CS:APP Proxy Lab实验
本文是CS:APP学习笔记的一部分:
相关的代码都放在了GitHub下了:RayZhang13/CSAPP-Labs
关于学习资源和视频等问题可以参考第一次写的Data Lab开头中提及的相关问题。
只剩下最后一个Lab了,加把劲吧… 所有的事情都在正常推进,只能说未来可期…
这次的Lab要求我们写一个网页代理程序,作为浏览器和目标服务器之间的中间人。
为了简化难度,本次我们只实现一个简单的HTTP代理程序,我们循序渐进的添加功能,首先我们仅仅实现基本的请求转发和代理功能,接下来我们对程序进行修改,以应对并发的连接请求,在最后一个部分中,我们考虑加入响应的缓存功能。(情绪稳定,感觉可能会有点难…)
准备
对应课程
这次的Proxy Lab作业,如果是自学,在B站课程中请完成P21~26的学习,对应书中的第11章和第12章,理解网络编程和并发编程的相关概念。
P.S. 第10章系统级I/O在第11章网络编程中多多少少还是涉及了点,想回顾的可以去看看B站课程P16。
课程文件
相关的作业还是在CMU的官网上,相同位置:
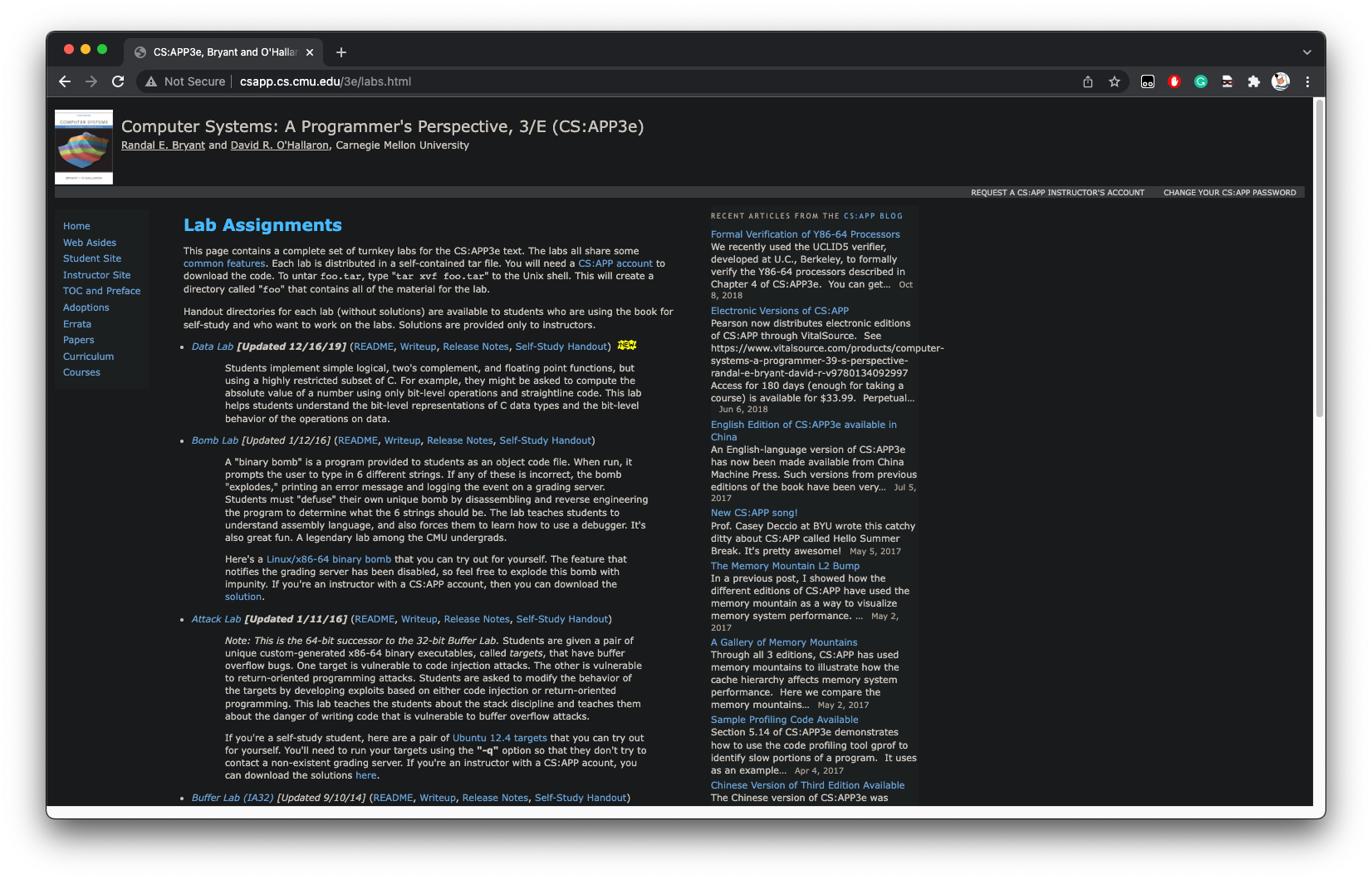
在Proxy Lab一栏中,我们可以查看相关文件,例如:
下载后并解压的文件如图所示:


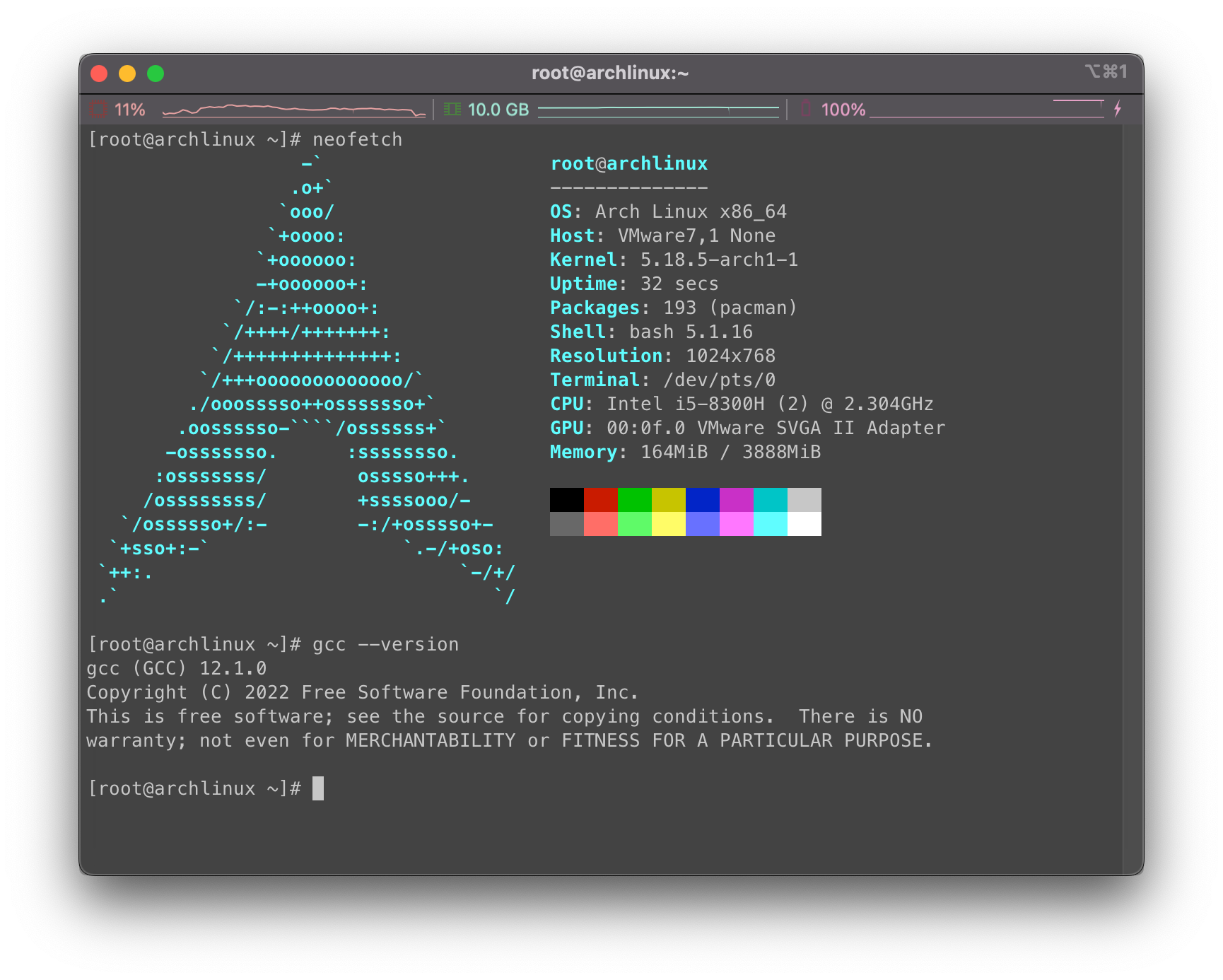
使用环境
如下为我的Linux版本和GCC版本:
使用建议
作业区域
作业需要的位置为proxy.c,我们相关方法的执行都在这里进行。
此外缓存功能所需实现的程序可以额外放置在例如cache.c和cache.h中,如果需要添加新文件记得加入到Makefile中。
文件说明
-
proxy.c为我们需要完成的主程序文件。 -
csapp.h和csapp.c提供了教材中的相关封装程序,避免了我们进一步造轮子,比如在网络编程这一章经常提到的open_clientfd和open_listenfd。此外还提供了大量的错误包装函数,这点我们在之前的Shell Lab中已经见识过了。 -
port-for-user.pl可以为指定用户生成随机的端口号,使用方法为/port-for-user.pl <userID>。emmm,看起来是个固定的映射,输入一个指定的用户名就能返回一个确定的端口(没啥用,可以自己随便选个比较大的,基本都能用)
-
