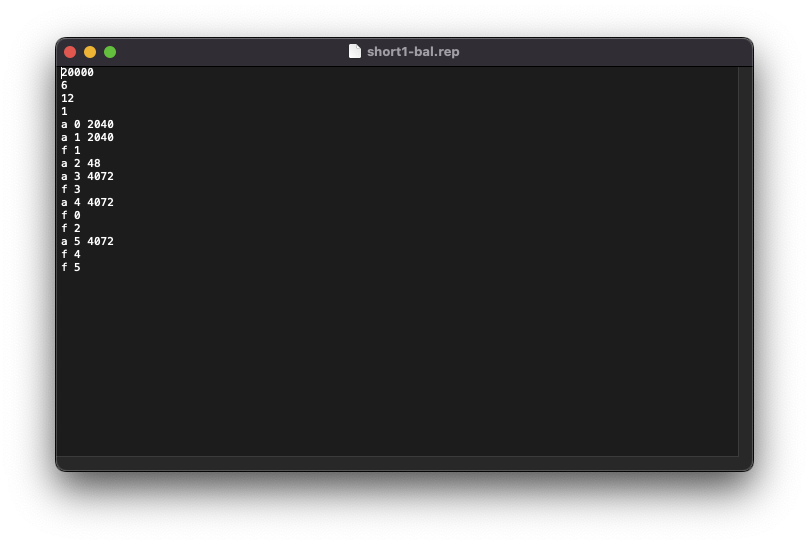
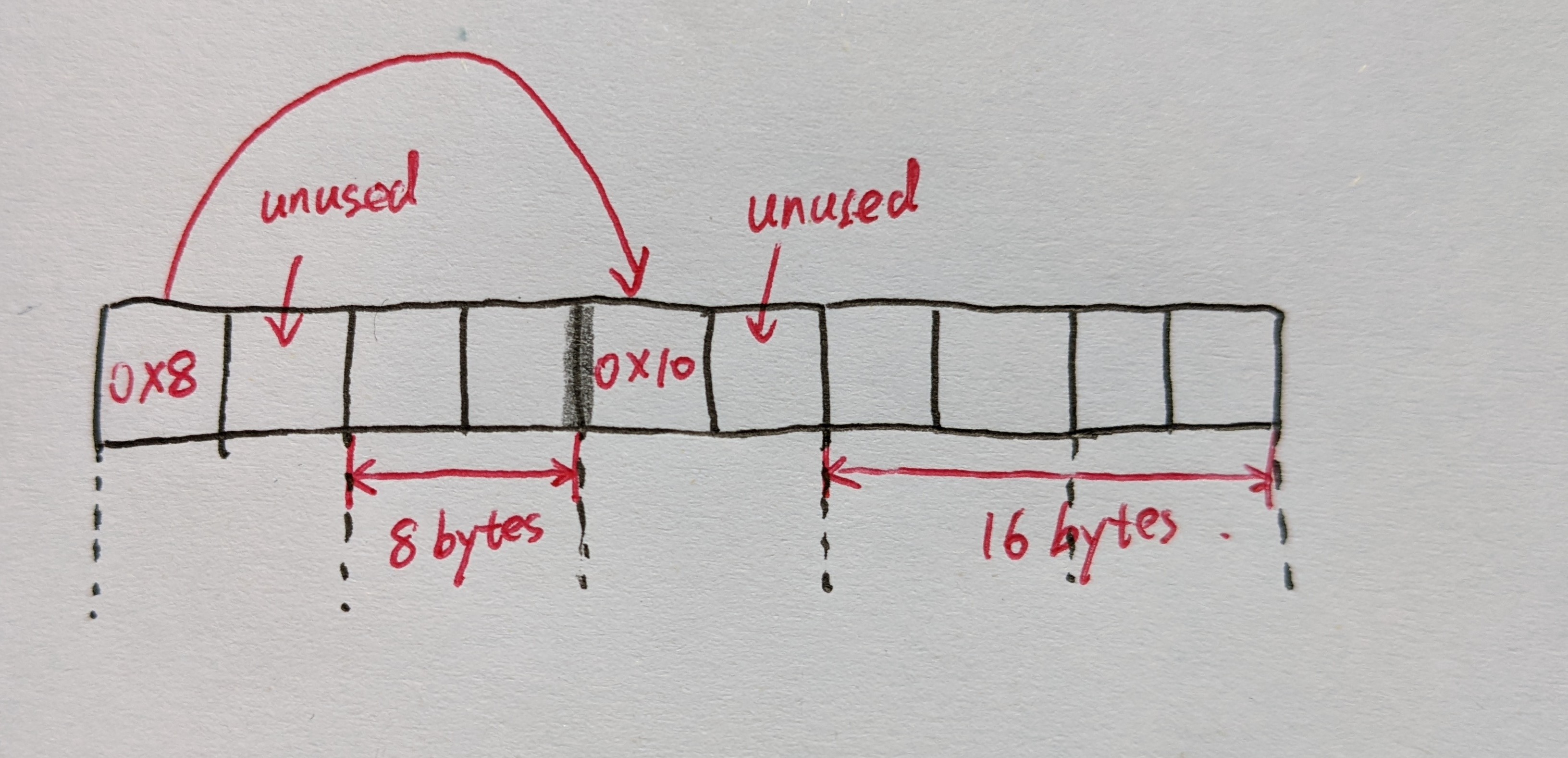
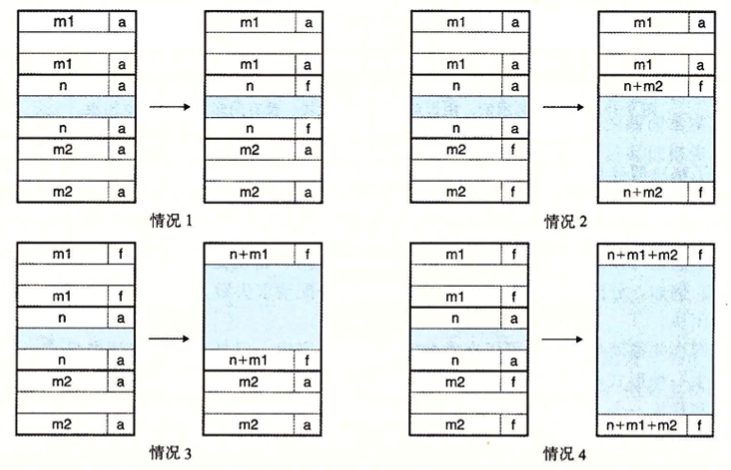
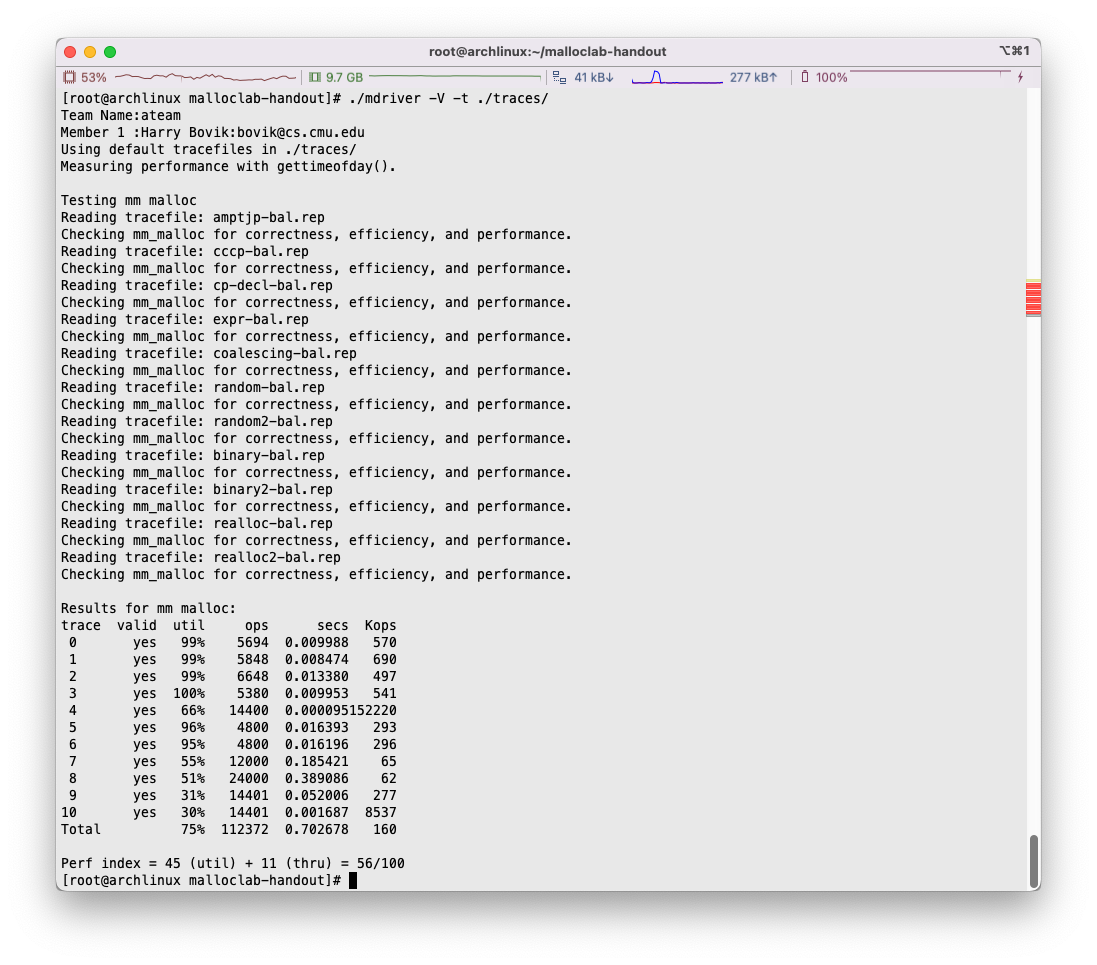
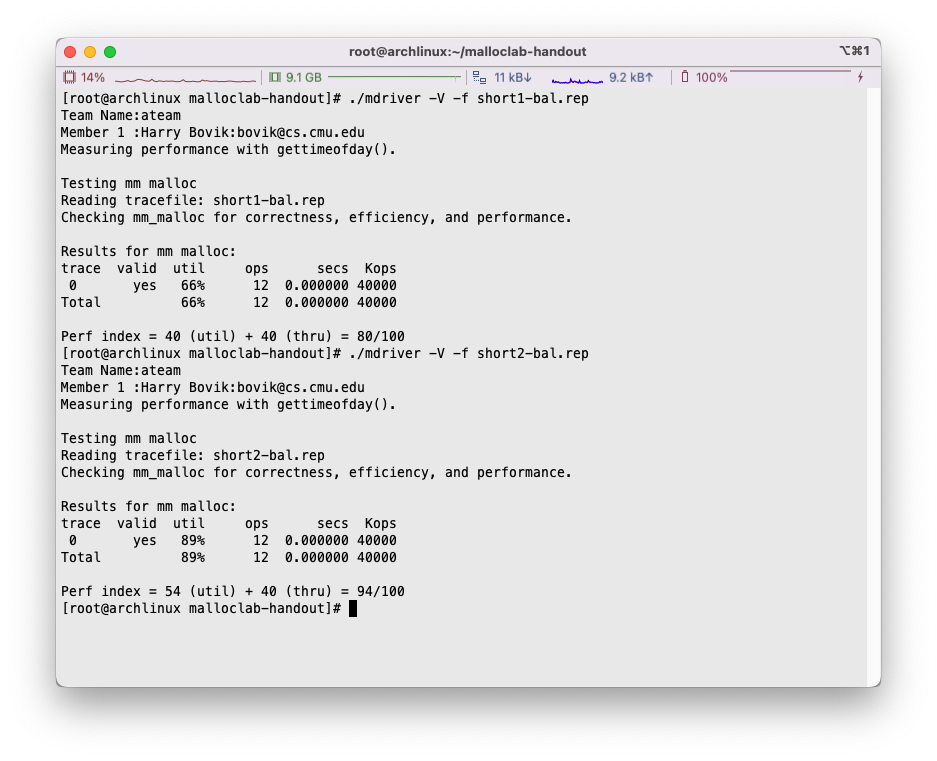
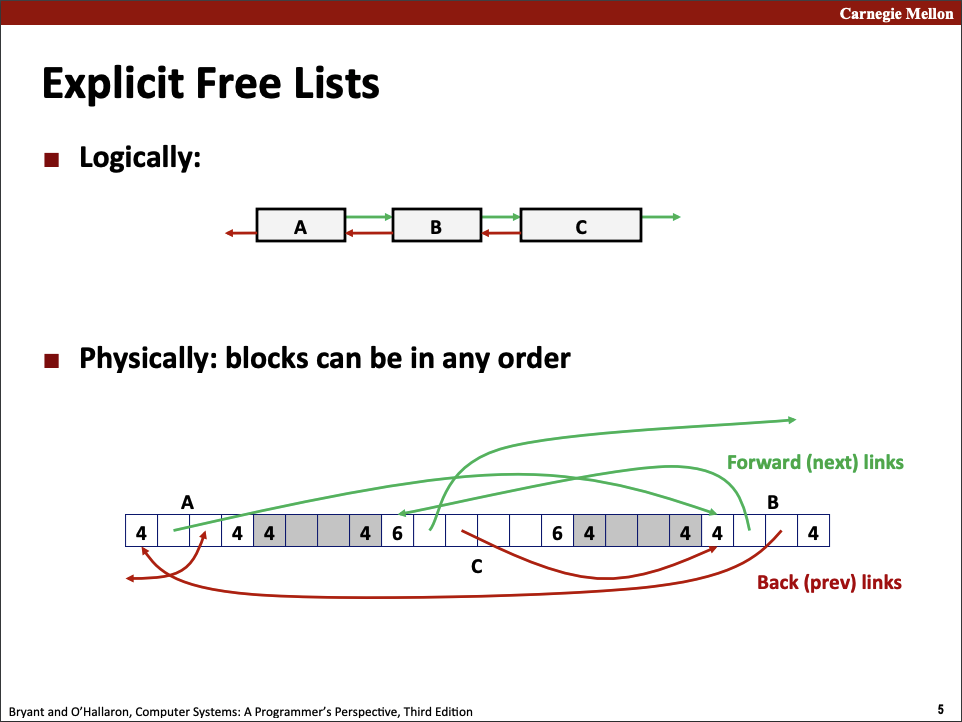
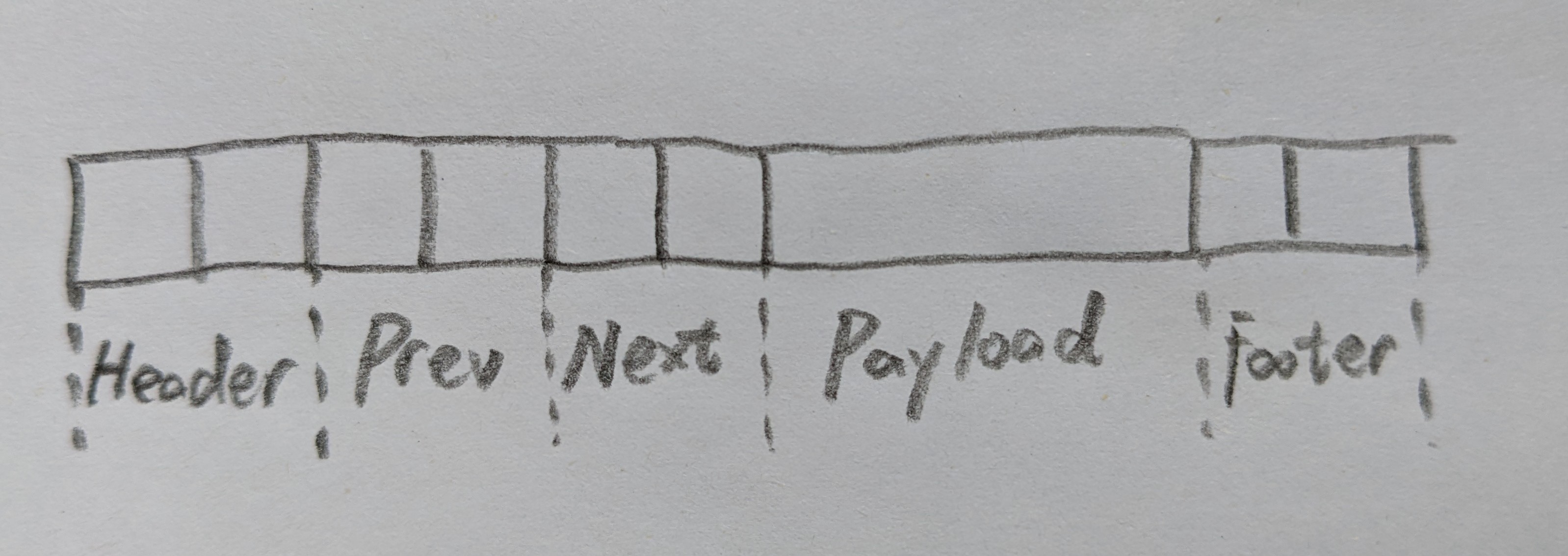
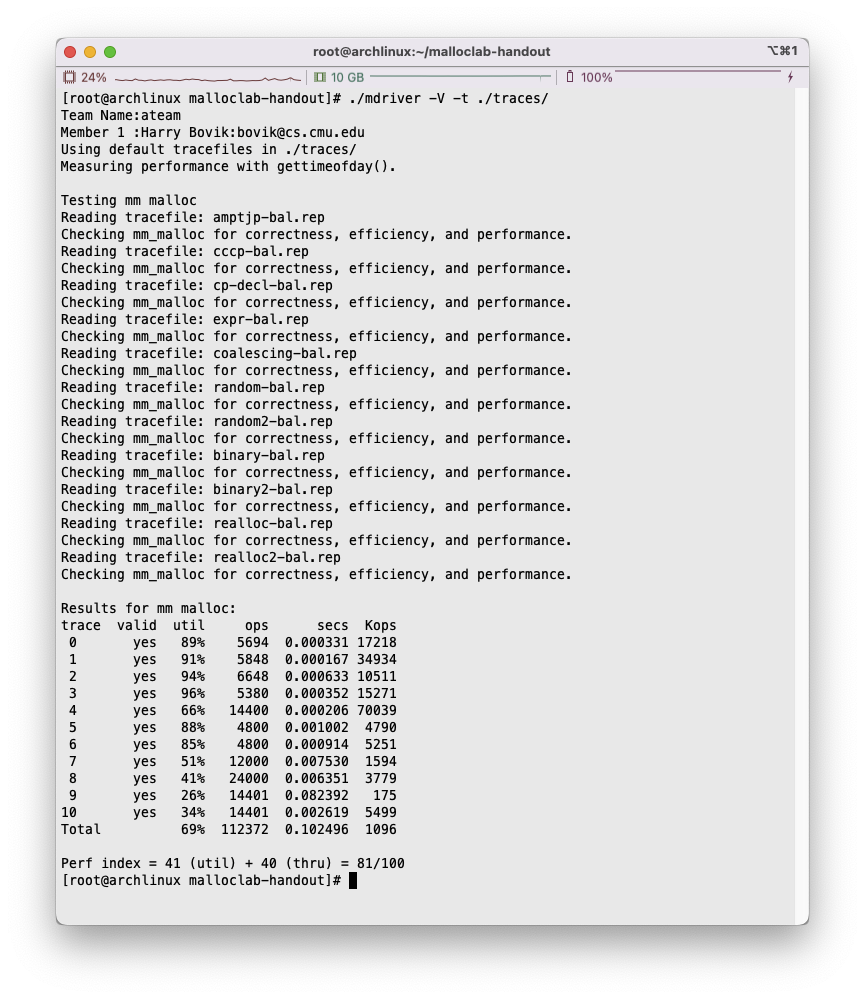
P. S. 在编译过程中,如果遇到/usr/include/gnu/stubs.h:7:11: fatal error: gnu/stubs-32.h: No such file or directory相关的问题,应该是32位兼容的问题… 目测前往Makefile中,将编译选项中的-m32修改为-m64即可,接下来执行make clean; make即可。
/********************************************************* * NOTE TO STUDENTS: Before you do anything else, please * provide your team information in the following struct. ********************************************************/ team_t team = { /* Team name */ "ateam", /* First member's full name */ "Harry Bovik", /* First member's email address */ "bovik@cs.cmu.edu", /* Second member's full name (leave blank if none) */ "", /* Second member's email address (leave blank if none) */ "" };
/* single word (4) or double word (8) alignment */ #define ALIGNMENT 8 /* rounds up to the nearest multiple of ALIGNMENT */ #define ALIGN(size) (((size) + (ALIGNMENT-1)) & ~0x7)
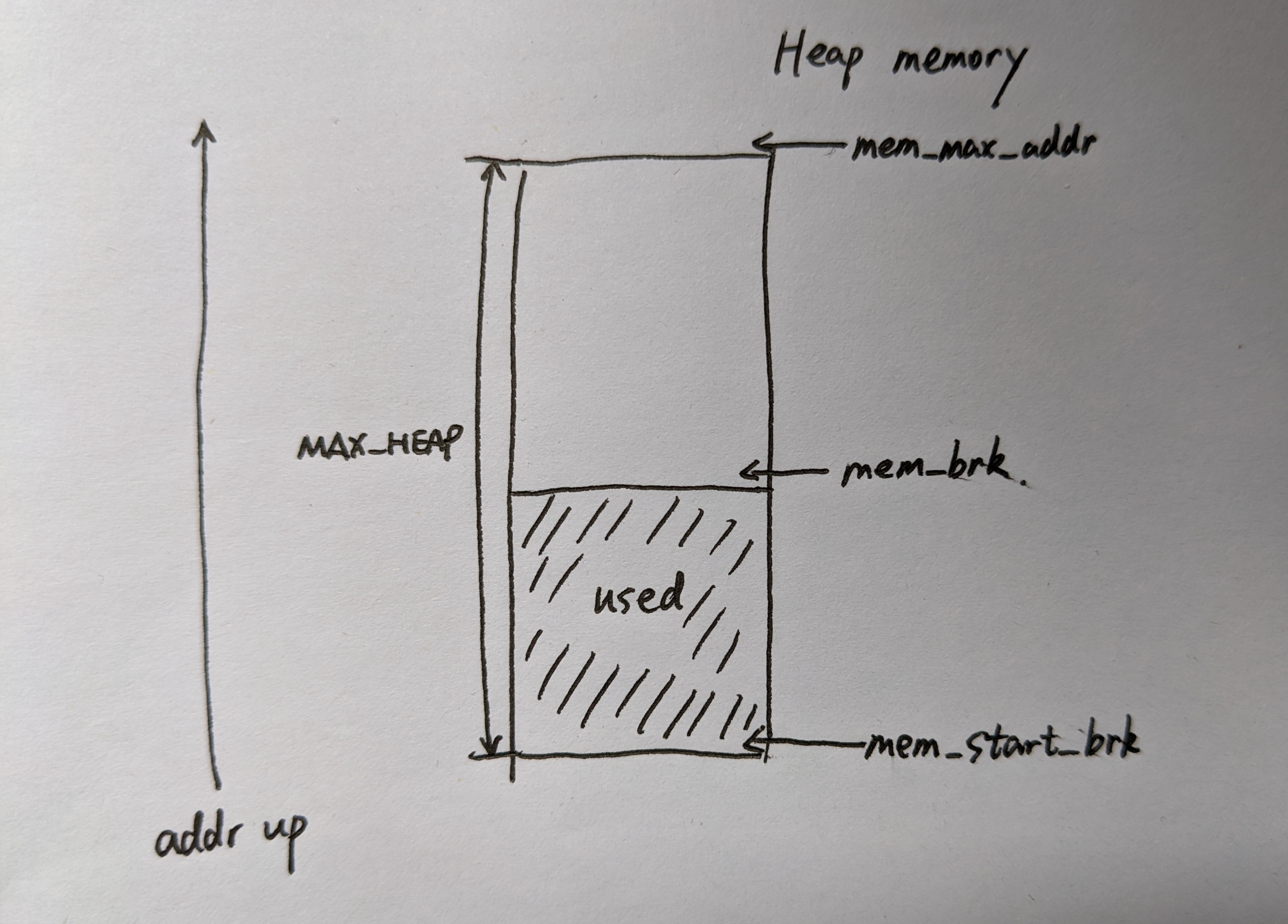
