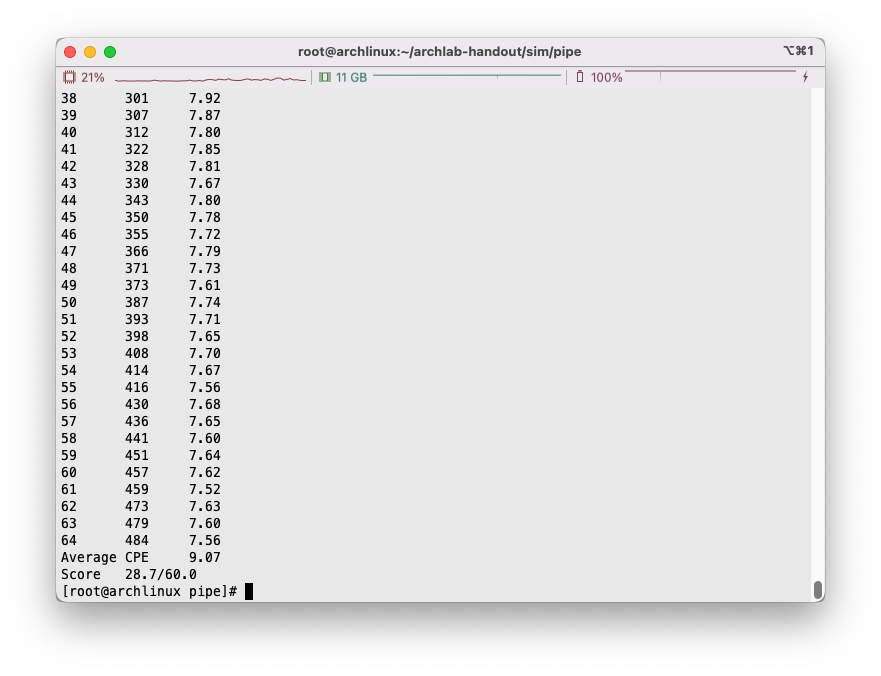
消除气泡
在刚才的程序中,根据注释提示不难看出,存在加载/使用冒险:
1 2
mrmovq (%rdi), %r10 # read val from src... rmmovq %r10, (%rsi) # ...and store it to dst
#/* $begin ncopy-ys */ ################################################################## # ncopy.ys - Copy a src block of len words to dst. # Return the number of positive words (>0) contained in src. # # Include your name and ID here. # # Describe how and why you modified the baseline code. # ################################################################## # Do not modify this portion # Function prologue. # %rdi = src, %rsi = dst, %rdx = len ncopy:
################################################################## # You can modify this portion # Loop header andq %rdx,%rdx # len <= 0? jmp test Loop: mrmovq (%rdi),%r10 mrmovq 8(%rdi),%r11 rmmovq %r10,(%rsi) rmmovq %r11,8(%rsi) andq %r10,%r10 jle Loop1 iaddq $1,%rax Loop1: andq %r11,%r11 jle Loop2 iaddq $1,%rax Loop2: mrmovq 16(%rdi),%r10 mrmovq 24(%rdi),%r11 rmmovq %r10,16(%rsi) rmmovq %r11,24(%rsi) andq %r10,%r10 jle Loop3 iaddq $1,%rax Loop3: andq %r11,%r11 jle Loop4 iaddq $1,%rax Loop4: mrmovq 32(%rdi),%r10 mrmovq 40(%rdi),%r11 rmmovq %r10,32(%rsi) rmmovq %r11,40(%rsi) andq %r10,%r10 jle Loop5 iaddq $1,%rax Loop5: iaddq $48,%rdi iaddq $48,%rsi andq %r11,%r11 jle test iaddq $1,%rax test: iaddq $-6, %rdx jge Loop iaddq $6, %rdx jmp test2 L: mrmovq (%rdi),%r10 mrmovq 8(%rdi),%r11 rmmovq %r10,(%rsi) rmmovq %r11,8(%rsi) andq %r10,%r10 jle L1 iaddq $1,%rax L1: andq %r11,%r11 jle L2 iaddq $1,%rax L2: mrmovq 16(%rdi),%r10 iaddq $24,%rdi rmmovq %r10,16(%rsi) iaddq $24,%rsi andq %r10,%r10 jle test2 iaddq $1,%rax test2: iaddq $-3, %rdx # 先减,判断够不够3个 jge L iaddq $2, %rdx # -1则不剩了,直接Done,0 剩一个, 1剩2个 je R0 jl Done mrmovq (%rdi),%r10 rmmovq %r10,(%rsi) andq %r10,%r10 jle R2 iaddq $1,%rax R2: mrmovq 8(%rdi),%r10 rmmovq %r10,8(%rsi) andq %r10,%r10 jle Done iaddq $1,%rax jmp Done R0: mrmovq (%rdi),%r10 rmmovq %r10,(%rsi) andq %r10,%r10 jle Done iaddq $1,%rax ################################################################## # Do not modify the following section of code # Function epilogue. Done: ret ################################################################## # Keep the following label at the end of your function End: #/* $end ncopy-ys */