free-port.sh可以提供一个未被使用的TCP端口供我们使用,使用方法为./free-port.sh
-
driver.sh用于对完成的程序从三个角度进行检测,分别是基本功能,并发能力和缓存功能。 -
此外,还附赠了一个
tiny文件夹,可以作为Tiny Web服务器以供测试。
题目
基本功能实现
要求
在第一阶段中,我们只需要实现简单的顺序执行的代理程序,主要处理HTTP/1.0 GET,其他的请求类型例如POST不做要求。
P.S. 即使请求为
HTTP/1.1也视为HTTP/1.0进行转发处理,PDF中要求
当程序开始时,代理程序通过我们在终端中给定的端口号进行监听。当我们从客户端接收到请求,我们首先需要确定客户端发送的HTTP请求是否合法。如果是,我们就在代理程序中自己建立新的连接到指定的目标服务器,发送响应的请求,最后我们将从目标服务器获得响应转发给客户端。
此外有如下几点需要我们注意:
- 不应使用标准I/O函数进行网络编程,相关原因详见书10.11。应当使用在
csapp.c中的RIO包。 csapp.c中的包装处理函数可能有不合理之处,因为当服务器开始接受连接就不应当被终止,需要进行修改或者重写。- 根据TCP协议的规定,会收到一个RST响应,client再往这个服务器发送数据时,系统会发出一个SIGPIPE信号给进程,告诉进程这个连接已经断开了,不要再写了。代理程序应当对
SIGPIPE信号进行忽略处理。此外小心处理write操作返回的EPIPE错误。 - 有时调用
read从一个过早关闭的套接字中进行读取会返回-1,并将errno置为ECONNRESET,我们选择忽略相关错误防止代理程序被终止。 - 网络上的内容并非都是ASCII文本,网络上的许多内容是二进制数据,如图像和视频。确保在选择和使用网络I/O的功能时考虑到二进制数据。
在请求头方面,由于我们实现的是一个代理服务,我们需要使用Proxy-Connection请求头,其相关原因和作用相见Http 请求头中的 Proxy-Connection。(这篇文章讲的很清楚了,也解决了我很多困惑)
在程序实现中,本次的Proxy Lab中,重要的请求头有Host, User-Agent, Connection和Proxy-Connection。此外针对请求行也有少许的变化,我们分开来看不同的请求头和请求行的特性和要求:
-
在请求行中,由于我们使用了代理,客户端发起的请求头中Request URL 变成了完整路径。例如:
1