/* private variables */ staticchar *mem_start_brk; /* points to first byte of heap */ staticchar *mem_brk; /* points to last byte of heap */ staticchar *mem_max_addr; /* largest legal heap address */
/* * mem_init - initialize the memory system model */ voidmem_init(void) { /* allocate the storage we will use to model the available VM */ if ((mem_start_brk = (char *)malloc(MAX_HEAP)) == NULL) { fprintf(stderr, "mem_init_vm: malloc error\n"); exit(1); }
/* * mem_sbrk - simple model of the sbrk function. Extends the heap * by incr bytes and returns the start address of the new area. In * this model, the heap cannot be shrunk. */ void *mem_sbrk(int incr) { char *old_brk = mem_brk;
if ((incr < 0) || ((mem_brk + incr) > mem_max_addr)) { //如果预计修改后的堆内存超过上限或者想要收缩堆大小,则报错 errno = ENOMEM; fprintf(stderr, "ERROR: mem_sbrk failed. Ran out of memory...\n"); return (void *)-1; } mem_brk += incr; return (void *)old_brk; //否则返回原堆内存上界指针 }
/* Allocate an even number of words to maintain alignment */ size = (words % 2) ? (words + 1) * WSIZE : words * WSIZE; if ((long)(bp = mem_sbrk(size)) == -1) returnNULL;
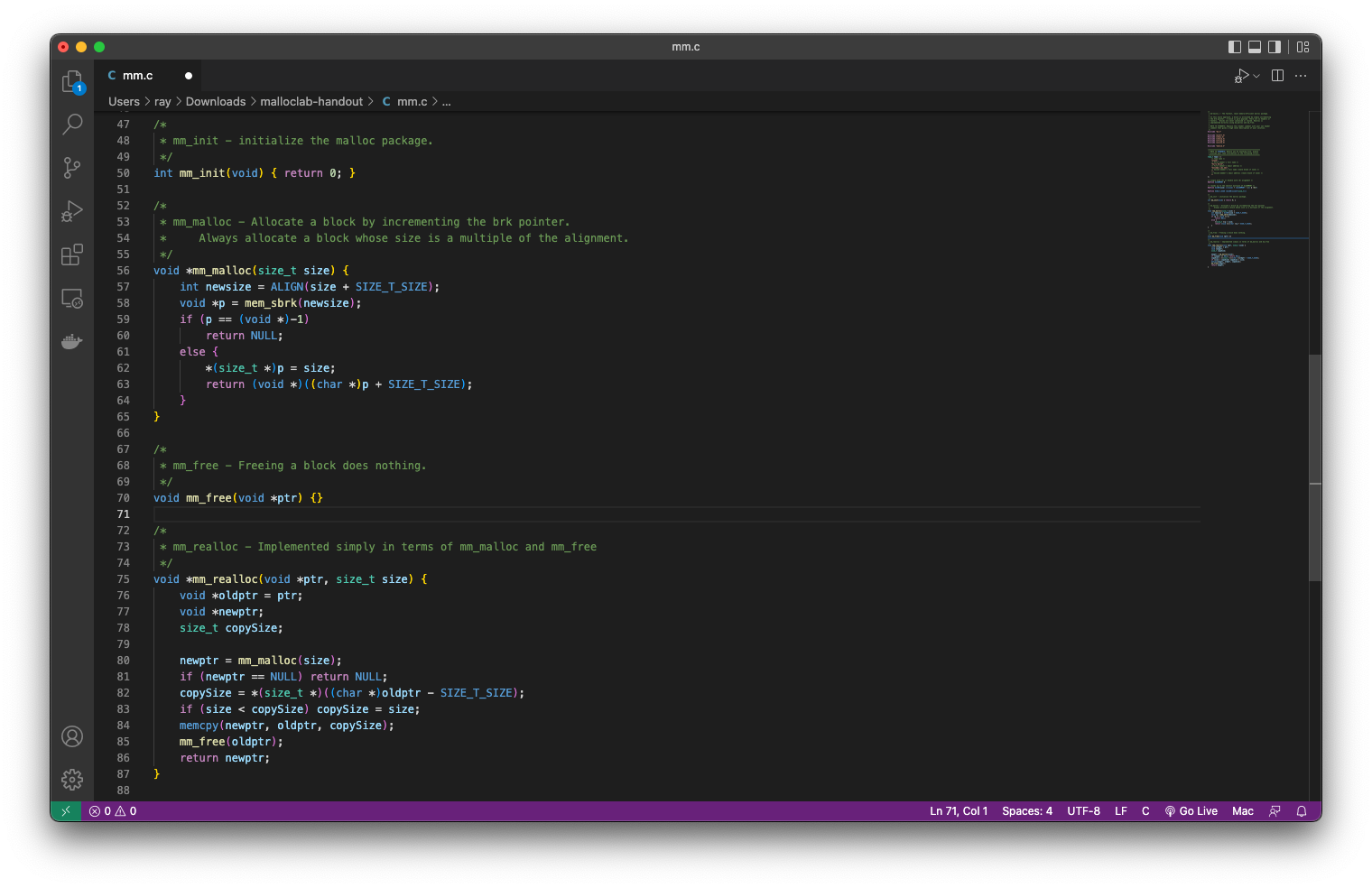
/* * mm_malloc - Allocate a block by incrementing the brk pointer. * Always allocate a block whose size is a multiple of the alignment. */ void *mm_malloc(size_t size) { size_t asize; /* Adjust block size */ size_t extendsize; /* Amount to extend heap if no fit */ char *ptr;