GET http://www.cmu.edu/hub/index.html HTTP/1.1
为了处理这样的URL,我们需要对字符串进行分割,确定主机名称
www.cmu.edu和请求路径/hub/index.html。并针对目标主机发起新的连接:1
GET /hub/index.html HTTP/1.0
而
Host请求头始终应当使用目标服务器的主机名称:1
Host: www.cmu.edu
-
User-Agent请求头,即UA标志符,用于表示客户端的相关信息。在HTTP中,User-Agent字符串通常被用于内容协商,而原始服务器为该响应选择适当的内容或操作参数。在此实验中,我们默认设置如下的
UA请求头,相关信息已经被预置在proxy.c文件中了:1
static const char *user_agent_hdr = "User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:10.0.3) Gecko/20120305 Firefox/10.0.3\r\n";
-
在实验中,我们将
Connection和Proxy-Connection都设置为close,以表示相关连接都是短连接,不必保活:1
2Connection: close
Proxy-Connection: close -
如果客户端还存在其他请求头,我们就原封不动的保留并发送给目标服务器。
主程序
一个典型的网络连接过程如图所示:
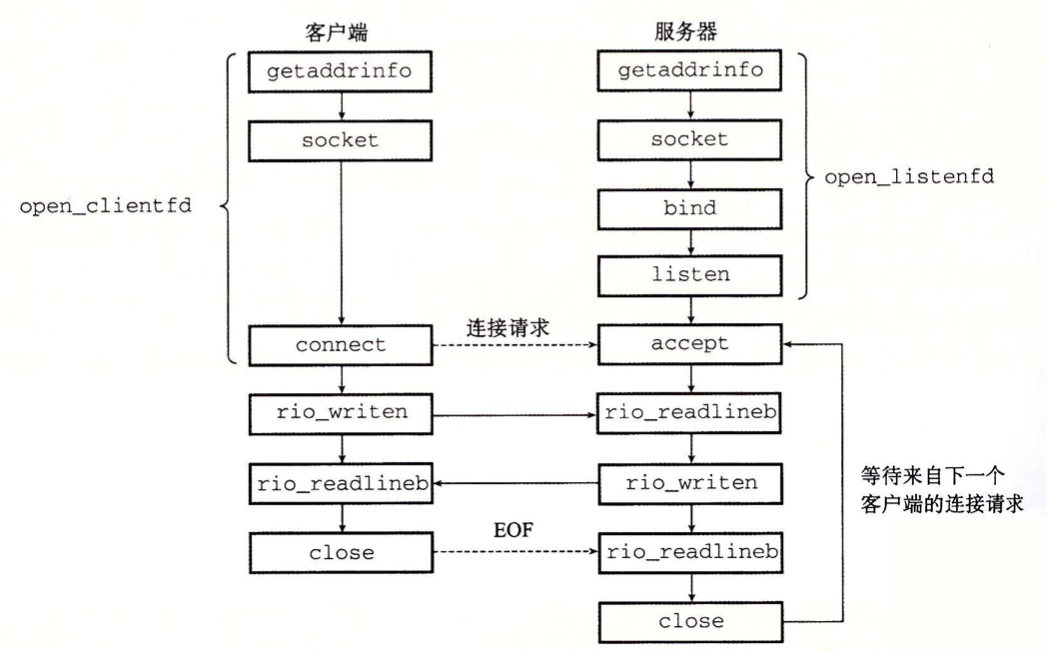
在服务器代码中,我们将前段过程使用Open_listenfd对命令行指定端口进行监听,并返回监听文件描述符。接下来,我们使用Accept接受来自客户端的请求,并生成对应的连接文件描述符,同时打印出连接的客户端的主机名和端口相关参数。然后,我们在todo函数中进行我们的核心功能处理,大概就是分析来自客户端的请求内容,并向目标主机发起连接等(在后面慢慢讲)。最后处理完这个连接,我们关闭连接文件描述符。并在循环中不断重复这个过程。
在这里,我们可以简单的借鉴一下Tiny Web服务器中的相关代码。
1 | int main(int argc, char **argv) { |
注意到PDF中要求我们对SIGPIPE信号进行忽略处理,因此信号处理程序程序写作如下:
1 | void sigpipe_handler(int sig) { |
doit函数
在doit函数中,我们抽象出来就做以下几件事情:
-
根据获取到的文件描述符,接受从客户端(浏览器)的请求。调用
read_request读取请求,处理请求行和请求头,请存储下来。 -
在
send_request中,根据客户端的代理请求,对请求内容稍加修改,例如请求行中的URI,Connection请求,Proxy-Connection请求头和User-Agent请求头等,随后代理程序对目标主机发起新的请求,携带修改后的请求数据。 -
在
forward_response中,程序将目标主机响应的数据转发给客户端,即从目标主机连接中读取数据写入和客户端的连接中。
代码如下:
1 | void doit(int fd) { |
read_request读取客户端请求
我们知道客户端的一次代理请求中,包含一个请求行,形如:
1 | GET http://www.cmu.edu/hub/index.html HTTP/1.1 |
简单来说分为三部分,分别是请求方法、请求URI和HTTP版本。而更加具体的,请求URI又可以分为三部分,分别是访问主机名Host、请求路径Path以及请求端口号Port。特别的,不做额外说明的情况下,我们默认使用80端口。
1 | Host ==> www.cmu.edu |
我们注意到在向真正目标服务器发送信息时,我们根据整理出的信息就能快速生成请求内容:
1 | GET /hub/index.html HTTP/1.0 |
此外,请求还包含请求头,请求头可以视为简单的键值对,读入的字符串按照冒号进行分割即可。一个请求头最终会被分为两部分,分别是请求头名称和请求头内容。而在一个请求中,会包含多个请求头,为了到时方便遍历,我们额外使用一个变量,对请求头的数量进行计数。
最终,我们约定如下的数据结构用于表示一个客户端请求,并包含相关宏定义:
1 |
|
首先我们抽象地从顶层看待读取请求这一问题,不难知道,我们首先要读取请求行内容,随后是若干个请求头内容,并尝试将读出的内容存储在我们的结构体中,大致逻辑如下:
1 | void read_request(int fd, Request *request) { |
首先我们考虑读取请求行read_request_line的操作,我们首先根据空格将其分割为三份,分别是请求方法method、请求URI和HTTP版本。其中,请求方法method和HTTP版本可以立即写入请求行结构体中,而请求URI还需后续处理将其分为三部分,我们将在parse_uri中进行解决。