/* Search the free list for a fit */ if((ptr = find_fit(asize)) != NULL) { place(ptr, asize); return ptr; }
/* No fit found. Get more memory and place the block */ extendsize = MAX(asize, CHUNKSIZE); if((ptr = extend_heap(extendsize/WSIZE)) == NULL) { returnNULL; } place(ptr, asize); return ptr; }
/* * mm-implicit-free-list.c * The version from the book implemented with implicit free list... * No linked list involved, everything about ptr offset... */ #include"mm.h"
/********************************************************* * NOTE TO STUDENTS: Before you do anything else, please * provide your team information in the following struct. ********************************************************/ team_t team = { /* Team name */ "ateam", /* First member's full name */ "Harry Bovik", /* First member's email address */ "bovik@cs.cmu.edu", /* Second member's full name (leave blank if none) */ "", /* Second member's email address (leave blank if none) */ ""};
/* single word (4) or double word (8) alignment */ #define ALIGNMENT 8
/* rounds up to the nearest multiple of ALIGNMENT */ #define ALIGN(size) (((size) + (ALIGNMENT - 1)) & ~0x7)
#define SIZE_T_SIZE (ALIGN(sizeof(size_t)))
/* Basic constants and macros */ #define WSIZE 4 /* Word and header/footer size (bytes) */ #define DSIZE 8 /* Double word size (bytes) */ #define CHUNKSIZE (1 << 12) /* Extend heap by this amount (bytes) */
#define MAX(x, y) ((x) > (y) ? (x) : (y))
/* Pack a size and allocated bit into a word */ #define PACK(size, alloc) ((size) | (alloc))
/* Read and write a word at address p */ #define GET(p) (*(unsigned int *)(p)) #define PUT(p, val) (*(unsigned int *)(p) = (val))
/* Read the size and allocated fields from address p */ #define GET_SIZE(p) (GET(p) & ~0x7) #define GET_ALLOC(p) (GET(p) & 0x1)
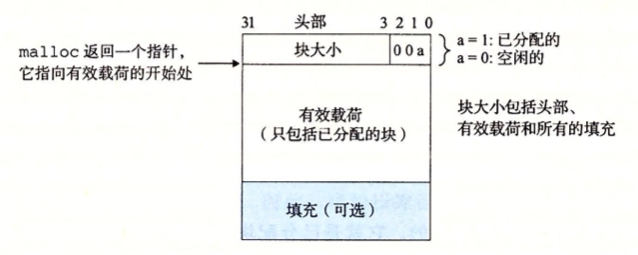
/* Given block ptr bp, compute address of its header and footer */ #define HDRP(bp) ((char *)(bp)-WSIZE) #define FTRP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp)) - DSIZE)
/* Given block ptr bp, compute address of next and previous blocks */ #define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(((char *)(bp)-WSIZE))) #define PREV_BLKP(bp) ((char *)(bp)-GET_SIZE(((char *)(bp)-DSIZE)))
/* Allocate an even number of words to maintain alignment */ size = (words % 2) ? (words + 1) * WSIZE : words * WSIZE; if ((long)(bp = mem_sbrk(size)) == -1) returnNULL;
/* * mm_malloc - Allocate a block by incrementing the brk pointer. * Always allocate a block whose size is a multiple of the alignment. */ void *mm_malloc(size_t size) { size_t asize; /* Adjust block size */ size_t extendsize; /* Amount to extend heap if no fit */ char *ptr;