1 | void read_request_line(rio_t *rp, char *buf, Request_Line *request_line) { |
而在parse_uri中,我们需要处理一下几种缺省情形:
URI中略去了/,例如形如http://google.com:80URI中略去了端口号,例如形如http://google.com/maps- 组合拳,即略去了
/又略去了端口号,例如http://google.com
代码比较简单,就不再赘述了:
1 | void parse_uri(char *uri, char *host, char *port, char *path) { |
接下来,我们考虑使用read_request_header读取单行请求头,相关操作也较为简便,只需将字符串根据冒号分开即可,最后将读出的数据存入结构体:
1 | void read_request_header(rio_t *rp, char *buf, Request_Header *request_header) { |
send_request发送请求
根据刚才读取并存储在结构体中的数据,我们小幅修改请求,并从代理服务器向目标服务器发起连接。
根据PDF中的题目要求,我们需要始终将Connection和Proxy-Connection都设置为close,以表示相关连接都是短连接,不必保活,此外使用给定的User-Agent等。除开特殊设置,其余的请求头一律直接转发出去不经修改:
1 | int send_request(Request *request) { |
forward_response转发服务器响应
现在我们的代理服务器共有两个连接,分别是和客户端的连接和目标服务器的连接。向目标服务器发送完请求后,我们需要读取目标主机的响应,并将其原封不动的转发给客户端,以达到代理的目的。
我们使用forward_response达到此效果:
1 | void forward_response(int connfd, int targetfd) { |
csapp.c修改
就像在PDF中提示的一样,我们需要考虑到部分RIO包函数需要修改,典型的有:
- 处理
write操作返回的EPIPE错误。 - 有时调用
read从一个过早关闭的套接字中进行读取会返回-1,并将errno置为ECONNRESET,我们选择忽略相关错误防止代理程序被终止。
因此我们需要将Rio_writen进行重写,当遇到EPIPE错误时予以警告,但是继续执行:
1 | void Rio_writen(int fd, void *usrbuf, size_t n) { |
同理我们需要在Rio_readn、Rio_readnb和Rio_readlineb中添加相关的逻辑代码来规避ECONNRESET带来的异常退出:
1 | ssize_t Rio_readn(int fd, void *ptr, size_t nbytes) { |
测试
实现基本功能的代码如下:
1 |
|
我们在虚拟机上测试程序效果,其局域网IP为192.168.31.132。
首先在目录下使用make完成编译工作,接下来我们指定一个随机端口,例如为65534进行工作,即./proxy 65534。
接下来我们进入到tiny目录下,也就是附带的Tiny Web项目,使用make进行编译,我们也将其运行起来,例如指定端口65535,也就是./tiny 65535。
接下来,我们使用curl命令尝试访问几个网页,我们尝试我们自己的博客主页http://blog.rayzhang.top、Tiny Web的静态网页和动态内容:
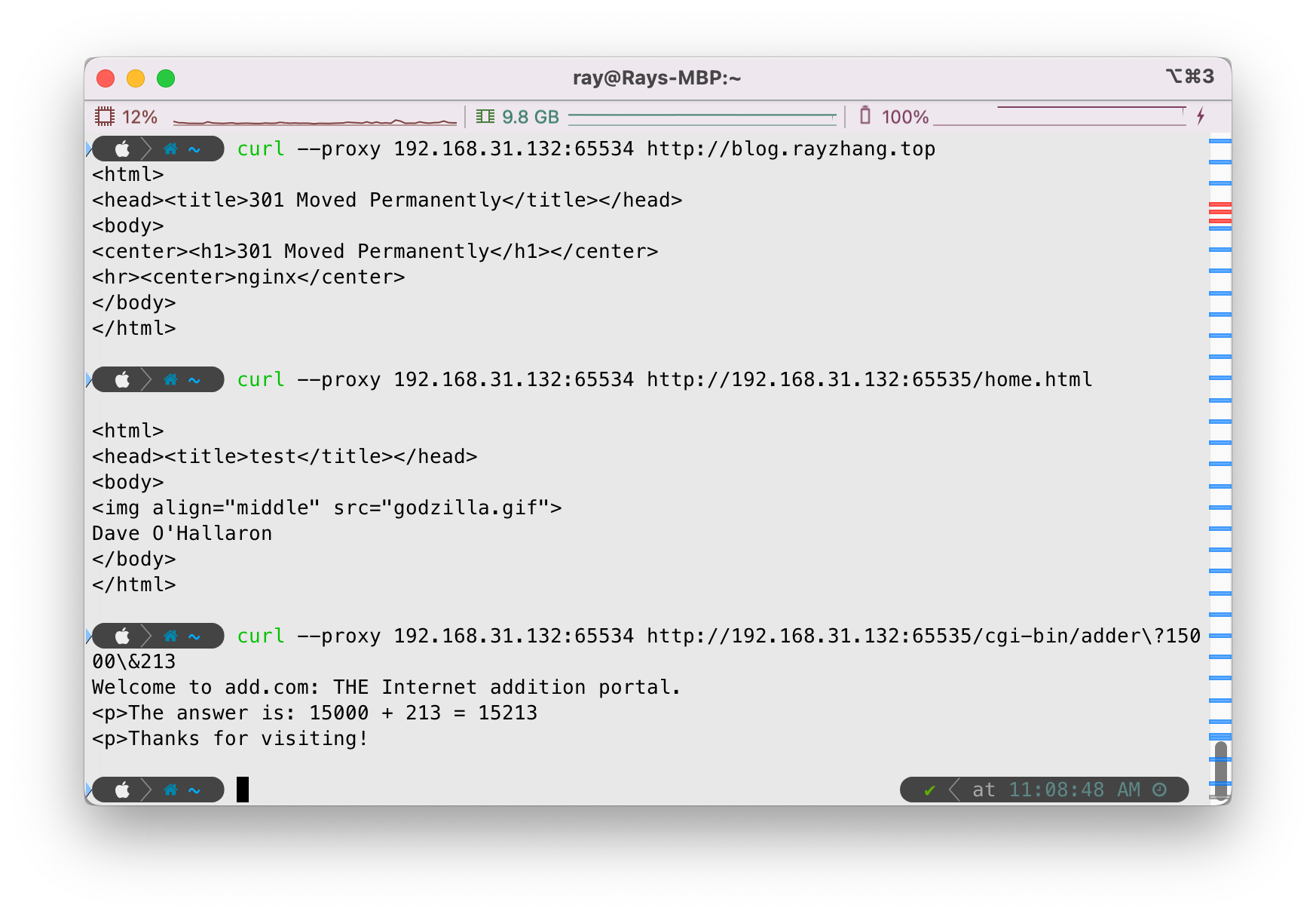
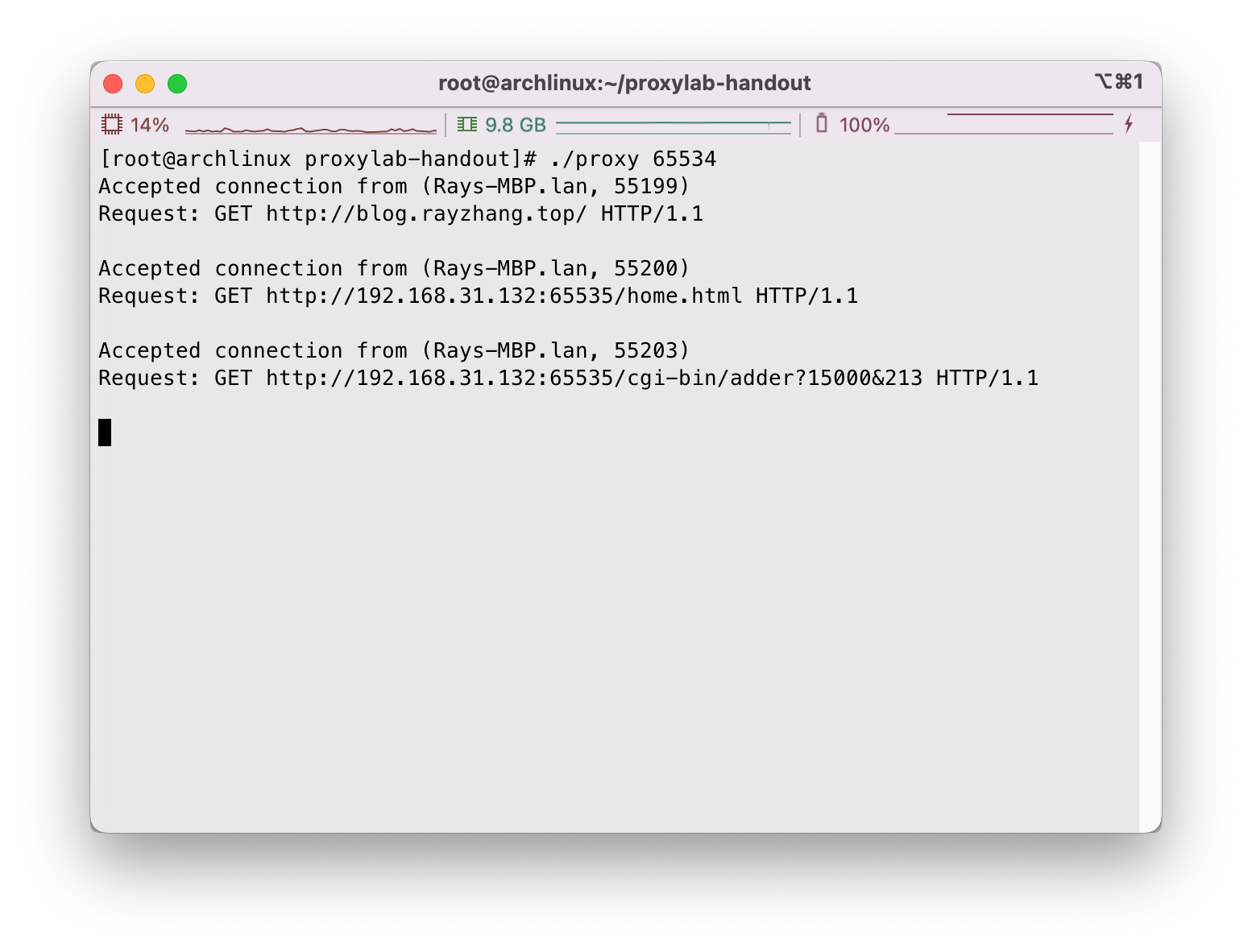
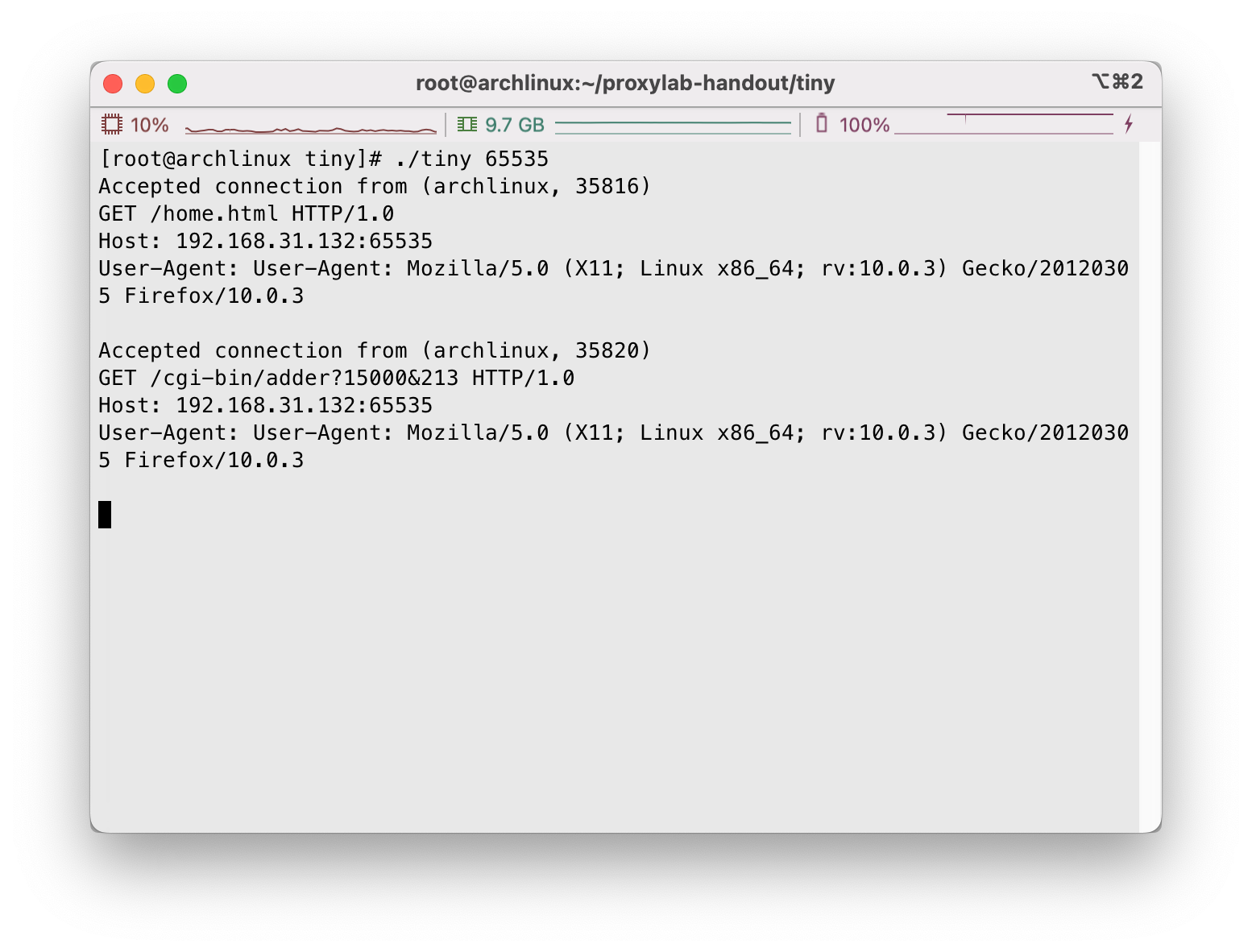
可以看到响应良好,目测没啥问题,我们调用./driver.sh测试:
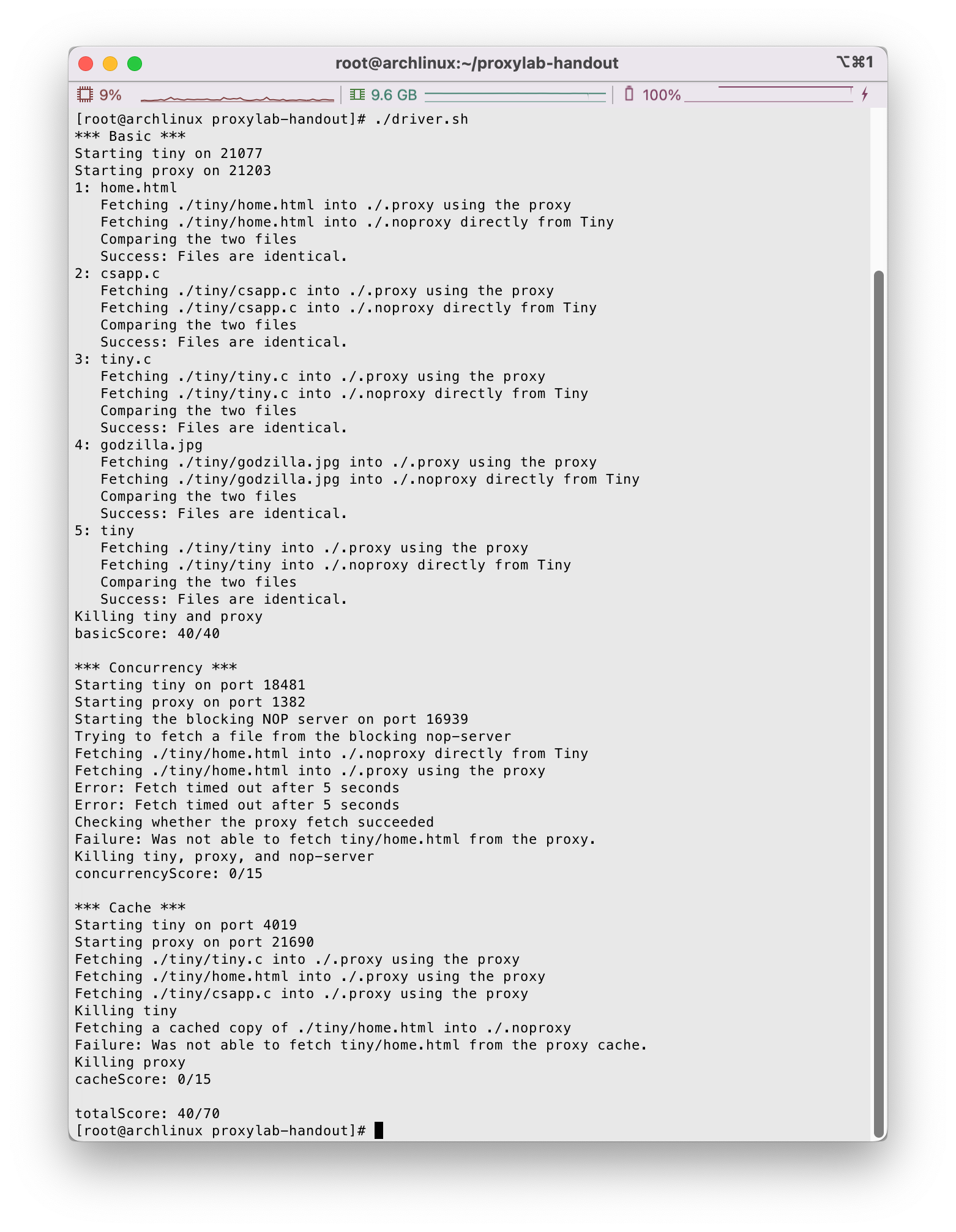
基本功能的40分已经实现了,算是告一段落了~
并发功能实现
要求
目前我们已经实现了一个代理服务器,可惜他是顺序执行的,基本功能倒是达到了。接下来我们要将其变为一个可以并发执行多个请求的程序。最简单的方法是每次产生一个新的线程来处理新的连接请求,当然我们也可以采用教材12.5.5中描述的基于预线程化的并发服务器(讲道理我是很想试试看写这个):
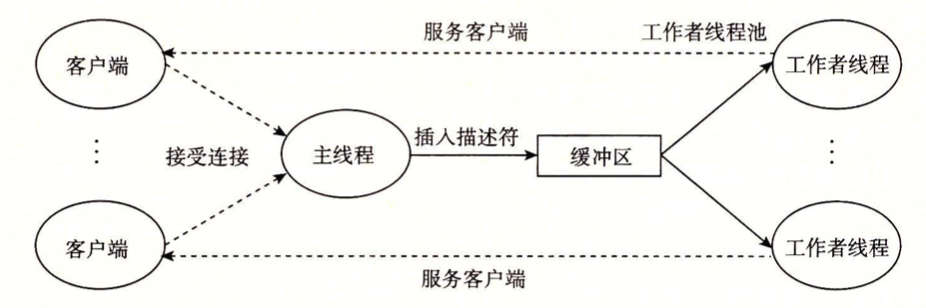
需要注意的问题有:
- 我们创建的线程应当使用分离模式detached mode,防止资源未被回收导致的内存泄漏。
csapp.c中使用的open_clientfd和open_listenfd均使用了更新的getaddrinfo方法,因此均为线程安全的,不必担心。