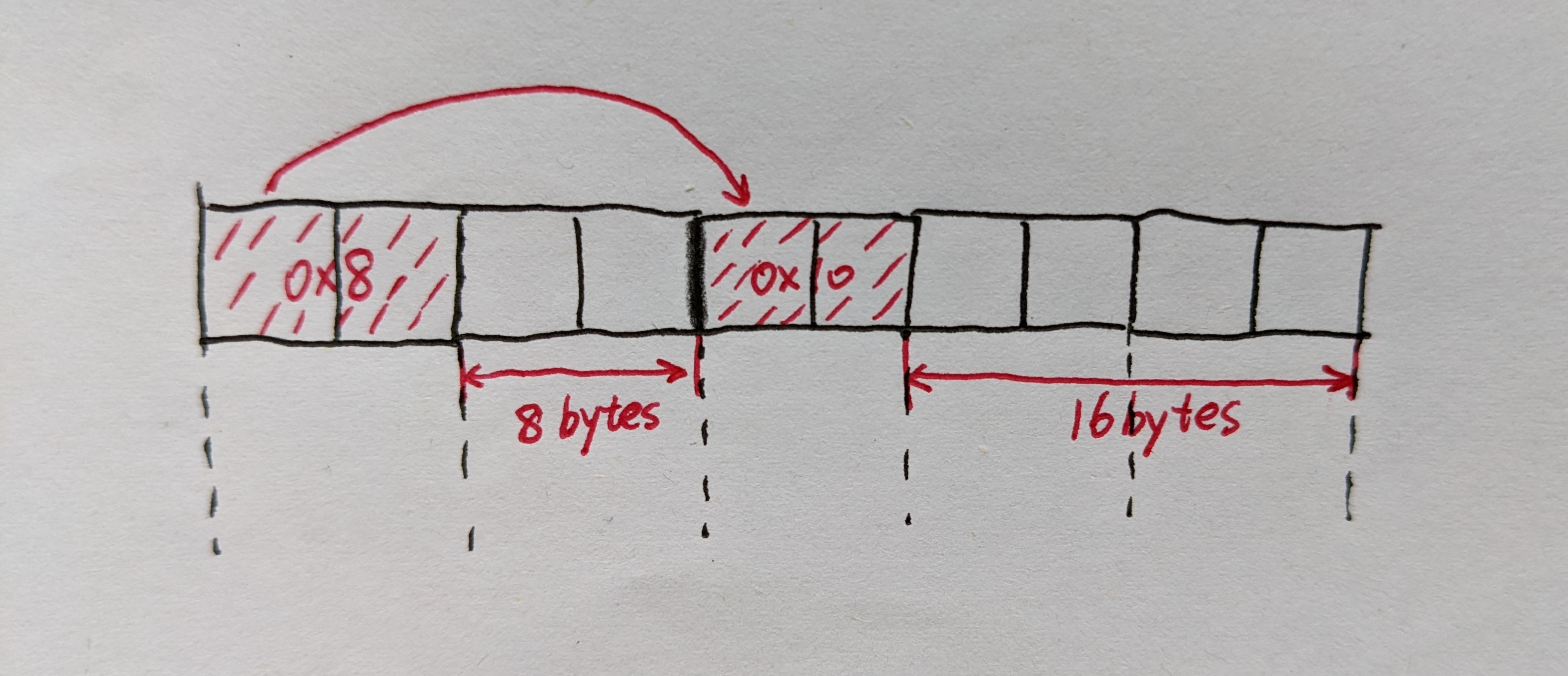
/* Adjust block size to include overhead and alignment reqs. */ if (size <= DSIZE) { asize = 2 * DSIZE; //至少16字节 } else { asize = DSIZE * ((size + (DSIZE) + (DSIZE - 1)) / DSIZE); //向上与8字节对齐 }
/* Search the free list for a fit */ if ((ptr = find_fit(asize)) != NULL) { place(ptr, asize); return ptr; }
/* No fit found. Get more memory and place the block */ extendsize = MAX(asize, CHUNKSIZE); if ((ptr = extend_heap(extendsize / WSIZE)) == NULL) { returnNULL; } place(ptr, asize); // mm_check(); return ptr; }
/* Given block ptr bp, compute address of next and previous blocks (adjacent mem address) */ #define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp))) #define PREV_BLKP(bp) ((char *)(bp)-GET_SIZE(((char *)(bp)-4 * DSIZE)))
/* Given block ptr bp, compute address of next and previous blocks (adjacent link list address) */ #define NEXT_LINKNODE_PTR(bp) ((char *)(GET(NEXT_PTR(bp)))) #define PREV_LINKNODE_PTR(bp) ((char *)(GET(PREV_PTR(bp))))
/* Allocate an even number of words to maintain alignment */ size = (words % 2) ? (words + 1) * WSIZE : words * WSIZE; //拓展内存大小双字对齐 if ((long)(bp = mem_sbrk(size)) == -1) returnNULL;
bp += (2 * DSIZE); /* Initialize free block header/footer and the epilogue header */ PUT(HDRP(bp), PACK(size, 0)); //设置新空闲块头部 PUT(FTRP(bp), PACK(size, 0)); //设置新空闲块脚部 PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1)); //设置新的结尾块
/* * mm_malloc - Allocate a block by incrementing the brk pointer. * Always allocate a block whose size is a multiple of the alignment. */ void *mm_malloc(size_t size) { size_t asize; /* Adjust block size */ size_t extendsize; /* Amount to extend heap if no fit */ char *ptr;
/* Adjust block size to include overhead and alignment reqs. */ if(size <= DSIZE){ asize = 5 * DSIZE; //至少40字节 } else { asize = DSIZE * ((size + (4 * DSIZE) + (DSIZE - 1)) / DSIZE); //向上与8字节对齐 } /* Search the free list for a fit */ if((ptr = find_fit(asize)) != NULL) { place(ptr, asize); return ptr; }
/* No fit found. Get more memory and place the block */ extendsize = MAX(asize, CHUNKSIZE); if((ptr = extend_heap(extendsize/WSIZE)) == NULL) { returnNULL; } place(ptr, asize); return ptr; }
/********************************************************* * NOTE TO STUDENTS: Before you do anything else, please * provide your team information in the following struct. ********************************************************/ team_t team = { /* Team name */ "ateam", /* First member's full name */ "Harry Bovik", /* First member's email address */ "bovik@cs.cmu.edu", /* Second member's full name (leave blank if none) */ "", /* Second member's email address (leave blank if none) */ ""};