接下来的部分,我们只考虑需要修改和重写的程序片段,像是之前已经实现的请求读取发送等过程就不再赘述了。
我们考虑使用预线程化的策略,使用主线程接受请求,将描述符加入到缓冲区,作为生产者;使用工作者线程进行消费,从缓冲区中取出文件描述符,进行连接相关操作。
缓冲区sbuf_t
首先,我们构造出有限缓冲区sbuf_t的数据结构,用于存储文件描述符,参考书本。
可以看到buf是个循环数组,front和rear描述了循环数组的边界,mutex用于保护数组buf不被修改,slots用于表示空余位置数量,items用于表示已经使用的位置数量:
1 | typedef struct { |
对缓冲区的初始化、清理、添加和删除操作如下:
1 | /* Create an empty, bounded, shared FIFO buffer with n slots */ |
主函数
我们对主函数进行简单改造,在主线程中我们首先需要初始化缓冲区,创建若干个工作线程,随后开始循环接受客户端连接,将每次生成的连接文件描述符插入到缓冲区sbuf中。
注意到由于插入操作位于主线程中,因此是顺序执行的,不存在竞争的情况,不会有connfd被下一轮循环覆盖的可能。
1 |
|
工作线程thread
在工作线程中,我们首先将线程进行分离,以避免内存泄漏情况发生。接下来,不断循环尝试从缓冲区sbuf中取出连接文件描述符,取到后则进行后续的doit操作,即读取连接,分析连接,转发请求和转发响应,这部分代码功能没有问题,上文已经描述,不再赘述。最后,我们将和客户端的连接关闭。
1 | void *thread(void *vargp) { |
测试
最终代码如下:
1 |
|
在文件夹内使用make进行编译,随后调用./driver.sh进行测试:
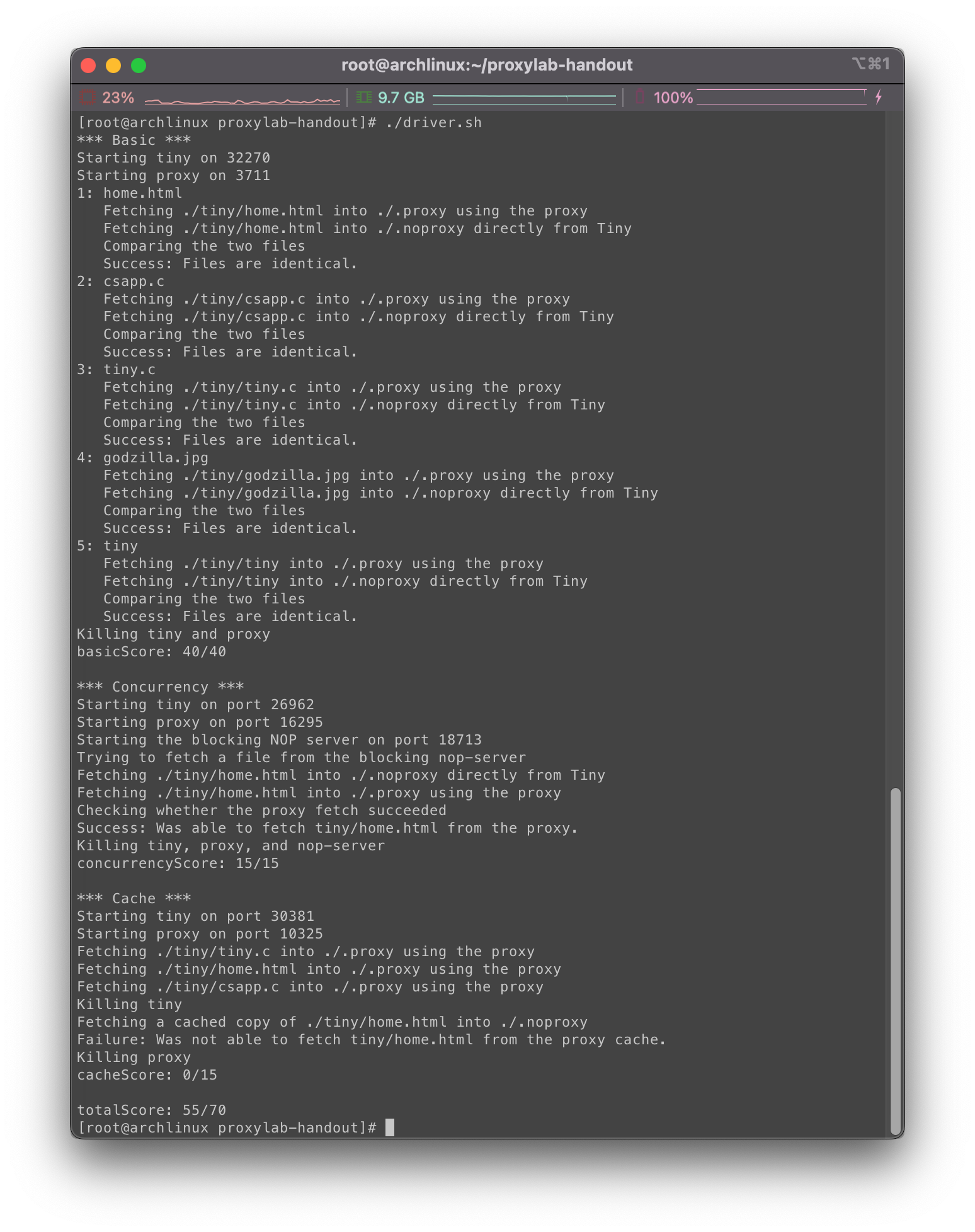
可以看到并发编程的15分我们也拿到了,现在分数来到了55分~
缓存功能实现
要求
在本部分中,我们要实现缓存的功能,当我们获得响应时,在将相应内容转发给客户端的同时,我们考虑对内容进行缓存。在文档中,要求我们使用LRU原则对内容进行缓存,每次淘汰最久未被使用的缓存。
在案例中,我们对缓存的大小进行控制,约束所有缓存的大小应当限制在MAX_CACHE_SIZE = 1 MiB,约束每次存储的缓存对象限制在MAX_OBJECT_SIZE = 100 KiB。
P.S.