/* single word (4) or double word (8) alignment */ #define ALIGNMENT 8
/* rounds up to the nearest multiple of ALIGNMENT */ #define ALIGN(size) (((size) + (ALIGNMENT - 1)) & ~0x7)
#define SIZE_T_SIZE (ALIGN(sizeof(size_t)))
/* Basic constants and macros */ #define WSIZE 4 /* Word and header/footer size (bytes) */ #define DSIZE 8 /* Double word size (bytes) */ #define CHUNKSIZE (1 << 12) /* Extend heap by this amount (bytes) */
#define MAX(x, y) ((x) > (y) ? (x) : (y))
/* Pack a size and allocated bit into a word */ #define PACK(size, alloc) ((size) | (alloc))
/* Read and write 1/2 word(s) at address p */ #define GET(p) (*(size_t *)(p)) #define PUT(p, val) (*(size_t *)(p) = (val))
/* Read the size and allocated fields from address p */ #define GET_SIZE(p) (GET(p) & ~0x7) #define GET_ALLOC(p) (GET(p) & 0x1)
/* Given block ptr bp, compute address of next and previous blocks (adjacent mem * address) */ #define NEXT_BLKP(bp) ((char *)(bp) + GET_SIZE(HDRP(bp))) #define PREV_BLKP(bp) ((char *)(bp)-GET_SIZE(((char *)(bp)-4 * DSIZE)))
/* Given block ptr bp, compute address of next and previous blocks (adjacent * link list address) */ #define NEXT_LINKNODE_PTR(bp) ((char *)(GET(NEXT_PTR(bp)))) #define PREV_LINKNODE_PTR(bp) ((char *)(GET(PREV_PTR(bp))))
/* Allocate an even number of words to maintain alignment */ size = (words % 2) ? (words + 1) * WSIZE : words * WSIZE; //拓展内存大小双字对齐 if ((long)(bp = mem_sbrk(size)) == -1) returnNULL;
bp += (2 * DSIZE); /* Initialize free block header/footer and the epilogue header */ PUT(HDRP(bp), PACK(size, 0)); //设置新空闲块头部 PUT(FTRP(bp), PACK(size, 0)); //设置新空闲块脚部 PUT(HDRP(NEXT_BLKP(bp)), PACK(0, 1)); //设置新的结尾块
/* * mm_malloc - Allocate a block by incrementing the brk pointer. * Always allocate a block whose size is a multiple of the alignment. */ void *mm_malloc(size_t size) { size_t asize; /* Adjust block size */ size_t extendsize; /* Amount to extend heap if no fit */ char *ptr;
/* Adjust block size to include overhead and alignment reqs. */ if(size <= DSIZE){ asize = 5 * DSIZE; //至少40字节 } else { asize = DSIZE * ((size + (4 * DSIZE) + (DSIZE - 1)) / DSIZE); //向上与8字节对齐 } /* Search the free list for a fit */ if((ptr = find_fit(asize)) != NULL) { place(ptr, asize); // mm_check(); return ptr; }
/* No fit found. Get more memory and place the block */ extendsize = MAX(asize, CHUNKSIZE); if((ptr = extend_heap(extendsize/WSIZE)) == NULL) { returnNULL; } place(ptr, asize); // mm_check(); return ptr; }