缓存我们默认面临的是一种高频读,低频写的情形,因此可以考虑使用读写锁,但是这也带来了相应的问题。
当我们对缓存进行读的时候,假设缓存做到了命中,我们或多或少需要对缓存的数据结构进行修改,这就带来了写操作。如果我们的缓存使用的是链表数据结构,那么需要修改节点的前后节点指针,如果是数组结构,那么需要修改时间戳,这与读写锁的原则是矛盾的。
因此题目放宽了要求,不一定使用严格的LRU淘汰原则。
缓存Cache
就累了,想偷点懒,又不知道LRU不严格应该咋执行,我干脆就直接没考虑读写锁…
缓存是由多个缓存对形成的,每个缓存对内部都有有效标志位,请求request,响应内容reponse和上次修改的时间戳time_stamp。缓存内部需要使用一个mutex用来确保每次只有一个线程能对齐进行读写,同时我们还记录了一个缓存内部的缓存对数量。最终缓存的数据结构如下:
1 | /* Recommended max cache and object sizes */ |
同理,我们对缓存需要进行相关操作,例如初始化cache_init,搜索缓存查找命中cache_find和插入新的缓存对操作cache_insert。
初始化的代码很简单,不做过多描述。在查找操作中,我们需要遍历缓存中的缓存对,查找是否有命中,如果有我们直接将缓存中内容写入到和客户端的连接中。在插入操作中,同理,我们先遍历缓存,如果有未被使用的空闲缓存对空间,我们就直接写进去,同时根据时间戳查找最久未使用的缓存对,当我们遍历结束发现没有空位就直接对最久未使用的缓存对直接操作。
1 | int cur_time_stamp = 0; /* Init time stamp */ |
主程序
主程序和之前的程序变化不大,只是我们现在需要在中间插入一个初始化缓存的过程:
1 | sbuf_t sbuf; /* Shared buffer of connected descriptors */ |
doit函数
我们需要对doit函数进行简单的修改,在代理程序转发请求前,我们先考虑对缓存进行搜索,如果找到了cache_find函数会自动将缓存取出写回到客户端的连接中;如果没有找到,那么就进行正常的请求转发。
此外接收到目标请求后的响应后,除了直接将其写到客户端连接中,我们还需要将其插入到缓存中,因此forward_response也有微调,稍后会提及。
1 | void doit(int fd) { |
forward_response转发服务器响应
代理程序在接收到目标主机的响应后,一方面需要转发写到客户端连接中,另外添加了一个新的功能,需要插入到缓存中,更新缓存。
我们使用一个长度为MAX_OBJECT的字符串数组来进行存储,每次新读到的内容都接到字符串的末尾,同时我们监控读出的字节总数量,超过了我们的上限MAX_OBJECT_SIZE就不执行插入缓存操作了。
1 | void forward_response(int connfd, int targetfd, Request *request) { |
测试
最终的代码为:
1 |
|
在文件夹内使用make进行编译,随后调用./driver.sh进行测试:
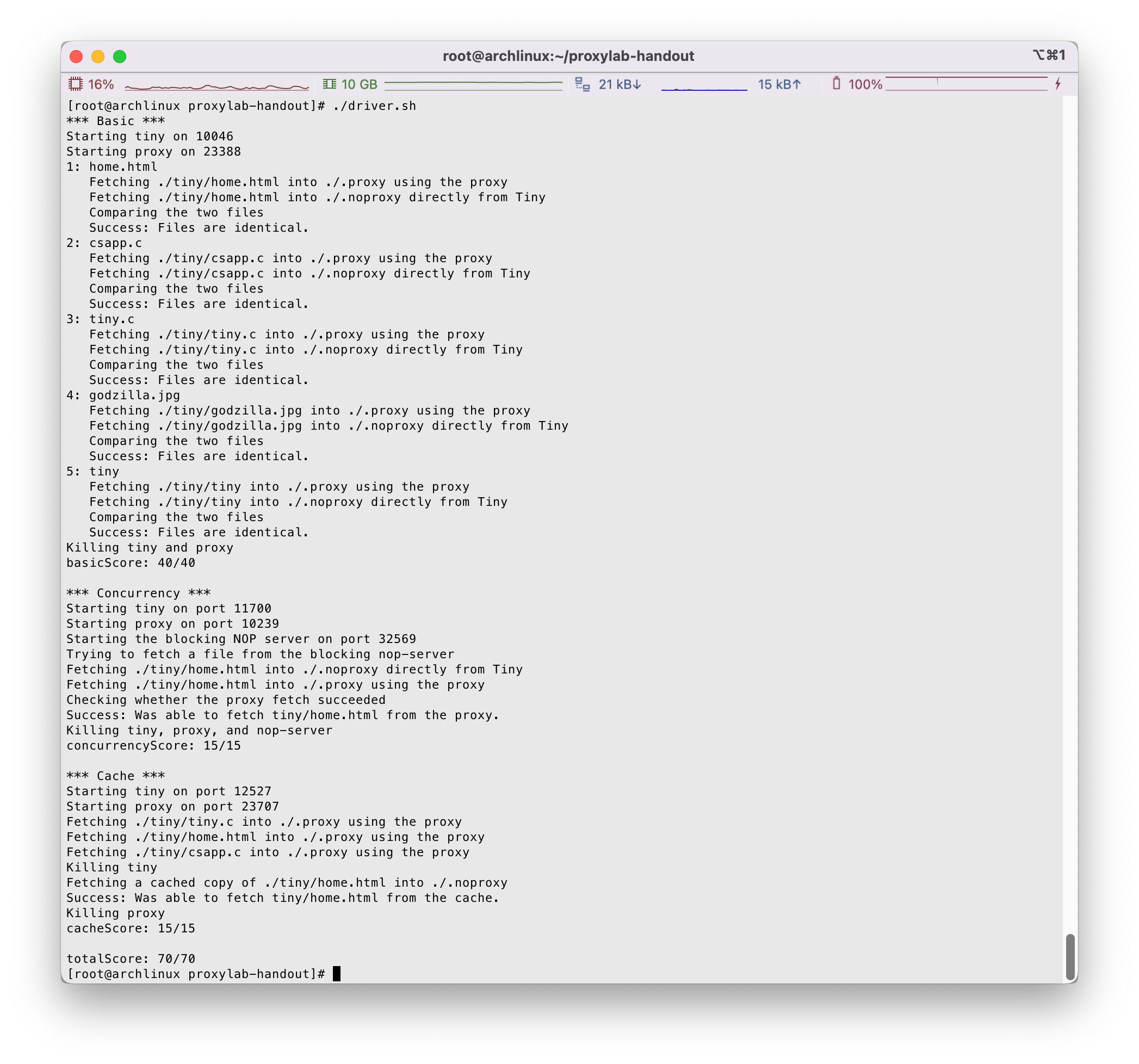
牛啊~ 70分至此全部拿下
总结
想了想,貌似也没有办法缩小整个数组的锁粒度,哪怕是分组也不行… 在读的过程中穿插写操作会对数据造成严重影响… 看来只能对LRU的缓存驱逐原则进行修改了,后续可以考虑下怎么牺牲严格的LRU原则来提升性能…
至此,CS:APP的所有Lab都做完了,完结撒花~










